Large states in our workload makes it infeasible to maintain everything in memory. Thus, we rely heavily on the RocksDB state backend to manage our growing hot data for processing events.
RocksDB is a high-performance storage engine, but tuning it for different workloads is not hassle-free. With dozens of options, finding the right ones to tune is as challenging as tuning them. Flink comes with several predefined option sets for different storage device types. It works reasonably well for simple workloads. Anything else may require further tuning. RocksDB’s Tuning Guide is a good place to start.
Before going into the parameters, it is worth understanding how RocksDB works because the design highly influences the tuning.
RocksDB is a persistent key-value store based on LevelDB from Google. The foundational data structure in RocksDB is Log-structured merge-tree (or LSM tree). It caches writes in memory (Memtable) until they reach a certain size, then it flushes them to fixed-size files on disk (SSTable). Once written, the files are immutable, which is one of the reasons LSM trees are fast for writes. As files on disk accumulate, they get compacted into bigger files by merging the smaller files together and removing any duplicates. The compaction process continues until it reaches the max set level, then the files stay unchanged. Because writes are always-append operations in memory, they are super fast. It does not update the previous versions of the same key in the persisted files. Compaction takes care of removing the older versions. RocksDB is an example of the tradeoff between space and speed — its fast writes come at the cost of greater storage demands. RocksDB operation is described in the diagram below.
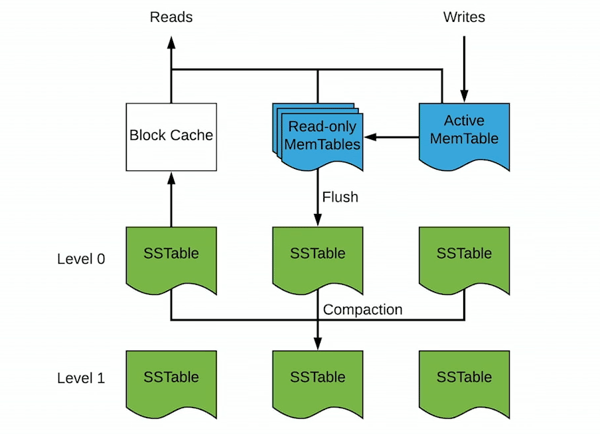
As described above, RocksDB is optimized for writes without sacrificing much read performance. If a read accesses a recently written key, it is highly likely that it still exists in the Memtables, which can be serviced without going to disk. This is perfect for workloads with a Zipfian distribution, which covers a plethora of real-world use cases such as a tweet going viral.
With writes and reads accessing mostly the recent data, our goal is to let them stay in memory as much as possible without using up all the memory on the server. The following parameters are worth tuning:
- Block cache size: When uncompressed blocks are read from SSTables, they are cached in memory. The amount of data that can be stored before eviction policies apply is determined by the block cache size. The bigger the better.
- Write buffer size: How big can Memtable get before it is frozen. Generally, the bigger the better. The tradeoff is that big write buffer takes more memory and longer to flush to disk and to recover.
- Write buffer number: How many Memtables to keep before flushing to SSTable. Generally, the bigger the better. Similarly, the tradeoff is that too many write buffers take up more memory and longer to flush to disk.
- Minimum write buffers to merge: If most recently written keys are frequently changed, it is better to only flush the latest version to SSTable. This parameter controls how many Memtables it will try to merge before flushing to SSTable. It should be less than the write buffer number. A suggested value is 2. If the number is too big, it takes longer to merge buffers and there is less chance of duplicate keys in that many buffers.
The list above is far from being exhaustive, but tuning them correctly can have a big impact on performance. Please refer to RocksDB’s Tuning Guide for more details on these parameters. Figuring out the optimal combination of values for all of them is an art in itself.
The challenge in finding the right values lies in the balance between write performance, read performance, disk performance, recovery time, and available memory. Setting the values too high for the block cache and write buffers risk running out of memory, which kills the job. If the values are too low, it may incur much higher disk IOPs and slow down throughput when saturating your storage hardware capacity.
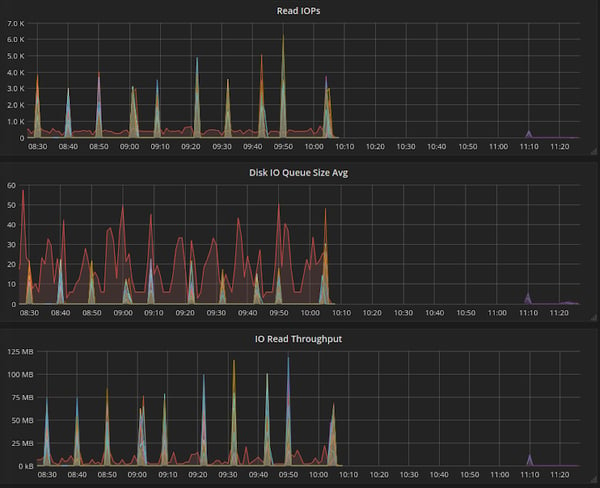
Prior to tuning the RocksDB parameters, our Flink job had high disk read IOPs and throughput, occasionally hitting as high as 9,000 IOPs. After the tuning, the disk read IOPs are mostly in the low hundreds and only spike up to 1,000 IOPs
during RocksDB compactions, which is expected.
Flink creates a RocksDB instance for each stateful operator sub-task, each has its own block cache and write buffers. This means that the total amount of memory that can be used by RocksDB is not a function of the number of TaskManagers, but the sum of all stateful operator parallelisms. This long-standing ticket shows how challenging RocksDB memory capacity planning is in Flink. The best way to find out is to use a representative workload to test the job with saturated block caches and write buffers.
Another consequence of per sub-task RocksDB instances is that the TaskManager process may use a large amount of open file descriptors. Running out of file descriptors at runtime is a fatal error, so it is recommended to set the process file descriptor limit higher than needed then dial back after benchmarking or even unlimited if there are a lot of stateful operators in the job.