引言:本篇文章以笔者亲身实践过程来总结和记录Redis的主从复制、哨兵故障转移、集群等内容,避免单纯的理论性知识分享,以具体操作实践来引导来学习的朋友们,希望为大家提供有力的支持与帮助。
文章目录:
1 Redis环境搭建
Redis作为NoSQL体系中的最具有代表性的数据库之一,是一款高性能的key-value数据库,概况的讲具有以下特点:
- 支持数据持久化,可将内存数据保存到硬盘,重启后将从硬盘中再次加载到内容
- 支持数据类型String、List、Set、Zset、Hash、HyperLogLog 。
- 支持数据备份、(Master-Slave)主从复制、(Cluster)集群模式
- 读取速度高达8万-10万次每秒。
- 支持publish/subscribe,key过期等特性、支持事务。
1.1 下载Redis
官网地址:https://redis.io/
中文官网地址:http://www.redis.cn
下载地址:http://download.redis.io/releases/
1.2 安装Redis
下载版本redis-4.0.11.tar.gz,此版本是需要先编译、再安装。
解压:tar -zxvf redis-4.0.11.tar.gz
切换目录:cd redis-4.0.11
编译安装:make install PREFIX=/usr/local/redis (记住可不能写成小写prefix)
完整的步骤命令:
[root@hadoop01 modules]# tar -zxvf redis-4.0.11.tar.gz [root@hadoop01 modules]# cd redis-4.0.11 [root@hadoop01 modules]# make install PREFIX=/usr/local/redis
安装成功后在/usr/local/目录下有redis:
进入redis目录中,会看到redis的一些操作命令工具:

|
Redis操作命令工具 |
|
|
redis-server |
启动redis服务 |
|
redis-cli |
进入redis命令客户端 |
|
redis-benchmark |
性能测试的工具 |
|
redis-check-aof |
aof文件进行检查的工具 |
|
redis-check-dump |
rdb文件进行检查的工具 |
|
redis-sentinel |
启动哨兵监控服务 |
1.3 启动Redis
启动命令:./redis-server redis.conf
[root@hadoop01 bin]# ./redis-server redis.conf
启动成功后控制台信息:
2 Redis主从复制
Redis的持久化保证了Redis重启也不会丢失数据,因为Redis在存储时会将内存中的数据存储到硬盘上,当重启后会再次将硬盘上的数据加载到内存中;但是如果硬盘有损坏的话,可能会照成数据丢失,那么通过Redis的主从复制可以避免这种单点故障。如图:
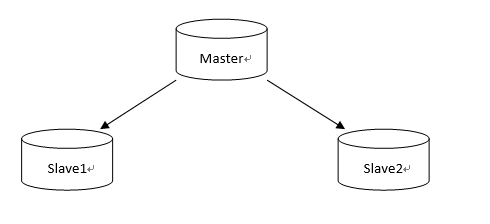
Redis主从模式
说明:Master中的数据有两个副本Slave1和Slave2,其中任何一台Redis宕机,其他两台任然能继续提供服务。Master和Slave的数据实时保持同步,当Master写入数据后会复制到Slave1和Slave2。
2.1 配置主从
这里我们采用一主两从的模式,配备3台机器,分别安装好Redis,具体分配入下表:
|
服务类型 |
服务器角色 |
IP |
端口 |
|
Redis |
Master |
192.168.100.129 |
6379 |
|
Redis |
Slave1 |
192.168.100.130 |
6379 |
|
Redis |
Slave2 |
192.168.100.131 |
6379 |
Master配置文件redis.conf:
redis服务器可以跨网络访问,将默认的127.0.0.1修改为0.0.0.0
bind 0.0.0.0
设定Redis密码
# requirepass foobared requirepass redis123
Slave配置文件redis.conf:(两台Slave设置相同)
redis服务器可以跨网络访问,将默认的127.0.0.1修改为0.0.0.0
bind 0.0.0.0
设定Redis密码
# requirepass foobared requirepass redis123
设置Slave登录 Master的密码,此处为Master的密码
# masterauth <master-password> masterauth redis123
设置所属的主机的IP和端口
# slaveof <masterip> <masterport> slaveof 192.168.100.129 6379
2.2 启动主从模式
启动Master:
启动slave1:

从控制台信息中可以看到,Slave1成功连接Maser-192.168.100.129,并接收到Master的同步数据。
启动slave2:
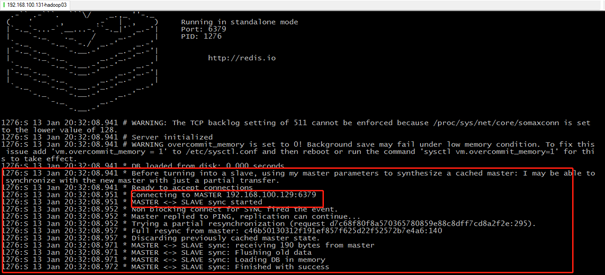
同样,Slave2也成功连接Maser-192.168.100.129,并接收到Master的同步数据。
查看Master:
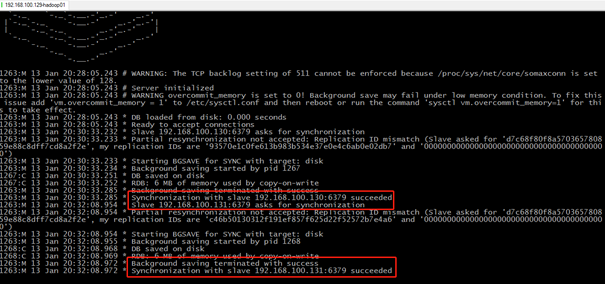
再回头看一下Master,当两台Slave都启动之后,控制台信息告诉我们Slave1-192.168.100.130、Slave2-192.168.100.131均同步成功。
2.3 验证主从复制同步
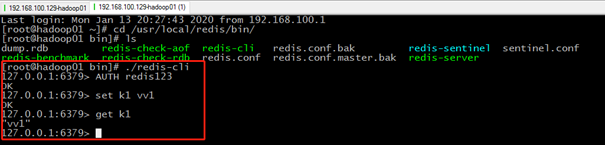
Master中写入k1
[root@hadoop01 ~]# cd /usr/local/redis/bin/ [root@hadoop01 bin]# ./redis-cli 127.0.0.1:6379> AUTH redis123 OK 127.0.0.1:6379> set k1 vv1 OK 127.0.0.1:6379> get k1 "vv1" 127.0.0.1:6379>
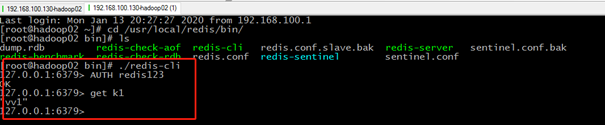
Slave1中读取k1
[root@hadoop02 ~]# cd /usr/local/redis/bin/ [root@hadoop02 bin]# ./redis-cli 127.0.0.1:6379> AUTH redis123 OK 127.0.0.1:6379> set k1 vv1 OK 127.0.0.1:6379> get k1 "vv1" 127.0.0.1:6379>
Slave2中读取k1
[root@hadoop03 ~]# cd /usr/local/redis/bin/ [root@hadoop03 bin]# ./redis-cli 127.0.0.1:6379> AUTH redis123 OK 127.0.0.1:6379> set k1 vv1 OK 127.0.0.1:6379> get k1 "vv1" 127.0.0.1:6379>
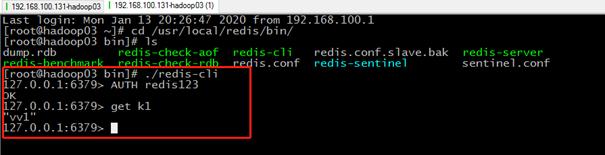
2.4 优缺点
优点:主从结构模式实现了读写分离,较单机又读又写来说,提高读写操作的性能。
缺点:当其中的任何一台Master或Slave宕机,无法实现自动处理故障。利用Redis-Sentinel哨兵模式可以完美的进行自动故障转移。
3 Redis哨兵模式
3.1 Redis Sentinel介绍
Redis Sentinel是Redis HA 的实现方案,Sentinel是一个可以对Redis进行监控、通知、故障转移的工具。
3.2 哨兵模式配置
本例中架构模式设置了三台虚拟机,分别为一台作为Redis主节点,另外两台作为Redis从节点;其中开启三个Redis Sentinel来监控各节点的状态,在其中的主节点宕机后,会自动的故障转移,从另外两台从节点中选出一个作为主节点,替代旧的主节点的工作。具体机器的分配如下表:
|
服务类型 |
服务器角色 |
IP |
端口 |
|
Redis |
Master |
192.168.100.129 |
6379 |
|
Redis |
Slave1 |
192.168.100.130 |
6379 |
|
Redis |
Slave2 |
192.168.100.131 |
6379 |
|
Sentinel |
- |
192.168.100.129 |
26379 |
|
Sentinel |
- |
192.168.100.130 |
26379 |
|
Sentinel |
- |
192.168.100.131 |
26379 |
Master主节点配置文件redis.conf:
bind 0.0.0.0 //可以跨网络访问 protected-mode no //默认为yes,只允许127.0.0.1访问 requirepass redis123 //Redis的密码 masterauth redis123 //主节点的密码,此处可以不设置;设置的好处是当Master宕机后,Sentinel会自动完成故障转移,再次启动旧的Msater后,它会以Slave的身份自动连接新的Master。
Slave从节点配置文件redis.conf:
bind 0.0.0.0 protected-mode no requirepass redis123 masterauth redis123 slaveof 192.168.100.129 6379 //设置所属的Master的IP和端口
哨兵配置文件sentinel.conf,三个哨兵节点相同:
protected-mode no //保护模式 sentinel monitor mymaster 192.168.100.129 6379 2 sentinel auth-pass mymaster redis123 //master的密码 sentinel down-after-milliseconds mymaster 10000 //节点认为主观下线的有效时间 sentinel failover-timeout mymaster 60000 //故障转移超时时间*毫秒 sentinel parallel-syncs mymaster 1 //设定同步新主机的节点数
特别注意:一定要将配置文件中redis.conf和sentinel.conf的protected-mode设置为no,否则哨兵无法正常的完成故障转移切换新的主节点
哨兵模式下的一些配置说明:
|
配置项 |
参数 |
作用 |
|
Port |
整数 |
哨兵进程端口 |
|
Dir |
文件目录 |
哨兵进程服务文件夹,默认为/tmp,要保证有写权限 |
|
sentinel down-after-milliseconds <master-name> <milliseconds> |
<服务名称><毫秒数(整数)> |
指定哨兵在监测Redis服务时,当Redis服务在一个亳秒数内都无法回答时,单个哨兵认为的主观下线时间,默认为 30000(30秒) |
|
sentinel parallel-syncs <master-name> <numslaves> |
<服务名称><服务器数(整数)> |
指定可以有多少 Redis 服务同步新的主机,一般而言,这个数字越 小同步时间就越长,而越大,则对网络资源要求则越高 |
|
sentinel failover-timeout <master-name> <milliseconds> |
<服务名称><亳秒数(整数)> |
指定在故障切换允许的亳秒数,当超过这个亳秒数的时候,就认为 切换故障失败,默认为 3 分钟 |
|
sentinel notification-script <master-name> <script-path> |
<服务名称><脚本路径> |
指定 sentinel 检测到该监控的 redis 实例指向的实例异常时,调用的 报警脚本。该配置项可选,比较常用 |
3.3 启动哨兵监控
按先Master后Slave顺序启动各节点:
./redis-server redis.conf
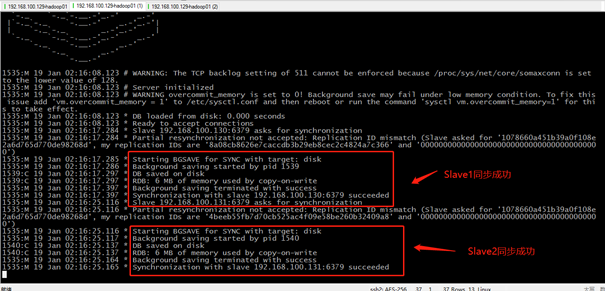
启动3个哨兵监控:
./redis-sentinel sentinel.conf
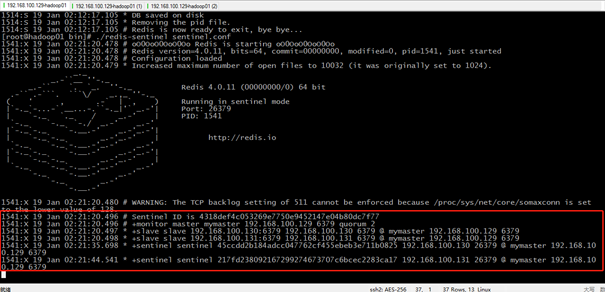
解释一下这些信息的意思:
Sentinel ID is 4318def4c053269e7750e9452147e04b80dc7f77 //哨兵的ID标识 +monitor master mymaster 192.168.100.129 6379 quorum 2 //增加了对Master -192.168.100.129的监控, 主观下线的判定数量为2或大于2。 +slave slave 192.168.100.130:6379 192.168.100.130 6379 @ mymaster 192.168.100.129 6379 //增加了对slave的监控,后面为该slave-192.168.100.130的信息 +slave slave 192.168.100.131:6379 192.168.100.131 6379 @ mymaster 192.168.100.129 6379 //增加了对slave的监控,后面为该slave-192.168.100.131的信息 +sentinel sentinel 45ccdd2b184adcc047762cf455ebeb3e711b0825 192.168.100.130 26379 @ mymaster 192.168.100.129 6379 //增加了哨兵节点192.168.100.130,标识ID,信息显示其对主节点192.168.100.129的监控。 +sentinel sentinel 217fd238092167299274673707c6bcec2283ca17 192.168.100.131 26379 @ mymaster 192.168.100.129 6379 //增加了哨兵节点192.168.100.131,标识ID,信息显示其对主节点192.168.100.129的监控。
3.4 验证哨兵的故障转移能力
为了验证哨兵模式下自动故障转移的能力,先将Master节点断掉,模拟宕机。然后查看一下Slave1-192.168.100.130节点的情况:出现连接Master失败,随后以Master的身份与Slave2-192.168.100.131同步成功。

以上说明哨兵自动完成故障转移,将Slave1-192.168.100.130的节点选举为新的Master节点,这是刚刚当选主节点Master-192.168.100.130的信息,经过这样一个故障迁移的过程:
旧Master主观下线—>投票->旧Master客观下线—>新Master产生—>通知所有节点
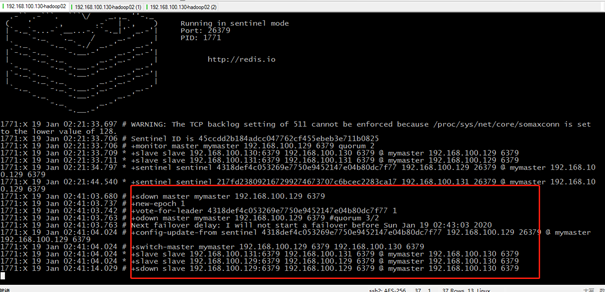
查看下Slave1-192.168.100.130的信息,发现当前节点的角色已经变成Master。
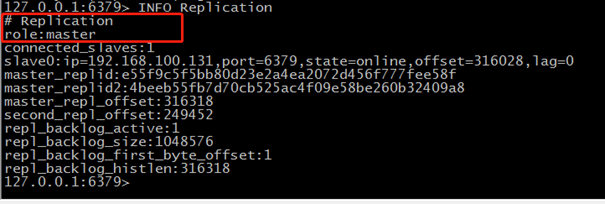
接下来重启一下刚刚宕机的那台旧的Master节点,发现它成功同步连接到新的Master-192.168.100.130,此时它是作为一个Slave的节点存在。
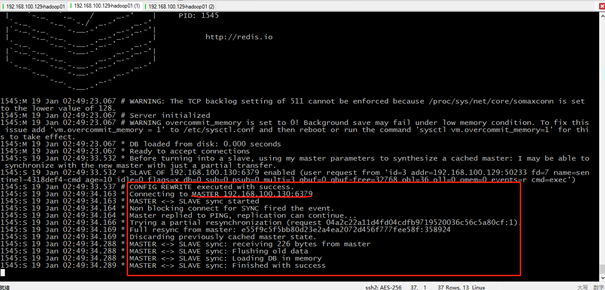
可以查看一下节点192.168.100.129的信息,发现它已经变成一个Slave的角色了。
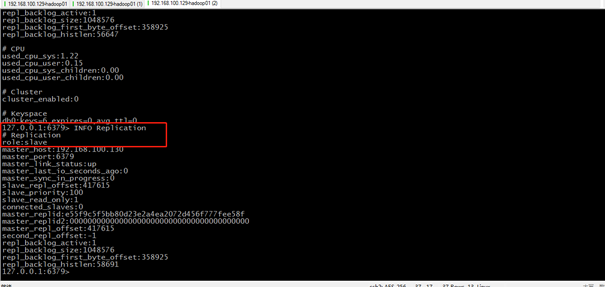
3.5 优缺点
优点:读写分离,解决单点故障,自动完成故障转移。
缺点: 在读写高并发状况下,主节点单点写入,无法实现单点扩容,虽然只解决高可用的问题,不能完美的体现高可用的性能。解决这一问题,就要引入Redis Cluster集群来解决。
4 Redis-Cluster集群
Redis的集群需要通过集群管理脚本redis-trib.rb来运行,而Redis5之前的版本需要依赖Ruby环境,我们当前版本是Redis4,所以需要安装Ruby。
4.1 安装Ruby
yum install ruby //安装ruby,为了可以运行redis-trib.rb
yum install rubygems //安装gem工具包
gem install redis //安装ruby与redis的接口程序
gem是管理Ruby库和程序的标准包,通过rubygems(https://rubygems.org/)源来查找、安装、升级、卸载软件包,非常方便。

4.2 安装Redis Cluster集群
Redis Cluster最少需要3个节点,1个Master,2个Slave。例用两台虚拟机模式6个节点:一台机器3个节点,创建出3个Master、3个Slave。所有节点在开始并不指定具体的Master-Slave关系,而是在创建完成集群后会指定哪些节点是Master,哪些节点是Slave。
|
服务类型 |
IP |
端口 |
|
Redis-Node |
192.168.100.129 |
7000 |
|
Redis-Node |
192.168.100.129 |
7001 |
|
Redis-Node |
192.168.100.129 |
7002 |
|
Redis-Node |
192.168.100.130 |
7001 |
|
Redis-Node |
192.168.100.130 |
7002 |
|
Redis-Node |
192.168.100.130 |
7003 |
4.3 创建Redis节点
1、在IP为192.168.100.129的机器上/opt/modules/redis-4.0.11目录下创建redis-cluster目录:
[root@hadoop01 redis-4.0.11]# mkdir redis-cluster
在redis-cluster目录下创建名为7000、7001、7002的目录
[root@hadoop01 redis-4.0.11]# cd redis-cluster/ [root@hadoop01 redis-cluster]# mkdir 7000 7001 7002
2、将redis.conf拷贝到三个目录中。
[root@hadoop01 redis-cluster]# cp ../redis.conf ./7000/ [root@hadoop01 redis-cluster]# cp ../redis.conf ./7001/ [root@hadoop01 redis-cluster]# cp ../redis.conf ./7002/
指定数据文件存放目录:
[root@hadoop01 opt]# mkdir redis-data/
3、修改节点配置文件redis.conf:
目录文件:/opt/modules/redis-4.0.11/redis-cluster/7000/redis.conf
port 7000 //端口 7000、7001、7002 bind 0.0.0.0 //默认127.0.0.1,设置可以跨网络访问 daemonize yes //后台运行 pidfile /var/run/redis_7000.pid cluster-enabled yes //开启集群模式 cluster-config-file /opt/modules/redis-4.0.11/redis-cluster/7000/nodes-7000.conf //集群配置,配置文件首次启动自动生成 cluster-node-timeout 15000 //请求超时时间*毫秒,默认15秒 appendonly yes //aof日志 dir /opt/redis-data/ 数据文件的目录
同样配置:
vim /opt/modules/redis-4.0.11/redis-cluster/7001/redis.conf vim /opt/modules/redis-4.0.11/redis-cluster/7002/redis.conf
在另一台机器192.168.100.130上重复以上的3个步骤,以完成节点7000、7001、7002的配置。
4.4 启动集群节点
在机器192.168.100.129上执行:
[root@hadoop01 src]# redis-server ../redis-cluster/7000/redis.conf [root@hadoop01 src]# redis-server ../redis-cluster/7001/redis.conf [root@hadoop01 src]# redis-server ../redis-cluster/7002/redis.conf
在另一台机器192.168.100.130上执行:
[root@hadoop02 src]# ./redis-server ../redis-cluster/7000/redis.conf [root@hadoop02 src]# ./redis-server ../redis-cluster/7001/redis.conf [root@hadoop02 src]# ./redis-server ../redis-cluster/7002/redis.conf
4.5 检查节点运行状态
检查机器192.168.100.129 Redis节点运行:
[root@hadoop01 src]# ps -ef |grep redis root 5054 1 0 00:51 ? 00:00:00 redis-server 0.0.0.0:7000 [cluster] root 5059 1 0 00:51 ? 00:00:00 redis-server 0.0.0.0:7001 [cluster] root 5081 1 0 00:57 ? 00:00:00 redis-server 0.0.0.0:7002 [cluster] root 5088 5031 0 00:57 pts/1 00:00:00 grep redis
查看端口监听状态:
[root@hadoop01 src]# netstat -tlnp |grep redis tcp 0 0 0.0.0.0:17000 0.0.0.0:* LISTEN 5054/redis-server 0 tcp 0 0 0.0.0.0:17001 0.0.0.0:* LISTEN 5059/redis-server 0 tcp 0 0 0.0.0.0:17002 0.0.0.0:* LISTEN 5081/redis-server 0 tcp 0 0 0.0.0.0:7000 0.0.0.0:* LISTEN 5054/redis-server 0 tcp 0 0 0.0.0.0:7001 0.0.0.0:* LISTEN 5059/redis-server 0 tcp 0 0 0.0.0.0:7002 0.0.0.0:* LISTEN 5081/redis-server 0
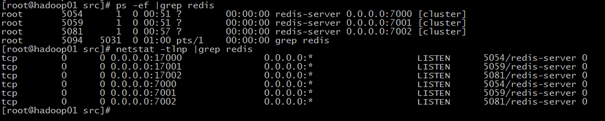
检查另一台机器192.168.100.130 Redis各节点运行状态:

4.6 创建集群
执行命令:
./redis-trib.rb create --replicas 1 192.168.100.129:7000 192.168.100.129:7001 192.168.100.129:7002 192.168.100.130:7000 192.168.100.130:7001 192.168.100.130:7002
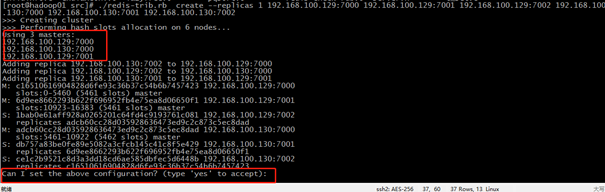
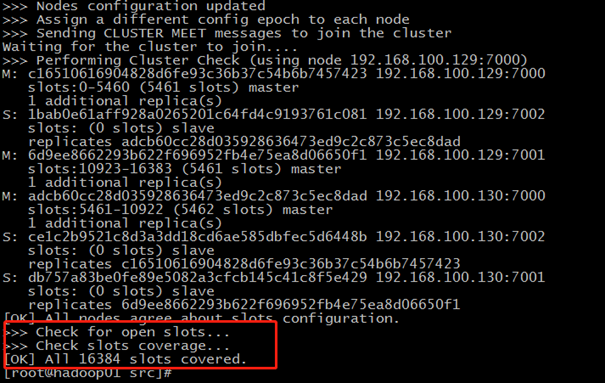
[root@hadoop01 src]# ./redis-trib.rb create --replicas 1 192.168.100.129:7000 192.168.100.129:7001 192.168.100.129:7002 192.168.100.130:7000 192.168.100.130:7001 192.168.100.130:7002 >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 192.168.100.129:7000 192.168.100.130:7000 192.168.100.129:7001 Adding replica 192.168.100.130:7002 to 192.168.100.129:7000 Adding replica 192.168.100.129:7002 to 192.168.100.130:7000 Adding replica 192.168.100.130:7001 to 192.168.100.129:7001 M: c16510616904828d6fe93c36b37c54b6b7457423 192.168.100.129:7000 slots:0-5460 (5461 slots) master M: 6d9ee8662293b622f696952fb4e75ea8d06650f1 192.168.100.129:7001 slots:10923-16383 (5461 slots) master S: 1bab0e61aff928a0265201c64fd4c9193761c081 192.168.100.129:7002 replicates adcb60cc28d035928636473ed9c2c873c5ec8dad M: adcb60cc28d035928636473ed9c2c873c5ec8dad 192.168.100.130:7000 slots:5461-10922 (5462 slots) master S: db757a83be0fe89e5082a3cfcb145c41c8f5e429 192.168.100.130:7001 replicates 6d9ee8662293b622f696952fb4e75ea8d06650f1 S: ce1c2b9521c8d3a3dd18cd6ae585dbfec5d6448b 192.168.100.130:7002 replicates c16510616904828d6fe93c36b37c54b6b7457423 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join.... >>> Performing Cluster Check (using node 192.168.100.129:7000) M: c16510616904828d6fe93c36b37c54b6b7457423 192.168.100.129:7000 slots:0-5460 (5461 slots) master 1 additional replica(s) S: 1bab0e61aff928a0265201c64fd4c9193761c081 192.168.100.129:7002 slots: (0 slots) slave replicates adcb60cc28d035928636473ed9c2c873c5ec8dad M: 6d9ee8662293b622f696952fb4e75ea8d06650f1 192.168.100.129:7001 slots:10923-16383 (5461 slots) master 1 additional replica(s) M: adcb60cc28d035928636473ed9c2c873c5ec8dad 192.168.100.130:7000 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: ce1c2b9521c8d3a3dd18cd6ae585dbfec5d6448b 192.168.100.130:7002 slots: (0 slots) slave replicates c16510616904828d6fe93c36b37c54b6b7457423 S: db757a83be0fe89e5082a3cfcb145c41c8f5e429 192.168.100.130:7001 slots: (0 slots) slave replicates 6d9ee8662293b622f696952fb4e75ea8d06650f1 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
出现下面的说明集群创建成功。
参考https://blog.csdn.net/qq_39244264/article/details/80277484
4.7 验证集群
使用客户端连接到redis集群,命令: ./redis-cli -h host -p port –c
这里我们连接192.168.100.129:7000这个节点,-c表示连接redis集群。
./redis-cli -h 192.168.100.129 -p 7000 –c
然后创建k1=v1数据写入位于192.168.100.129:7000节的槽12706位置。
创建k2=v2, 数据写入位于192.168.100.129:7000节的槽449位置。
创建k3=v3, 数据写入到本节点。
[root@hadoop03 src]# ./redis-cli -h 192.168.100.129 -p 7000 -c 192.168.100.129:7000> set k1 v1 -> Redirected to slot [12706] located at 192.168.100.129:7001 OK 192.168.100.129:7001> set k2 v2 -> Redirected to slot [449] located at 192.168.100.129:7000 OK 192.168.100.129:7000> get k1 -> Redirected to slot [12706] located at 192.168.100.129:7001 "v1" 192.168.100.129:7001> get k2 -> Redirected to slot [449] located at 192.168.100.129:7000 "v2" 192.168.100.129:7000> set k3 v3 OK 192.168.100.129:7000> get k3 "v3"
4.8 Redis集群常用命令
//集群(cluster)
CLUSTER INFO 打印集群的信息
CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息。
//节点(node)
CLUSTER MEET <ip> <port> 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的节点。
CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点。
CLUSTER REPLICATE <node_id> 将当前节点设置为 node_id 指定的节点的从节点。
CLUSTER SAVECONFIG 将节点的配置文件保存到硬盘里面。
//槽(slot)
CLUSTER ADDSLOTS <slot> [slot ...] 将一个或多个槽(slot)指派(assign)给当前节点。
CLUSTER DELSLOTS <slot> [slot ...] 移除一个或多个槽对当前节点的指派。
CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
CLUSTER SETSLOT <slot> NODE <node_id> 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
CLUSTER SETSLOT <slot> MIGRATING <node_id> 将本节点的槽 slot 迁移到 node_id 指定的节点中。
CLUSTER SETSLOT <slot> IMPORTING <node_id> 从 node_id 指定的节点中导入槽 slot 到本节点。
CLUSTER SETSLOT <slot> STABLE 取消对槽 slot 的导入(import)或者迁移(migrate)。
//键 (key)
CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。
CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的键值对数量。
CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键。
4.9 Redis集群原理
Redis Cluster在设计中的每个节点都是平等的,每个节点都保存各自的数据和整个集群的状态。每个节点和其他节点都保持连接,这就保证了我们只需要连接集群中的任何一个节点,就可以获取到其他任何节点上存放的数据了。
Redis Cluster没有使用传统的哈希来存储数据,而是采用一种叫做哈希槽(hash slot)的存储方式来分配的,共分配了16348个哈希槽。当 set一个key时,会用CRC16算法取模得到所属的slot,然后将这个key分配到哈希槽区间的节点上,算法为:CRC16(key)% 16348。所以刚刚在例子中set 和get k1、k2的时候,跳转到了192.168.100.129:7001节点上。
Redis Cluster会把数据存在一个Master节点,然后这个Master节点和其他的Slave节点进行数据同步。当Master宕机后,会选举一个Slave替代Master。
参考:
https://blog.csdn.net/qq_39244264/article/details/80277484
https://www.cnblogs.com/wuxl360/p/5920330.html