Python函数三玄
《主题:多任务》
【一】:多线程:
特点:
# 线程的并发是利用cpu上下文的切换(是并发,不是并行)
# 多线程执行的顺序是无序的
# 多线程共享全局变量
# 线程是继承在进程里的,没有进程就没有线程
# GIL全局解释器锁
# 只要在进行耗时的IO操作的时候,能释放GIL,所以只要在IO密集型的代码里,用多线程就很合适
# 无序的,并发的
1.无序性
import threading
def test(n):
time.sleep(1)
print('task',n)
for i in range(10):
t = threading.Thread(target=test,args=('t_%s' % i,)) #注意,参数args后接的是一个元组,当只有一个参数时,要加一个逗号,否则运行会报错
t.start()
》》
task t_0
task t_1
task t_4
task t_3
task t_2
task t_5
task t_7
task t_9
task t_8
task t_6
》》
2.共享全局变量
import threading
num=0
def test1():
global num #局部变量只能使用全局变量,不可更改,更改需要加全局声明:‘global’
num+=100
def test2():
print(num)
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
3.计算并发所用的时间
import threading
import time
def test1(n):
time.sleep(1)
print('task', n)
def test2(n):
time.sleep(1)
print('task', n)
start = time.time()
l = []
t1 = threading.Thread(target=test1, args=(1,))
t2 = threading.Thread(target=test1, args=(2,))
t1.start()
t2.start()
l.append(t1)
l.append(t2)
for i in l:
i.join()
end = time.time()print(end - start)
4.GIL全局解释器锁
GIL的全称是:Global Interpreter Lock,意思就是全局解释器锁,这个GIL并不是python的特性,他是只在Cpython解释器里引入的一个概念,而在其他的语言编写的解释器里就没有这个GIL。例如:Jython,Pypy
为什么会有gil?:
随着电脑多核cpu的出现核cpu频率的提升,为了充分利用多核处理器,进行多线程的编程方式更为普及,随之而来的困难是线程之间数据的一致性和状态同步,而python也利用了多核,所以也逃不开这个困难,为了解决这个数据不能同步的问题,设计了gil全局解释器锁。
说到gil解释器锁,我们容易想到在多线程中共享全局变量的时候会有线程对全局变量进行的资源竞争,会对全局变量的修改产生不是我们想要的结果,而那个时候我们用到的是python中线程模块里面的互斥锁,哪样的话每次对全局变量进行操作的时候,只有一个线程能够拿到这个全局变量;看下面的代码:
import threading
import time
global_num = 0
def test1():
global global_num
for i in range(1000000):
global_num += 1
def test2():
global global_num
for i in range(1000000):
global_num += 1
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
print(global_num)
print(global_num)
》》
104420
126353
》》
在上面的例子里,我们创建了两个线程来争夺对global_num的加一操作,但是结果并非我们想要的。
原因有2个:
(1)并发无序性
当执行代码时,会并发三个线程:2个函数线程,一个main主线程(即运行代码的线程);因为其线程执行是无序的,就有可能加一操作的函数线程未完成,主线程就已经输出值,而且函数线程操作过大时发生的概率就更大;
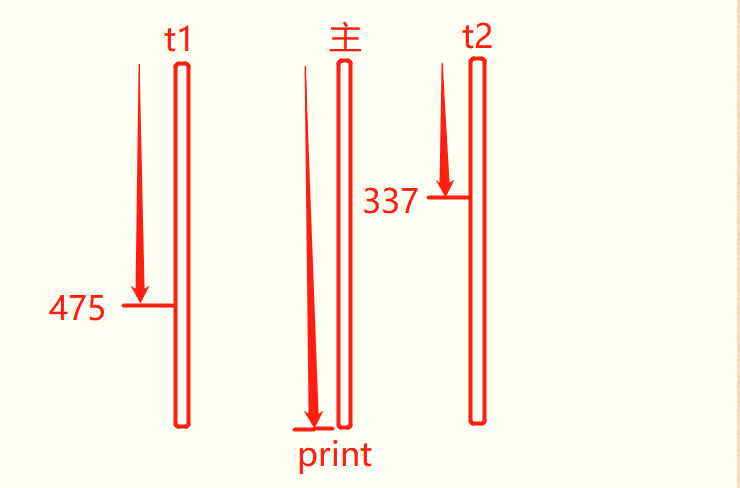
解决方法:
在最后输出global_num前加入:
t1.join()
t2.join()
‘join’其效果就是等待线程执行完毕
(2)资源争抢
当解决(1)问题后,其运行结果大约为100万多,并没有变成200万,原因如下图:
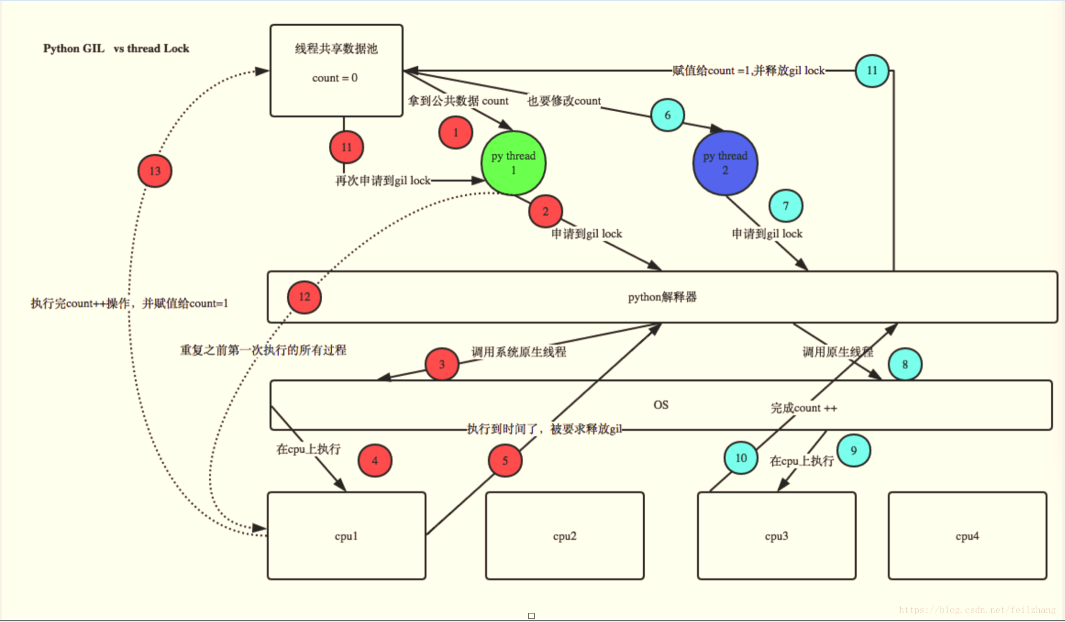
【解释】:假设当一次操作时,t1 线程拿到共享值num=20,其申请gil锁(不容许别人使用此值),接着进入cpu执行 +1 操作,但还未完成加一算法时,执行时间到了,被要求释放gil锁,此时t2开始运行(其运行初值num=20),进行相同操作返回num=21;接着运行t1之前未完成的操作(即给20进行+1操作),返回值依然为num=21;最终导致2次加一操作重复,而当这种操作过多时发生的次数也就越多,导致不能加到200万。
解决方法:我们在这里加入互斥锁,使得我一个加值操作完成后,才可被其他线程使用共享变量,其锁住的代码段是串行的,但未锁段依然并发。
import threading
import time
lock = threading.Lock() #注意实例化完整
global_num = 0
def test1():
global global_num
lock.acquire() #获取锁
for i in range(1000000):
global_num += 1
lock.release() #释放锁
def test2():
global global_num
lock.acquire()
for i in range(1000000):
global_num += 1
lock.release()
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
t1.join()
t2.join()
print(global_num)
》》
2000000
》》
【补】:IO密集与CPU密集
(1)CPU密集型(CPU-bound)
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
(2)IO密集型(I/O bound)
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
【二】多进程:
1. 含义:
一个程序运行起来之后,代码+用到的资源称之为进程,它是操作系统分配资源的基本单位,不仅可以通过线程完成多任务,进程也是可以的。
2.特点
#进程之间是相互独立的
#cpu密集的时候适合用多进程
#多进程比较耗费资源
3.多进程并发
import multiprocessing
import time
from multiprocessing import Pool
def test1():
for i in range(10):
time.sleep(1)
print('task1',i)
def test2():
for i in range(10):
time.sleep(1)
print('task2',i)
if __name__ == '__main__': #多进程必须要这一步
p1 = multiprocessing.Process(target=test1)
p2 = multiprocessing.Process(target=test2)
p1.start()
p2.start()
》》
task1 0
task2 0
task1 1
task2 1
task1 2
task2 2
task1 3
task2 3
task1 4
task2 4
task1 5
task2 5
task1 6
task2 6
task1 7
task2 7
task1 8
task2 8
task1 9
task2 9
》》
4.进程之间不共享
import multiprocessing
num = 0
def test1():
global num
for i in range(10):
num += 1
def test2():
print(num)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=test1)
p2 = multiprocessing.Process(target=test2)
p1.start()
p2.start()
》》
0
》》
5.进程池
import multiprocessing
from multiprocessing import Pool
import time
g_num = 0
def test1(n):
for i in range(n):
time.sleep(1)
print('test1', i)
def test2(n):
for i in range(n):
time.sleep(1)
print('test2', i)
def test3(n):
for i in range(n):
time.sleep(1)
print('test3', i)
def test4(n):
for i in range(n):
time.sleep(1)
print('test4', i)
if __name__ == '__main__':
pool = Pool(3) #把进程声明出来括号里不写东西说明无限制,如果写数字,就是最大的进程数
pool.apply_async(test1,(10,)) #用pool去调用函数test1,如果函数有参数,参数为10,格式为(10,)
pool.apply_async(test2,(10,))
pool.apply_async(test3,(10,))
pool.apply_async(test4,(10,))
pool.close() #close必须在join的前面
pool.join()
【三】协程并发(gevent)
1.特点
# 进程是资源分配的单位
# 线程是操作系统调度的单位
# 进程切换需要的资源最大,效率低
# 线程切换需要的资源一般,效率一般
# 协程切换任务资源很小,效率高
# 多进程、多线程根据cpu核数不一样可能是并行的,但是协程在一个线程中、
#协程遇见io就切换
2.协程,自动切换
import gevent,time
from gevent import monkey
monkey.patch_all()
def test1():
for i in range(10):
time.sleep(1)
print('test1', 1)
def test2():
for i in range(10):
time.sleep(2)
print('test2', 1)
g1 = gevent.spawn(test1)
g2 = gevent.spawn(test2)
g1.join()
g2.join()
=================================分割线==========================================