标题:提取一般任务结构以加速对新任务的学习
Extracting general task structures to accelerate the learning of new tasks
0. 摘要
通过动觉演示向机器人教授新任务可能是一个漫长而复杂的过程。例如,每当对象或目标位置发生变化时,人类就必须演示新的“拾取和放置”任务。然而,获得这种任务的抽象表示可以显着减少学习时间,因为人类仅需教导成功执行所需的必要参数,例如对象的位置。在这项工作中,我们提出了一个框架,该框架允许提取一般的任务结构,这些结构连同所获得的知识可以改善并加快新任务的教学。此外,我们的框架利用任务参数之间的语义相似性来推断未知任务的可能结构。我们提出的方法利用结合了本体的任务的符号表示,使其适用于各个领域中的不同环境。我们在橙色排序方案和清洁方案中分析了我们的框架,以证明与仅通过动觉学习相比,它可以将教学时间分别从136.3减少到53秒(61.12%)和48.7减少到21秒(56.87%)。示威游行。
1. 介绍
有多种机制可以使机器人执行不同的任务:任务的每个步骤都可以由人类手动编程[1]; 可以使用计划算法从已知条件和作用的动作库中生成任务[2]; 或从演示中学到的知识可用于获取最佳任务执行模型[3]。 然而,随着机器人环境的复杂性增加,新任务的获取可能是非常耗时的过程,因为每次环境变化时机器人都必须获得新任务。 为了改善和加快任务的获取,机器人应该能够提取任务的抽象表示,这些抽象表示适用于不同场景并适应环境的变化。
例如,假设有人在教机器人如何捡橙子并将其放入盒子的任务。此类任务包括以下步骤:到达橙色,取下橙色,将橙色放入盒子中,然后释放橙色。假定该人希望机器人执行拾取和放置任务,但他没有将橙色放置在盒子中,而是需要将橙色放置在垃圾箱中,该垃圾箱与盒子的位置不同。因此,需要人工指导新的步骤:伸手去拿橘子,拿走橘子,将橘子放进垃圾桶,然后放开橘子。但是,在第二次演示中,人类重复了上一任务的相同步骤,这使其非常多余。然后,为了改善教学过程,机器人应该从第一个演示中提取拾取和放置任务的总体结构(图1),并用它来学习秒任务,而人类只需要指定一个新的位置即可。认沽活动。此外,所获得的结构可以重复使用,以加快其他任务的学习过程,例如清洁盘子,包括捡起一块海绵,将其放在盘子的顶部,然后擦拭盘子。人类只应演示擦板的新任务,而机器人可以利用其推理,利用先前拾取和放置任务中的知识来推断其余步骤。
本文的主要贡献是一种新方法,该方法通过从演示任务中提取关键结构并利用先前经验中的上下文知识来快速有效地教机器人新任务。 提取的结构表示为有向图,它可以捕获任务组件之间的重要关系并简化对已知任务的搜索。 另外,我们将获得的任务图与本体连接起来,以增强我们方法的通用性,使其适用于不同领域。

2. 相关工作
从演示中学习任务结构的一组方法是基于对低级轨迹信息的分析[4]。例如,李等人。 [5]将任务表示为一组运动原语,并利用高斯混合模型(GMM)提取任务模型,然后将其与动态原语(DMP)组合以提高模型的通用性[6]。其他方法手动分割运动序列并将其建模为有限状态机[7]或DMP [6]。另一方面,有几种方法正在使用隐马尔可夫模型(HMM)来识别演示数据中多个抽象级别的重复结构,这些重复结构被分割为单独的任务[8]。尽管此类方法对于任务环境中的细微变化(例如,拾取和放置任务的目标位置)具有鲁棒性,但它们无法捕获任务语义,这使得在不同域中重用获得的模型变得很复杂(例如, ,在印版清洁任务中重复使用拾取和放置任务)。另外,自举可以用来从演示中提取语义和感觉运动信息,这可以显着改善任务模型的获取[9],尽管任务结构的高度复杂性不允许所获得知识的可重用性。加速任务学习。
另一方面,符号表示可以在构建适用于不同领域的复杂任务结构时提供更好的灵活性。分层任务网络(HTN)是这种抽象任务表示形式的常见示例,它利用具有环境先决条件和效果的符号动作[10]。可以手动指定HTN [11],使用预定义的启发式规则生成[12],也可以通过因果关系分析和子目标发现自动构建HTN [13]。获得符号规范的另一种方法是通过与演示者的自然语言交互,其中任务结构可以编码为Petri网[14]或图形[15]。然后,所获得的规范可用于执行新学习任务的自动完成,并减少演示所需的步骤数[16]。但是,提出的方法不提供任何机制来修改和重新学习已知任务的单个组件,或者重用获得的任务结构来加快学习速度。
与上述方法类似,我们提出了一种能够从人类演示中提取抽象符号任务规范的技术。 我们方法的主要优点是,它可以通过使用有关学习到的任务的知识并利用不同任务参数之间的相似性来加快教学过程。 另外,我们的技术允许提取适用于不同领域的任务结构的一般表示。
3. 框架概述
在本节中,我们将定义系统的主要组件,描述它们之间的连接,并对所提出的学习算法进行概述。
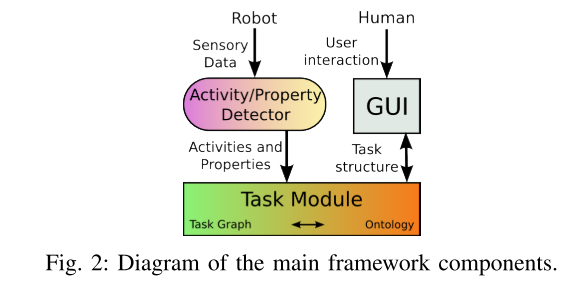
A. 框架设计
我们的框架如图2所示,它由活动/属性检测器模块,任务模块和GUI组成。 首先,使用推断语义人类活动推理器ISHAR方法从机器人的感觉数据中检测活动和属性[17]。
4. 结果
为了测试我们方法的一般性,我们首先使用三明治制作场景中的人工演示训练了第三节中描述的框架。 然后,我们将获得的图应用于一个不同的问题,在该问题中,我们正在向移动机器人讲授橙色排序方案。 结果将证明,我们的方法可以为训练后的领域提取任务的抽象结构,然后成功地重用它们以加快在不同领域中新任务的教学。
A. 任务图学习
为了显示具有符号表示的优势,我们使用提出的框架从图像域学习任务图(图2),然后将其应用于实际的机器人。 为了进行训练,我们选择三明治制作数据集3,其中包含从5个以60Hz频率同步的摄像机获得的10335个图像记录。 我们选择3个随机参与者,每个参与者有3个试验,总共产生9个训练数据集[22]。 我们手动标记数据并识别14种不同的活动(例如,到达,展开,展开等)。
B. 实验设置
接下来,我们在橙色排序的不同场景下验证我们获得的任务图。 实验设置如图4所示。我们使用一个称为Tactile全方位移动机械手(TOMM)的机器人平台,该平台由两个覆盖有人造皮肤的工业机器人手臂(UR-5)[23],两个也覆盖有Lacquey抓取器的机器人组成。 我们的人造皮肤和一个华硕Xtion Pro,它是彩色图像和深度传感器。 我们使用ROS4中间件和视觉注意系统实现了第三节(图2)中描述的框架[24]。

c. 测试场景
为了证明我们的方法可以成功地加速任务学习过程,我们选择了两种不同的方案。 在第一个中,当框架了解到所学任务的结构时,我们会评估教学加速。 在第二种情况下,我们评估框架如何利用任务结构的相似性来改进未知任务的教学。
我们选择橙色排序作为第一个方案,该方案最初在[25]中实现。 在这种情况下,演示者向机器人展示了如何识别好橙子(质地坚硬的橘子)和坏橙子(质地软劣的橘子)。 然后,演示者显示应将好的橙子放入盒子,将坏的橙子扔进垃圾箱。 演示者定义了以下任务:

但是,任务1-3只是具有不同目的地的拾取和放置任务的变体,而任务4-5的区别在于标识好/坏橙色的参数。 代替进行多余的演示,机器人可以利用其知识来推断所需任务的已知结构。
5. 总结
在这项工作中,我们介绍了一种技术,该技术可以从人类演示中提取不同任务的关键结构,并重用获得的知识和过去的经验来加快教学过程。 首先,我们从三明治制作方案的数据集中生成任务知识。 然后,我们通过讲授橙色分拣和印版清洗这两种不同的情况,在机器人TOMM中验证所获得的任务图。 结果表明,通过重用学习到的任务结构,我们的框架可以将分类橙子场景的教学过程时间从136.3缩短到53秒(61.12%),将清洁场景中的教学过程时间从48.7缩短到21秒(56.87%)。 此外,我们的框架在一个领域(烹饪场景)进行了培训,然后在不同领域(分类和清洁)重用了所获得的知识。
我们未来的工作将评估框架对多个非专家用户演示的复杂任务的鲁棒性。 此外,我们将更详细地探索不同任务结构之间的相似性,以找到合适的方法来自动提取新特性和活动。

此外,演示者可以通过GUI与机器人进行交互(请参见图5a)。 为了请求有关拾取和放置任务结构的知识,演示者选择PutSomethingSomewhere作为关键活动,选择Release作为最终状态(请参阅第III-C节)。 该框架将推断图5b中所示的任务结构。 然后,用户选择获得的任务结构,然后框架通知他必须指定PutSomethingSomewhere活动的期望目的地。 该框架通过使用视觉传感器提供的数据,为PutSomethingSomewhere活动提供可能的目的地列表(箱,垃圾箱和挤压区),从而为人类提供帮助。 人类可以从框架建议的清单中选择一个目的地,或者使用动觉教学来演示它。 与此类似,人类教机器人2和3的任务。
任务4对于系统来说是未知的,并且人类必须使用动觉教学来演示该任务。 该框架将在任务图中插入一个新的分支,代表任务4的结构。然后,演示者可以重用所获得的知识来教授任务5,在那里他仅需要演示不良橙色的值即可。
我们将清理任务定义为第二种情况,以针对结构相似的任务评估系统的健壮性。 在这种情况下,演示者教机器人如何用海绵清洁盘子。 该演示包括以下步骤:拿一块海绵; 拿海绵 将海绵移至平板上方; 用海绵擦拭盘子; 将海绵移到原始位置; 松开海绵。
演示者使用“擦除”作为关键活动向知识库生成请求。 任务图不包含有关涉及此活动的任务的任何信息,但是,它将发现类似的任务,即用相似度0.35展开奶酪。 检索到的步骤顺序是:到达包装好的奶酪; 拿起包裹的奶酪; 将包裹好的奶酪移到切菜板上; 打开奶酪包装; 将包装纸移到垃圾箱,松开包装纸。 如果演示者想重用此结构,则在GUI中选择UnWrap活动并选择“替换”按钮(图5b)。 然后,通过GUI和动觉教学,人类向框架展示了新的活动Wipe,它将使用它来修改图5b所示的任务结构并更新现有的任务图。
为了评估我们的框架,我们测量使用我们的方法讲授每种情况所需的时间,并将结果与仅使用动觉演示来讲授相同情景所需的时间进行比较。 我们进行了5次实验,结果如图6a所示。 蓝色条形表示整个任务演示的时间测量,绿色条形表示我们框架的时间测量,其中动觉教学用于演示缺少的信息,黄色条形表示当使用来自视觉传感器的数据进行时间测量时的时间测量。 指定拾取和放置任务的位置。
对第二种情况的评估与先前类似。 我们通过整个任务演示测量了教授整个清洁任务所需的时间,并将其与我们的系统进行了比较,在该系统中,不同任务的结构之间的相似性被用来加速教学过程。 结果显示在图6a中。 与手动任务说明[26]相比,我们的方法的优势在于,要求用户仅演示缺少的信息,而不是每次教新任务时都生成完整的描述。 与整个任务演示相比,我们的方法所提供的时间减少如图6b所示。 我们的框架允许将讲授橙色分选方案所需的时间从136.3减少到53秒(61.12%),将讲授清洁方案所需的时间从48.7减少到21秒(56.87%)。