迭代器(Iterator):
迭代器(Iterator)不是一个容器,而是提供了按顺序访问容器元素的数据结构。
迭代器包含两个基本操作:next和hasNext。next可以返回迭代器的下一个元素,hasNext用于检测是否还有下一个元素

Iterable有两个方法返回迭代器:grouped和sliding。然而,这些迭代器返回的不是单个元素,而是原容器(collection)元素的全部子序列。这些最大的子序列作为参数传给这些方法。grouped方法返回元素的增量分块,sliding方法生成一个滑动元素的窗口。两者之间的差异通过REPL的作用能够清楚看出
前面的解释或许云里雾里,结合下面代码示例就清楚了
grouped 移动了三个,但是sliding只移动了一个

数组(Array):
数组:一种可变的、可索引的、元素具有相同类型的数据集合。
Scala提供了参数化类型的通用数组类Array[T],其中T可以是任意的Scala类型,可以通过显式指定类型或者通过隐式推断来实例化一个数组。


可以不给出数组类型,Scala会自动根据提供的初始化数据来推断出数组的类型

多维数组的创建:调用Array的ofDim方法

![]()
采用Array类型定义的数组属于定长数组,其数组长度在初始化后就不能改变。如果要定义变长数组,需要使用ArrayBuffer参数类型,其位于包scala.collection.mutable中。
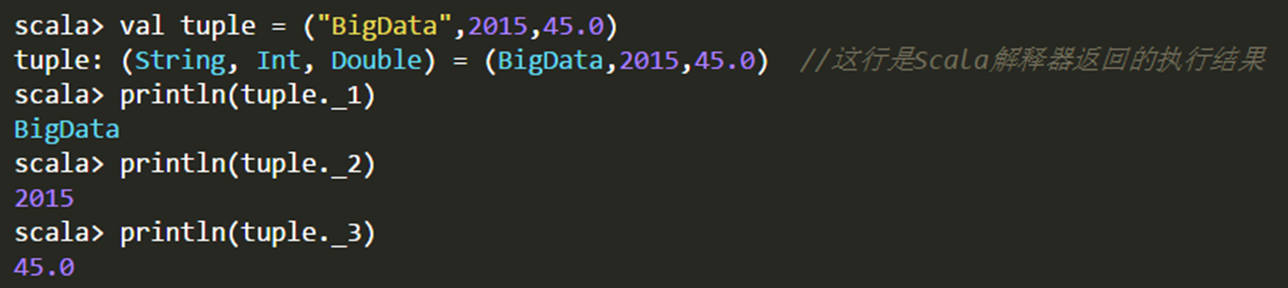
元组(Tuple):
元组是对多个不同类型对象的一种简单封装。定义元组最简单的方法就是把多个元素用逗号分开并用圆括号包围起来。
使用下划线“_”加上从1开始的索引值,来访问元组的元素。