原链接:https://zhuanlan.zhihu.com/p/21576354
一、三大件,你们还记得吗?
A通道里的三大件:数据清洗、数据分析、数据可视化
三大件今天暂时还讲不了,我们需要一点入门的预备知识。
接下来要做的,则是实践标题中的内容:用几分钟了解R入门知识。
二、首先,你得保证你的电脑里已经安装了R(这么简单的问题不用我再讲了吧。。)
还没装的点这里去下载!!!!
还有,R studio也必须安装。这是目前我感觉最好用的R用户界面,不装后悔,不装不是中国人,13亿人都装了你还在等什么。(点进去选择Download Rstidio Desktop)
三、R入门知识到底有哪些东西?
我总结成以下四个标题:
命令行,数据对象,函数(function),par
先记住这四个名字,本篇文章所有东西将围绕他们展开。
其他所有的东西,我觉得都不是入门必须。虽然它们很有用,但它们不是必须。
下面开始一个个讲。
四、命令行
R采用的是命令行输入界面,也就是我们常说的写代码。代码大概长这样:
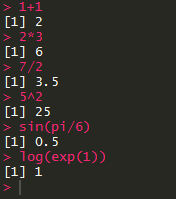 “>”之后就是光标,你可以向里面输入数字、计算式,也可以输入函数和变量,或者一切R能听懂的语言。R都会热情地给你反馈。
“>”之后就是光标,你可以向里面输入数字、计算式,也可以输入函数和变量,或者一切R能听懂的语言。R都会热情地给你反馈。
当你安装好R和Rstudio之后,就可以尽情地尝(tiao)试(xi)命令行了。在Rstudio里面,命令行默认位于屏幕左下方区域,如图:
 左上区域则是代码储存窗口,你可以在里面先随便写点代码,一言不合就点击Run来运行它们。(以你们目前的实力,R应该会立马给你们报错。)
左上区域则是代码储存窗口,你可以在里面先随便写点代码,一言不合就点击Run来运行它们。(以你们目前的实力,R应该会立马给你们报错。)
命令行里面,一般会输入哪些东西?
第一种——算式,诸如1+1,3+5之类的。这种时候R完全可以当做计算器来用。(简直是废话)值得一提的是,注意看上面的图,输入1+1之后R给出的返回值是[1] 2,这里方括号里的[1]代表的是顺序,我们会在后面(数据对象)具体讲解。
第二种——调用对象。会在数据对象中讲解。
第三种——函数,函数,函数,重要的事情说三遍。命令行里99%以上的输入,都是函数,你说重要不重要?具体的,我们会在函数里面详细讲解。
五、数据对象
如果说R是一个厨房,那么数据对象就是不同的容器,锅碗瓢盆应有尽有。数据只有借由容器,才能进行清洗、加工,以及用于分析。
厨房里的锅碗瓢盆有很多种,R的数据对象也有很多种。但目前大家记住其中的三种就好:
1.碗——向量(vector)
厨房里最小的容器,一般都是碗。向量也是R里面最小、最基础的数据对象。
> c(1,2,3,4,5)
[1] 1 2 3 4 5
> c(1:20)
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
> 1:30
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
[23] 23 24 25 26 27 28 29 30
函数c()的效果,就是把括号里面的东西做成一个向量,向量的不同元素以“,”作为分隔。
而“:”的作用显而易见,1:20表示从1到20这20个数字。
注意,看代码的最后一行,开头是方括号[23]。这代表这一行从向量的第23个元素开始。回想上一节,为什么“1+1”返回值是“[1] 2”呢?就是因为向量是R里面最小的数据对象,所以1+1不得不生成只有一个元素的向量。这就好比,厨房里最小的碗也有拳头大,但为了装一颗豆子,还是要大材小用。
> x<-c(1,2,3,4) #把向量赋值给x
> y<-c(3,5,7,9)
> x #调用向量x
[1] 1 2 3 4
> y
[1] 3 5 7 9
> x[2] #调用向量x的第二个元素
[1] 2
上面的代码很重要,它进行了一个最基本也是最重要的操作:赋值。可以看做是“给容器贴标签”
方法很简单,采用“<-”符号就可以了。箭头指向标签名。上面的代码表示,有一个碗里放了四颗豆子分别叫做1、2、3、4,于是我们给这个碗贴上标签叫做“x”。另一个碗里放了四颗豆子叫做3、5、7、9,我们贴上“y”的标签。
赋值有什么作用呢?作用就是,如果没有标签,我们可能就找不到这两个碗和里面的豆子了。
赋值之后就是调用,只要输入变量名称(标签名)就能调用对应的内容(碗)。而输入变量名称+顺序号,就能调用单个元素(豆子)。如上所示
> x+y
[1] 4 7 10 13
> x%*%y
#这里“%*%”表示求两个向量的内积,然后会生成一个1*1矩阵
[,1]
[1,] 70
> x*2
[1] 2 4 6 8
向量之间也可以直接运算,方法和初高中数学里学的向量运算差不多,类似于上面那些。大家可以自己实验一下。不明白的,你们就自己百度去吧。(不负责任的我啊。。)
2.多功能橱柜——列表(list)
列表是一个神奇的数据对象,如同厨房里的多功能橱柜。
橱柜里有很多格子,每个格子都能盛放很多东西。列表也是这样,列表里可以单独分出很多格子,每个格子都能盛放一个单独的数据对象(可以是向量、矩阵,甚至是另外一个列表)。
而橱柜的格子也需要编号,编号方法略有不同。看下面的例子:
> list1<-list(x,y,c(3,3))
> list1
[[1]]
[1] 1 2 3 4
[[2]]
[1] 3 5 7 9
[[3]]
[1] 3 3
通过list()函数,我们定义了一个叫做list1的列表(多功能橱柜)。这里面现在有三个格子,非常清晰地显示在代码中,它们的编号方式是两个方括号[[1]]。
聪明的读者应该也能想到,列表及其中的元素同样也能进行调用。
> list1[[1]]
#调用list1中的第一个“格子”
[1] 1 2 3 4
> list1[[1]][3] #调用list1第一个“格子”里的第三个元素。
[1] 3
三个格子中,每个格子装一个向量。
列表的作用是什么?等到下一章,你们就知道了。
3.炒锅——数据框(data frame)
数据框是R里面最重要的数据对象!数据框是R里面最重要的数据对象!数据框是R里面最重要的数据对象!重要的事情说三遍!
炒锅在厨房里无疑也是最重要的。菜品的完成,大部分时间都依赖炒锅。我们数据分析的过程中,数据大部分时间也是呆在数据框里面的。
但数据框这个名字有点抽象。其实,他就是二维表。或者再通俗一点,就是我们天天见到的表格。在R里面大概长成下面这样:
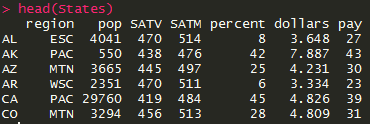 States是一个数据框(表格),head()函数帮助我们调用了这个表格的前五行。
States是一个数据框(表格),head()函数帮助我们调用了这个表格的前五行。
我们能看到,这个表格包括美国各个州的人口、收入等等数据。虽然没有画线,但是还是能看得出典型的行标签、列标签和数据内容的。显然,这就是我们日常处理数据的时候,最喜欢用的方法:表格。
数据框的赋值通过函数data.frame()完成。很简单,日后提到的时候,一看就懂。
表格里的内容当然也可以调用,但似乎没有前两个那么直观。方法如下:
> States$pop
#数据框名后加上美元符号"$",接列标签名,就能调用列。输出结果是一个向量
[1] 4041 550 3665 2351 29760 3294 3287 666 607 12938 6478
[12] 1108 1007 11431 5544 2777 2478 3685 4220 1228 4781 6016
[23] 9295 4375 2573 5117 799 1578 1202 1109 7730 1515 17990
[34] 6629 639 10847 3146 2842 11882 1003 3487 696 4877 16987
[45] 1723 563 6187 4867 1793 4892 454
> States[2]
#用数字也可以调用列,但出来的则是一个砍掉了其他所有列的数据框
pop
AL 4041
AK 550
AZ 3665
AR 2351
CA 29760
CO 3294
日常操作中,我们一般会用attach()来锁定一个数据框。之后,只要直接输入列名称,就能调用列了。如下。
> attach(States)
> pop
#效果相当于语句States$pop
[1] 4041 550 3665 2351 29760 3294 3287 666 607 12938 6478
[12] 1108 1007 11431 5544 2777 2478 3685 4220 1228 4781 6016
[23] 9295 4375 2573 5117 799 1578 1202 1109 7730 1515 17990
[34] 6629 639 10847 3146 2842 11882 1003 3487 696 4877 16987
[45] 1723 563 6187 4867 1793 4892 454
4.数据对象小结
R的数据对象有很多种,我们现在先记住其中的三种。
碗——向量(vector)
多功能橱柜——列表(list)
炒锅——数据框(data frame)
并且,记住他们的结构,赋值方法,以及调用方法。
其他的数据对象包括矩阵(matrix),数组(array),时间序列(ts)等等,以后再谈。
值得一提的是,千万不要把数据对象和数据类型搞混。前者就是我们刚刚讲的容器的种类,而后者则是豆子的种类。
数据类型包括数值型(numeric),字符型(character),缺失值(NA)等等,一看就懂。可以通过mode()函数检测数据类型:
> x<-c(1,2,3.3,pi)
#这些都是数字,当然是数值型
> mode(x)
[1] "numeric"
> y<-c("thanks","for","dian","zan")
#双引号或单引号括起来的任何东西,都是字符型
> mode(y)
[1] "character"
> z<-c(1,2,3,"oops")
#然而一个向量不能同时存在数值和字符元素。如果你加了一个字符型进去,整个向量的所有元素都会自动加上双引号,变成字符型。
> mode(z)
[1] "character"
美好的一天,再写下去可能看官们就要睡着了。(你们是不是已经忘掉了标题中的“几分钟”呢?哈哈哈哈)