这周学的是Hadoop的Mapreduce部分。
MapReduce思想在生活中处处可见,或多或少都曾经接触过这种思想。MapReduce的思想核心是“分而治之”,适用于大量复杂的、大规模的任务处理场景。把复杂的任务分解成若干个“简单的任务”来并行处理,可以进行拆分的前提是这些小任务可以并行计算,彼此之间没有依赖关系。MapReduce运行在yarn集群,ResourceManager和NodeManager这两个阶段合起来正是MapReduce思想的体现。
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop集群上。MapReduce设计并提供了统一的计算框架,隐藏了绝大多数系统层面的处理细节,提供了一个抽象和高层的编程接口和框架。MapReduce定义了Map和Reduce两个抽象的编程接口,由用户去编程实现Map和Reduce,MapReduce处理的数据类型是<key,value>键值对。
Map:(k1;v1)->[(k2;v2)]
Reduce:(k2;[v2])->[(k3;v3)]
一个完整的mapreduce程序在分布式运行时有三类事例进程:MRAppMaster(负责整个程序的过程调度及状态协调)、MapTask(负责map阶段的整个数据处理流程)、ReduceTask(负责reduce阶段的整个阶段处理流程)。
MapReduce的开发一共有八个步骤,其中Map阶段分为2个步骤,Shuffle阶段4个步骤、Reduce阶段分为2个步骤。
Map阶段2个步骤:
1.设置InputFormat类,将数据切分为Key-Value(K1和V1)对,输入到第二步
2.自定义Map逻辑,将第一步的结果转换成另外的Key-Value(K2和V2)对,输出结果
Shuffle阶段4个步骤:
3.对输出的Key-Value对进行分区
4.对不同分区的数据按照相同的Key排序
5.(可选)对分组过的数据初步规约,降低数据的网络拷贝
6.对数据进行分组,相同Key的Value放入一个集合中
Reduce阶段2个步骤:
7.对移个Map任务的结果进行排序以及合并,编写Reduce函数实现自己的逻辑,对输入的Key-Value进行处理,转为新的Key-Value (K3和V3)输出
8.设置OutputFormat处理并保存Reduce输出的Key-Value数据
另外,还学习了一个WordCount的MapReduce案例。
在MapReduce中,通过我们指定分区,会将同一个分区的数据发送到同一个Reduce当中进行处理,其中,有相同类型的数据,有共性的数据,放在一起处理。
分区代码的编写步骤:


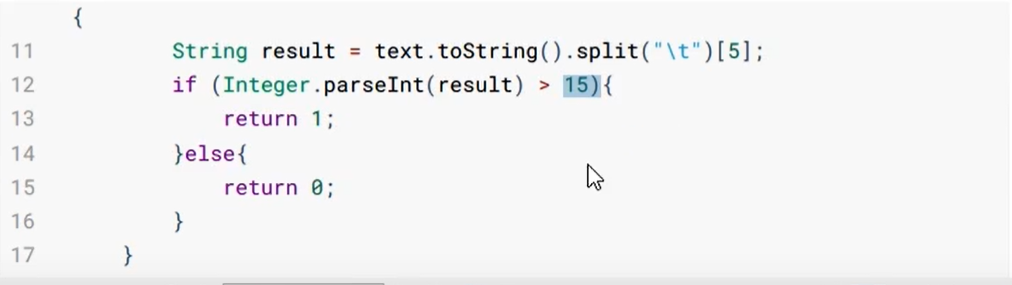

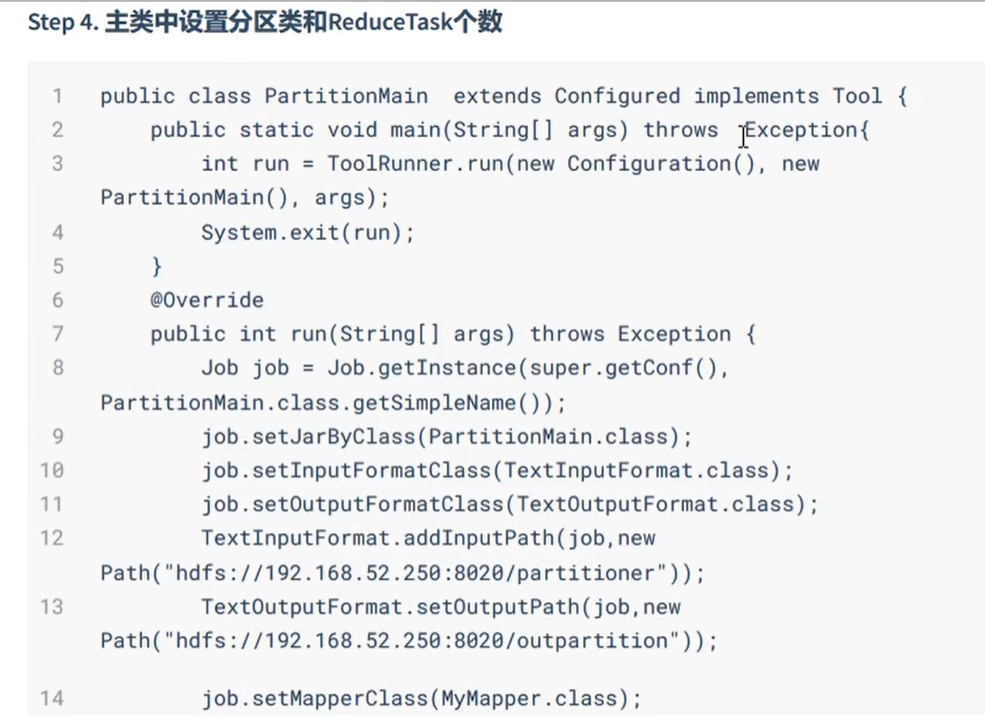

然后,就是学习制作了一个MapReduce的一个事例计时器。