跟大多数分布式系统一样,es也通过临时写入写操作来保证数据安全。因为lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘。这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失。es通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取。
这一部分主要包括两部分translog和tanslogFile,前者对外提供了对translogFile操作的相关接口,后者则是具体的translogFile,它是具体的文件。首先看一下translogFile的继承关系,如下图所示:
实现了两种translogFile,它们的最大区别如名字所示就是写入时是否缓存。FsTranslogFile的接口如下所示:
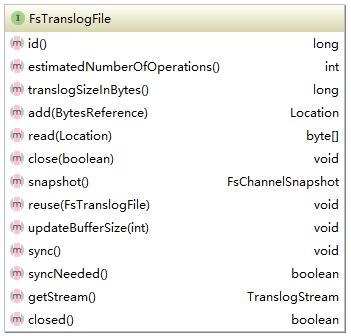
每一个translogFile都会有一个唯一Id,两个非常重要的方法add和write。add是添加对应的操作,这些操作都是在translog中定义,这里写入的只是byte类型的文件,不关注是何种操作。所有的操作都是顺序写入,因此读取的时候需要一个位置信息。
TransLog主要作用是实时记录对于索引的修改操作,确保在索引写入磁盘前出现系统故障不丢失数据。tanslog的主要作用就是索引恢复,正常情况下需要恢复索引的时候非常少,它以stream的形式顺序写入,不会消耗太多资源,不会成为性能瓶颈。它的实现上,translog提供了对外的接口,translogFile是具体的文件抽象,提供了对于文件的具体操作。
Flushing of Tansaction log
translog帮助防止节点失败时的数据丢失。它的设计目的是帮助shard恢复操作,否则数据可能会从内存flush到磁盘时发生意外而丢失。日志每5秒被提交到磁盘上,或者在每个成功的索引、删除、更新或批量请求时提交。
为了防止数据丢失,每个shard都有一个事务日志或与之关联的写入日志。任何索引或删除操作在内部Lucene索引处理后被写入到translog中。在崩溃的情况下,当shard恢复时,可以从事务日志中重新重放最近的事务。
ES的flush是执行Lucene提交并产生新的translog的过程。它是在后台自动完成的,以确保事务日志不会太大,这将使在恢复期间重放其操作花费大量时间。它也通过API来操作。
与刷新索引shard相比,真正昂贵的操作是刷新其事务日志(涉及Lucene提交)。通过延迟刷新或完全禁用它们,可以提高索引吞吐量。但是这种做法有利有弊,延迟的flush当然会花费更长的时间。
基本参数
index.translog.flush_threshold_size - translog按size大小flush,默认为521M。
我们可以增加index.translog.flush_threshold_size从默认的512M到更大的值,比如1gb。这允许在发生刷新之前在translog中积累更大的segment。通过让更大的segment构建,可以减少刷新的频率,而更大的segement合并的频率也更低。所有这些都减少了磁盘I/O开销,提高了索引吞吐量。当然,将需要相应的heap空闲内存来提供额外缓冲空间,调整时此设置时请记住这一点。
index.translog.flush_threshold_ops - 多少任务来执行操作,默认为ulimited
index.translog.flush_threshold_period - 在触发刷新之前,不管事务日志大小,需要等待多长时间。默认为30m
index.translog.sync_interval - 多久检测是否需要flush。默认为5s
index.translog.durability - sync方式。默认为fsync,可选为async。2者区别,fsync每次操作都会commit到translog。async按设置的sync_interval时间定期commit到translog。 fsync更耗费资源,但可靠性好,async模式下,如果sync_interval间隔时间内发生问题,中间没有commit的操作会全部丢失
如没有其他特殊需求。可以使用一下参数来配置
index.translog.flush_threshold_size: "1gb" index.translog.sync_interval: "60s" index.translog.durability: "async"