使用kubeadm安装kubernetes_v1.20.x
官方文档:https://kuboard.cn/install/history-k8s/install-k8s-1.20.x.html
我们这里的部署流程是:
-
1.
kubeadm init初始化。修改容器运行时cri为containerd,crictl命令不能补全,这个命令的用法类似于docker,稍晚我会再写一篇有关crictl使用的文章。 -
2.用的calico网络插件,不用flannel
-
3.安装metrics-server获取监控数据
-
4.安装kubernetes dashboard web界面更直观
-
5.ingress-nginx
-
6.调通之后,测试rbac权限权限,不同用户不用的serviceaccount,写成一个yaml文件
Container Runtime
- Kubernetes v1.20 开始,默认移除 docker 的依赖,如果宿主机上安装了 docker 和 containerd,将优先使用 docker 作为容器运行引擎,如果宿主机上未安装 docker 只安装了 containerd,将使用 containerd 作为容器运行引擎;
- 本文使用 containerd 作为容器运行引擎;
关于二进制安装
- kubeadm 是 Kubernetes 官方支持的安装方式,“二进制” 不是。本文档采用 kubernetes.io 官方推荐的 kubeadm 工具安装 kubernetes 集群。
检查 centos / hostname
# 在 master 节点和 worker 节点都要执行
cat /etc/redhat-release
# 此处 hostname 的输出将会是该机器在 Kubernetes 集群中的节点名字
# 不能使用 localhost 作为节点的名字
hostname
# 请使用 lscpu 命令,核对 CPU 信息
# Architecture: x86_64 本安装文档不支持 arm 架构
# CPU(s): 2 CPU 内核数量不能低于 2
lscpu
修改 hostname
如果您需要修改 hostname,可执行如下指令:
# 修改 hostname
hostnamectl set-hostname your-new-host-name
# 查看修改结果
hostnamectl status
# 设置 hostname 解析
echo "127.0.0.1 $(hostname)" >> /etc/hosts
检查网络
在所有节点执行命令
[root@demo-master-a-1 ~]$ ip route show
default via 172.21.0.1 dev eth0
169.254.0.0/16 dev eth0 scope link metric 1002
172.21.0.0/20 dev eth0 proto kernel scope link src 172.21.0.12
[root@demo-master-a-1 ~]$ ip address
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:16:3e:12:a4:1b brd ff:ff:ff:ff:ff:ff
inet 172.17.216.80/20 brd 172.17.223.255 scope global dynamic eth0
valid_lft 305741654sec preferred_lft 305741654sec
kubelet使用的IP地址:
ip route show命令中,可以知道机器的默认网卡,通常是 eth0,如default via 172.21.0.23 dev eth0ip address命令中,可显示默认网卡的 IP 地址,Kubernetes 将使用此 IP 地址与集群内的其他节点通信,如 172.17.216.80- 所有节点上 Kubernetes 所使用的 IP 地址必须可以互通(无需 NAT 映射、无安全组或防火墙隔离)
安装containerd/kubelet/kubeadm/kubectl
使用 root 身份在所有节点执行如下代码,以安装软件:
- containerd
- nfs-utils
- kubectl / kubeadm / kubelet
手动执行以下代码,结果与快速安装相同。请将脚本第79行(已高亮)的 ${1}替换成您需要的版本号,例如 1.20.6
docker hub镜像请根据自己网络的情况任选一个
# 在 master 节点和 worker 节点都要执行
# 最后一个参数 1.20.6 用于指定 kubenetes 版本,支持所有 1.20.x 版本的安装
# 阿里云docker hub镜像
export REGISTRY_MIRROR=https://registry.cn-hangzhou.aliyuncs.com
#!/bin/bash
# 在 master 节点和 worker 节点都要执行
# 安装 containerd
# 参考文档如下
# https://kubernetes.io/docs/setup/production-environment/container-runtimes/#containerd
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# Setup required sysctl params, these persist across reboots.
cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
# Apply sysctl params without reboot
sysctl --system
# 卸载旧版本
yum remove -y containerd.io
# 设置yum repository
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 安装containerd
yum install -y containerd.io-1.4.3
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
sed -i "s#k8s.gcr.io#registry.aliyuncs.com/k8sxio#g" /etc/containerd/config.toml
sed -i '/containerd.runtimes.runc.options/a SystemdCgroup = true' /etc/containerd/config.toml
sed -i "s#https://registry-1.docker.io#${REGISTRY_MIRROR}#g" /etc/containerd/config.toml
systemctl daemon-reload
systemctl enable containerd
systemctl restart containerd
# 安装nfs-utils
# 必须先安装 nfs-utils 才能挂载 nfs 网络存储
yum install -y nfs-utils
yum install -y wget
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭seLinux
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
# 关闭swap
swapoff -a
yes | cp /etc/fstab /etc/fstab_bak
cat /etc/fstab_bak |grep -v swap > /etc/fstab
# 配置K8S的yum源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 卸载旧版本
yum remove -y kubelet kubeadm kubectl
# 安装kubelet、kubeadm、kubectl
# 将 ${1} 替换为 kubernetes 版本号,例如 1.20.6
yum install -y kubelet-${1} kubeadm-${1} kubectl-${1}
crictl config runtime-endpoint /run/containerd/containerd.sock
# 重启 docker,并启动 kubelet
systemctl daemon-reload
systemctl enable kubelet && systemctl start kubelet
containerd --version
kubelet --version
如果此时执行 systemctl status kubelet 命令,将得到 kubelet 启动失败的错误提示,请忽略此错误,因为必须完成后续步骤中 kubeadm init 的操作,kubelet 才能正常启动。
初始化 master 节点
关于初始化时用到的环境变量:
APISERVER_NAME不能是 master 的 hostnameAPISERVER_NAME必须全为小写字母、数字、小数点,不能包含减号POD_SUBNET所使用的网段不能与 master节点/worker节点 所在的网段重叠。该字段的取值为一个 CIDR 值,如果您对 CIDR 这个概念还不熟悉,请仍然执行export POD_SUBNET=10.100.0.1/16命令,不做修改。
手动执行以下代码,结果与快速初始化相同。请将脚本第21行(已高亮)的 ${1} 替换成您需要的版本号,例如 1.20.6
# 只在 master 节点执行
# 替换 x.x.x.x 为 master 节点的内网IP
# export 命令只在当前shell会话中有效,开启新的shell窗口后,如果要继续安装过程,请重新执行此处的export命令
export MASTER_IP=x.x.x.x
# 替换 apiserver.demo 为 您想要的 dnsName
export APISERVER_NAME=apiserver.demo
# Kubernetes 容器组所在的网段,该网段安装完成后,由 kubernetes 创建,事先并不存在于您的物理网络中
export POD_SUBNET=10.100.0.1/16
echo "${MASTER_IP} ${APISERVER_NAME}" >> /etc/hosts
#!/bin/bash
# 只在 master 节点执行
# 脚本出错时终止执行
set -e
if [ ${#POD_SUBNET} -eq 0 ] || [ ${#APISERVER_NAME} -eq 0 ]; then
echo -e "�33[31;1m请确保您已经设置了环境变量 POD_SUBNET 和 APISERVER_NAME �33[0m"
echo 当前POD_SUBNET=$POD_SUBNET
echo 当前APISERVER_NAME=$APISERVER_NAME
exit 1
fi
# 查看完整配置选项 https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta2
rm -f ./kubeadm-config.yaml
cat <<EOF > ./kubeadm-config.yaml
---
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v${1}
imageRepository: registry.aliyuncs.com/k8sxio
controlPlaneEndpoint: "${APISERVER_NAME}:6443"
networking:
serviceSubnet: "10.96.0.0/16"
podSubnet: "${POD_SUBNET}"
dnsDomain: "cluster.local"
dns:
type: CoreDNS
imageRepository: swr.cn-east-2.myhuaweicloud.com${2}
imageTag: 1.8.0
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
EOF
# kubeadm init
# 根据您服务器网速的情况,您需要等候 3 - 10 分钟
echo ""
echo "抓取镜像,请稍候..."
kubeadm config images pull --config=kubeadm-config.yaml
echo ""
echo "初始化 Master 节点"
kubeadm init --config=kubeadm-config.yaml --upload-certs
# 配置 kubectl
rm -rf /root/.kube/
mkdir /root/.kube/
cp -i /etc/kubernetes/admin.conf /root/.kube/config
# 安装 calico 网络插件
# 参考文档 https://docs.projectcalico.org/v3.13/getting-started/kubernetes/self-managed-onprem/onpremises
echo ""
echo "安装calico-3.17.1"
rm -f calico-3.17.1.yaml
kubectl create -f https://kuboard.cn/install-script/v1.20.x/calico-operator.yaml
wget https://kuboard.cn/install-script/v1.20.x/calico-custom-resources.yaml
sed -i "s#192.168.0.0/16#${POD_SUBNET}#" calico-custom-resources.yaml
kubectl create -f calico-custom-resources.yaml
如果出现如下错误:
[config/images] Pulled registry.aliyuncs.com/k8sxio/pause:3.2
[config/images] Pulled registry.aliyuncs.com/k8sxio/etcd:3.4.13-0
failed to pull image "swr.cn-east-2.myhuaweicloud.com/coredns:1.8.0": output: time="2021-04-30T13:26:14+08:00" level=fatal
msg="pulling image failed: rpc error: code = NotFound desc = failed to pull and unpack image "swr.cn-east-2.myhuaweicloud.com/coredns:1.8.0":
failed to resolve reference "swr.cn-east-2.myhuaweicloud.com/coredns:1.8.0":
swr.cn-east-2.myhuaweicloud.com/coredns:1.8.0: not found", error: exit status 1
To see the stack trace of this error execute with --v=5 or higher
请执行如下命令:
在原命令的最后增加参数 /coredns
curl -sSL https://kuboard.cn/install-script/v1.20.x/init_master.sh | sh -s 1.20.6 /coredns
检查master初始化结果
# 只在 master 节点执行
# 执行如下命令,等待 3-10 分钟,直到所有的容器组处于 Running 状态
watch kubectl get pod -n kube-system -o wide
# 查看 master 节点初始化结果
kubectl get nodes -o wide
初始化worker节点
获得join命令参数
在 master 节点上执行
# 只在 master 节点执行
kubeadm token create --print-join-command
可获取kubeadm join命令及参数,如下所示
# kubeadm token create 命令的输出
kubeadm join apiserver.demo:6443 --token mpfjma.4vjjg8flqihor4vt --discovery-token-ca-cert-hash sha256:6f7a8e40a810323672de5eee6f4d19aa2dbdb38411845a1bf5dd63485c43d303
该 token 的有效时间为 2 个小时,2小时内,您可以使用此 token 初始化任意数量的 worker 节点。
# 初始化worker
针对所有的 worker 节点执行
# 只在 worker 节点执行
# 替换 x.x.x.x 为 master 节点的内网 IP
export MASTER_IP=x.x.x.x
# 替换 apiserver.demo 为初始化 master 节点时所使用的 APISERVER_NAME
export APISERVER_NAME=apiserver.demo
echo "${MASTER_IP} ${APISERVER_NAME}" >> /etc/hosts
# 替换为 master 节点上 kubeadm token create 命令的输出
kubeadm join apiserver.demo:6443 --token mpfjma.4vjjg8flqihor4vt --discovery-token-ca-cert-hash sha256:6f7a8e40a810323672de5eee6f4d19aa2dbdb38411845a1bf5dd63485c43d303
# 检查初始化结果
在 master 节点上执行
# 只在 master 节点执行
kubectl get nodes -o wide
输出结果如下所示:
[root@demo-master-a-1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
demo-master-a-1 Ready master 5m3s v1.20.x
demo-worker-a-1 Ready <none> 2m26s v1.20.x
demo-worker-a-2 Ready <none> 3m56s v1.20.x
安装metrics-server —— K8s资源监控指标
参考链接: https://blog.csdn.net/wangmiaoyan/article/details/102868728
K8S资源指标获取工具:metrics-server
自定义指标的监控工具:prometheus,k8s-prometheus-adapter
prometheus:prometheus能够收集各种维度的资源指标,比如CPU利用率,网络连接的数量,网络报文的收发速率,包括进程的新建及回收速率等等,能够监控许许多多的指标,而这些指标K8S早期是不支持的,所以需要把prometheus能采集到的各种指标整合进k8s里,能让K8S根据这些指标来判断是否需要根据这些指标来进行pod的伸缩。
prometheus既作为监控系统来使用,也作为某些特殊的资源指标的提供者来使用。但是这些指标不是标准的K8S内建指标,称之为自定义指标,但是prometheus要想将监控采集到的数据作为指标来展示,则需要一个插件,这个插件叫k8s-prometheus-adapter,这些指标判断pod是否需要伸缩的基本标准,例如根据cpu的利用率、内存使用量去进行伸缩。
随着prometheus和k8s-prometheus-adapter的引入,新一代的k8s架构也就形成了。
K8S新一代架构
核心指标流水线:由kubelet、metrics-server以及由API server提供的api组成;CPU累积使用率、内存的实时使用率、pod的资源占用率及容器的磁盘占用率;
监控流水线:用于从系统收集各种指标数据并提供给终端用户、存储系统以及HPA,包含核心指标以及其他许多非核心指标。非核心指标本身不能被K8S所解析。所以需要k8s-prometheus-adapter将prometheus采集到的数据转化为k8s能理解的格式,为k8s所使用。
核心指标监控
之前使用的是heapster,但是1.12后就废弃了,之后使用的替代者是metrics-server;metrics-server是由用户开发的一个api server,用于服务资源指标,而不是服务pod,deploy的。metrics-server本身不是k8s的组成部分,是托管运行在k8s上的一个pod,那么如果想要用户在k8s上无缝的使用metrics-server提供的api服务,因此在新一代的架构中需要这样去组合它们。如图,使用一个聚合器去聚合k8s的api server与metrics-server,然后由群组/apis/metrics.k8s.io/v1beta1来获取。

图1
之后如果用户还有其他的api server都可以整合进aggregator,由aggregator来提供服务,如图。
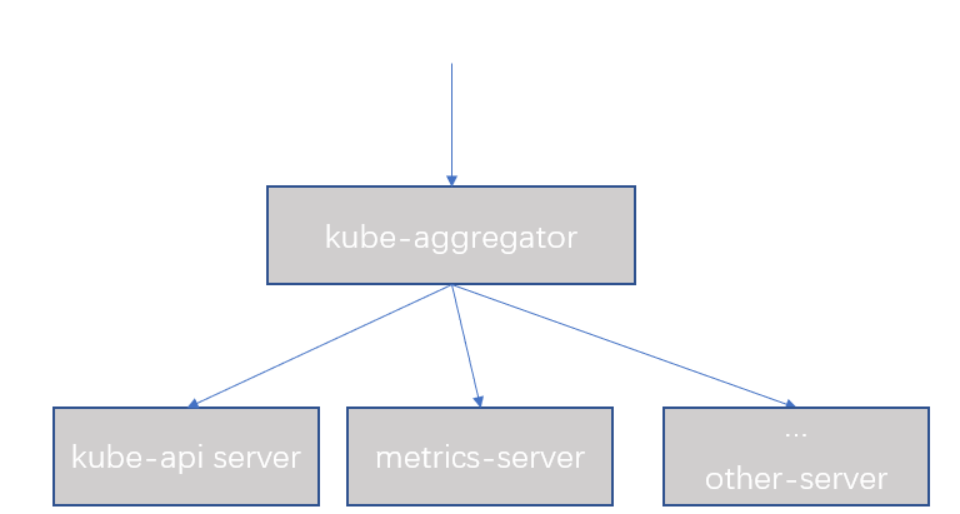
图2
查看k8s默认的api-version,可以看到是没有metrics.k8s.io这个组的kubectl api-versions
当你部署好metrics-server后再查看api-versions就可以看到metrics.k8s.io这个组了。
部署metrics-server
进到kubernetes项目下的cluster下的addons,找到对应的项目下载下来
[root@master bcia]# mkdir metrics-server -p
[root@master bcia]# cd metrics-server/
# 一次性下载所有文件
[root@master metrics-server]# for file in auth-delegator.yaml auth-reader.yaml metrics-apiservice.yaml metrics-server-deployment.yaml metrics-server-service.yaml resource-reader.yaml ; do wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/metrics-server/$file;done
--2019-11-02 10:18:10-- https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/metrics-server/auth-delegator.yaml
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.228.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.228.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 398 [text/plain]
Saving to: ‘auth-delegator.yaml’
100%[==========================================================================>] 398 --.-K/s in 0s
...省略...
[root@master metrics-server]# ls
auth-delegator.yaml metrics-apiservice.yaml metrics-server-service.yaml
auth-reader.yaml metrics-server-deployment.yaml resource-reader.yaml
# 一次性运行所有文件
[root@master metrics-server]# kubectl apply -f .
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
configmap/metrics-server-config created
deployment.apps/metrics-server-v0.3.6 created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
运行后发现报错,一次性删除所有,修改几处地方,如图
- 1.metrics-server-deployment.yaml
metrics-server的command中加上- --kubelet-insecure-tls表示不验证客户端的证书,注释掉端口10255,注释后会使用10250,通过https通信。addon-resizer的command中写上具体的cpu、memory、extra-memory的值,注释掉minClusterSize={undefined{ metrics_server_min_cluster_size }}
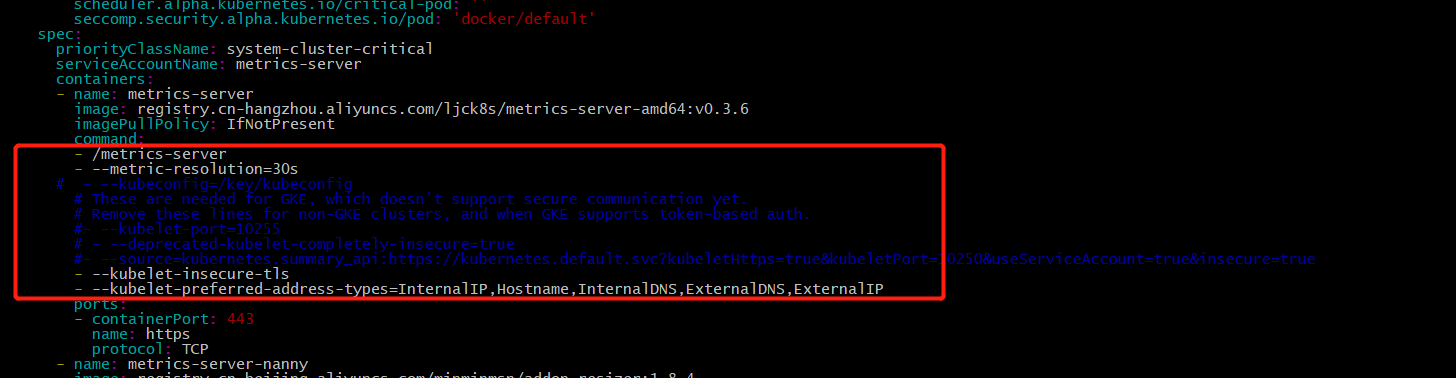
图1
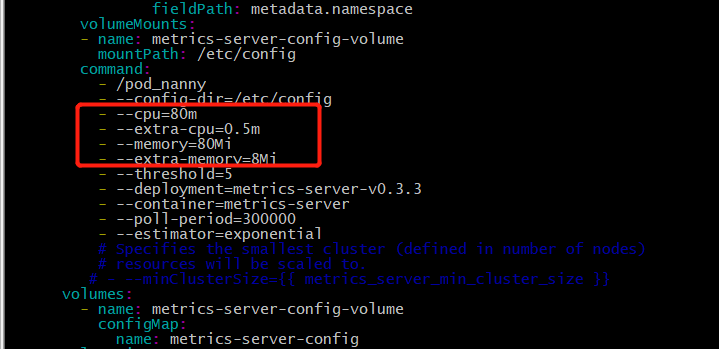
图2
- 2.resource-reader.yaml 加上
nodes/stats,如图
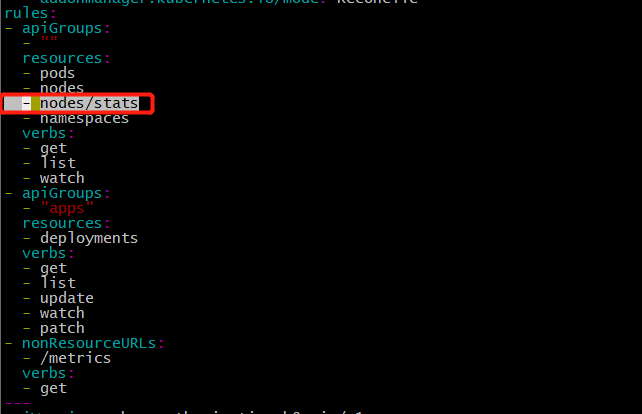
图3
测试是否可使用
- 1.查看pods是否正常运行
[root@master metrics-server]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-8686dcc4fd-bzgss 1/1 Running 0 9d
coredns-8686dcc4fd-xgd49 1/1 Running 0 9d
etcd-master 1/1 Running 0 9d
kube-apiserver-master 1/1 Running 0 9d
kube-controller-manager-master 1/1 Running 0 9d
kube-flannel-ds-amd64-52d6n 1/1 Running 0 9d
kube-flannel-ds-amd64-k8qxt 1/1 Running 0 8d
kube-flannel-ds-amd64-lnss4 1/1 Running 0 9d
kube-proxy-4s5mf 1/1 Running 0 8d
kube-proxy-b6szk 1/1 Running 0 9d
kube-proxy-wsnfz 1/1 Running 0 9d
kube-scheduler-master 1/1 Running 0 9d
kubernetes-dashboard-76f6bf8c57-rncvn 1/1 Running 0 8d
metrics-server-v0.3.6-677d79858c-75vk7 2/2 Running 0 18m
tiller-deploy-57c977bff7-tcnrf 1/1 Running 0 7d20h
- 2.查看
api-versions,会看到多出了metrics.k8s.io/v1beta1
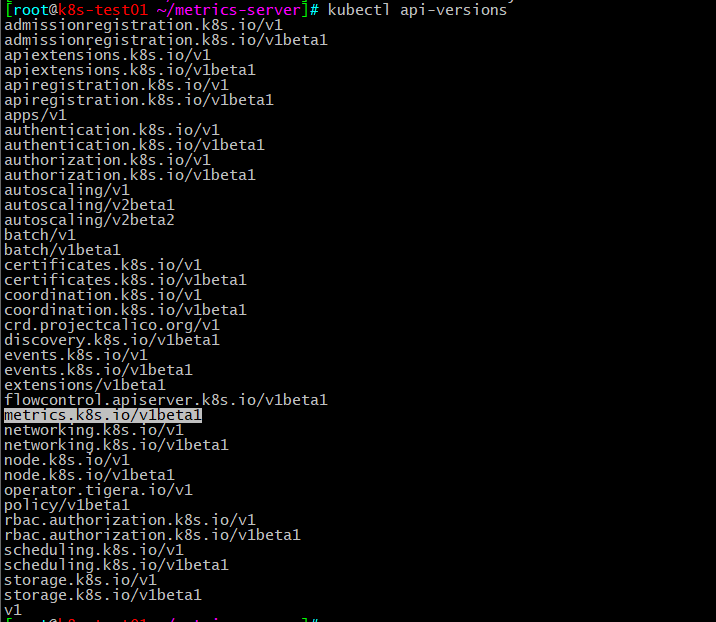
图4
- 3.查看node及pod监控指标
[root@master metrics-server]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 145m 3% 1801Mi 11%
node2 697m 17% 12176Mi 77%
node3 838m 20% 12217Mi 77%
[root@master metrics-server]# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
account-deploy-6d86f9df74-khv4v 5m 444Mi
admin-deploy-55dcf4bc4d-srw8m 2m 317Mi
backend-deploy-6f7bdd9bf4-w4sqc 4m 497Mi
crm-deploy-7879694578-cngzp 4m 421Mi
device-deploy-77768bf87c-ct5nc 5m 434Mi
elassandra-0 168m 4879Mi
gateway-deploy-68c988676d-wnqsz 4m 379Mi
jhipster-alerter-74fc8984c4-27bx8 1m 46Mi
jhipster-console-85556468d-kjfg6 3m 119Mi
jhipster-curator-67b58477b9-5f8br 1m 11Mi
jhipster-logstash-74878f8b49-mpn62 59m 860Mi
jhipster-zipkin-5b5ff7bdbc-bsxhk 1m 1571Mi
order-deploy-c4c846c54-2gxkp 5m 440Mi
pos-registry-76bbd6c689-q5w2b 442m 474Mi
recv-deploy-5dd686c947-v4qqh 5m 424Mi
store-deploy-54c994c9b6-82b8z 6m 493Mi
task-deploy-64c9984d88-fqxqq 6m 461Mi
wiggly-cat-redis-ha-sentinel-655f7b5f9d-bbrz6 4m 4Mi
wiggly-cat-redis-ha-sentinel-655f7b5f9d-bj4bq 4m 5Mi
wiggly-cat-redis-ha-sentinel-655f7b5f9d-f9pdd 4m 5Mi
wiggly-cat-redis-ha-server-b58c8d788-6xlwk 3m 11Mi
wiggly-cat-redis-ha-server-b58c8d788-r949h 3m 8Mi
wiggly-cat-redis-ha-server-b58c8d788-w2gtb 3m 22Mi
至此,metrics-server部署结束。
k8s部署dashboard
参考:https://github.com/kubernetes/dashboard
# 下载dashboard的yaml文件
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.3/aio/deploy/recommended.yaml
# 默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部
vim recommended.yaml
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 30001
type: NodePort
selector:
k8s-app: kubernetes-dashboard
kubectl apply -f recommended.yaml
kubectl get pods,svc -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/dashboard-metrics-scraper-7b59f7d4df-7mcvs 1/1 Running 0 27h
pod/kubernetes-dashboard-5dbf55bd9d-r8q6t 1/1 Running 0 27h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dashboard-metrics-scraper ClusterIP 10.96.191.54 <none> 8000/TCP 27h
service/kubernetes-dashboard NodePort 10.96.83.45 <none> 443:30001/TCP 27h
# 创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
# 登录主页的token
eyJhbGciOiJSUzI1NiIsImtpZCI6IjYwM0dGMkdLcjhrQzg1ZjVpSC1wZVVQaDQzcTdPUWVKeS00Y05TazNteGsifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4ta2RuNzgiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiZTBkZWRiOTMtZWJhOC00ZjdmLWE2NjUtMGMzMmExM2Q0ZTYzIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.r7IlTPsIzp86eloi7XIh9OPV203pyrXyzLewFKtZFshqEA3FbxJ4T7FztRKTyD_tLVDxpBMVruCJ9vK3RhOV0E6SnX4Frf4dofZt6KeUzGq89nCLr4edYlmHzAcx56QLK9cYLFF2AOxYUh6CloyZbUhiiNET_OQzG68VT2tLvrSHiVELe4hriQFgEfwAe-P-jGy-2xlmbPb7nk0tCRKBe1BDCktC9FvdMqBtS9BN3sRSOoDGuNga5W5Db0r-DTNxOcn3IgHUsQasDK7IW-J-6Ju_sul5NQ9MPfjuN6rWeuDU1iDSC0m-lomXjjfgB_UZ1r7d4DmilOgHKPTbOEE-zg
kubectl delete serviceaccount dashboard-admin -n kubernetes-dashboard
kubectl delete clusterrolebinding dashboard-admin
使用输出的token登录Dashboard。
访问地址:https://NodeIP:30001,这里就是https://192.168.172.31:30001/#/login
如果chrome显示你的连接不是私密连接,可以在此页面直接输入thisisunsafe。这样就会出现下面的界面了。
