需求:
用mapreduce实现
select order.orderid,order.pdtid,pdts.pdt_name,oder.amount
from order
join pdts
on order.pdtid=pdts.pdtid
数据:
orders.txt
Order_0000001,pd001,222.8
Order_0000001,pd005,25.8
Order_0000002,pd005,325.8
Order_0000002,pd003,522.8
Order_0000002,pd004,122.4
Order_0000003,pd001,222.8
Order_0000003,pd001,322.8
pdts.txt
pd001,apple
pd002,banana
pd003,orange
pd004,xiaomi
pd005,meizu
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId> <artifactId>MapReduceCases</artifactId> <packaging>jar</packaging> <version>1.0</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> </properties> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.1.40</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.36</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <appendAssemblyId>false</appendAssemblyId> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>cn.itcast.mapreduce.CacheFile.MapJoinDistributedCacheFile</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>assembly</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
package cn.itcast.mapreduce.CacheFile; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; import java.net.URI; import java.util.HashMap; import org.apache.commons.lang.StringUtils; import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MapJoinDistributedCacheFile { private static final Log log = LogFactory.getLog(MapJoinDistributedCacheFile.class); public static class MapJoinDistributedCacheFileMapper extends Mapper<LongWritable, Text, Text, NullWritable> { FileReader in = null; BufferedReader reader = null; HashMap<String, String[]> b_tab = new HashMap<String, String[]>(); @Override protected void setup(Context context) throws IOException, InterruptedException { // 此处加载的是产品表的数据 in = new FileReader("pdts.txt"); reader = new BufferedReader(in); String line = null; while (StringUtils.isNotBlank((line = reader.readLine()))) { String[] split = line.split(","); String[] products = {split[0], split[1]}; b_tab.put(split[0], products); } IOUtils.closeStream(reader); IOUtils.closeStream(in); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] orderFields = line.split(","); String pdt_id = orderFields[1]; String[] pdtFields = b_tab.get(pdt_id); String ll = orderFields[0] + " " + pdtFields[1] + " " + orderFields[1] + " " + orderFields[2]; context.write(new Text(ll), NullWritable.get()); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // job.setJarByClass(MapJoinDistributedCacheFile.class); //告诉框架,我们的程序所在jar包的位置 job.setJar("/root/MapJoinDistributedCacheFile.jar"); job.setMapperClass(MapJoinDistributedCacheFileMapper.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("/mapjoin/input")); FileOutputFormat.setOutputPath(job, new Path("/mapjoin/output")); job.setNumReduceTasks(0); // job.addCacheFile(new URI("file:/D:/pdts.txt")); job.addCacheFile(new URI("hdfs://mini1:9000/cachefile/pdts.txt")); job.waitForCompletion(true); } }
创建文件夹上传数据
hadoop fs -mkdir -p /cachefile
hadoop fs -put pdts.txt /cachefile
hadoop fs -mkdir -p /mapjoin/input
hadoop fs -put orders.txt /mapjoin/input
打包并运行

运行
hadoop jar MapJoinDistributedCacheFile.jar cn.itcast.mapreduce.CacheFile.MapJoinDistributedCacheFile
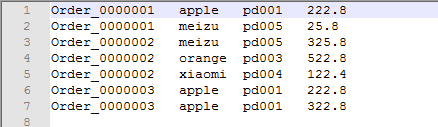
运行结果