Building Chinese Affective Resources in Valence-Arousal Dimensions
一、本篇论文要解决的问题
越来越多的研究集中在将情感状态表示为多维度上的连续值,最常见的多维度空间为Aalence-Arousal(VA)空间。与之前的将情感状态分为几类(正面和反面)相比,维度方法可以提供更加细粒度的情感分析。然后带有VA等级的情感资源却非常的缺乏,中文资源更显严重。因此本文的目的是建立可用于情感分析的中文VA词典(CVAW)和中文VA文本语料库(CVAT),以此来丰富VA维度下多语言的情感研究和开发。
二、VA空间
Valence代表愉快和不愉快(即积极和消极)的程度,而Arousal代表兴奋和平静的程度。基于这种表示,任何情感状态都可以表示为VA坐标平面上的一个点。即该坐标平面内的每一个点都代表着一种情感状态。如下图所示。
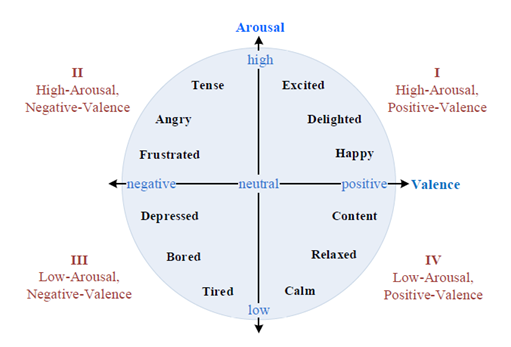
三、现有情感资源词典和语料库
SentiWordNet是一种用于意见挖掘的词汇资源,它为WordNet的每个synset分配三个情绪等级(消极、积极、客观)。
语言查询和计数(LIWC):计算在广泛的文本范围内人们使用不同类别的单词的程度。
The Chinese LIWC (C-LIWC) :是LIWC的中文译本,它是根据中文的实际应用情况进行人工翻译的。
Norms for English Words (ANEW) provides 1,034 English words with ratings in the dimensions of pleasure, arousal and dominance ,它唯一提供了VAD三个维度的实值。
The NTU Sentiment dictionary(NTUSD):同时采用了人工和自动的方法来进行标注,包括了积极和消极的情感词汇。
四、建立方法
CVAW的建立:它是建立在C-LIWC的基础之上的,采用自我评定人体模型(SAVM),即经过培训的注释者们给每个单词一个在VA维度的值,同时SVA会给出一些图片来提高注释者们的精确度。Valence维度值的范围是1-9(1表示最消极,9表示最积极)5表示没有明显倾向的中性情感。Arousal也是采用类似的方法来进行。最后将5个注释者所给的值得平均值作为该单词的VA值,从而就得到CVAW词典。
CVAT的建立:从6种不同类型的网络信息中选择处720条,总共包括2009个包括C-LIWC词典中出现次数最多的情感词的句子被选出来进行VA评定。志愿者们对这些句子进行1-9的评分,每个句子至少被评定10次。评分结束后会执行一个语料库清楚程序来去除一些VA值异常(不在平均值左右1.5标准偏差的区间内的VA值)和不恰当的句子。去除掉以后,这些句子将不再参加平均VA值得计算。
五、评估方法
采用一种综合平均方法,并且使用CVAW中的词来预估CVAT中句子的VA值。句子的valence(或者arousal)等于句子中那些包含在CVAW词典章的词语的Valence(或arousal)值的平均值。将以此方法得出的VA值与句子实际的VA值进行比较,来计算平均j绝对误差(MAS)、均方根误差(RMSE)和Pearson相关系数r。同时采用ANEW来预估20个英文论坛消息的结果也被呈现出来作为对比。
六、结果分析
用CVAW来预测CVAT中句子的VA值的效果跟用英语情感资源来预测所得的效果是相当的。并且实验发现,无论是英语情感资源还是中文情感资源,arousal维度比valence维度更加难预测。