以下是自己对高并发的一些理解
volatile
定义:将volatile声明的变量作为共享变量,存到了共享内存中,线程会将这个变量缓存到自己的线程内存中,对于volatile修饰的变量,任意线程总会对该变量的最后的修改(写入)总是可见的。java内存模型(JMM)会保证所有线程看到的这个变量是一致的。
volatile 是jvm 级别的语义,汇编代码会假如#lock 这样的命令,来通知cpu 实现数据的一致,有2中方式 一个是对cpu总线加锁,这样效率不高,2 利用缓存一致性原则,声明缓存在自己线程中的数据为无效,线程需要重新从共享内存中获取,修改。
他能保证:可见性和volatile的单个变量的原子性,对于一些volatile变量的复合操作 i++ 和 a+b 不能保证原子性。因为他的语义只能保证临界区代码的原子性。包括64位的long和double类型。
有序性。 volatile会对变量的读写前后加内存屏障,保障volatile语义的有序性。
可以实现线程的通信。
(可见性)当线程a 修改volatile变量i后,会将变量i的值,写回到共享内存中,cpu通过缓存一致性的原则,通知其他变量缓存的volatile变量的值为无效。cas无锁更新共享内存里的volatile变量。其他线程就可以看到更新后的volatile变量最后的改动。本质上可以理解为线程的通信。
正因为只有改动volatile单个变量,才会引起cpu的缓存一致性,所以在实现i++时,其他线程可能无法感知到i++这个过程。(i++,这个过程可以拆分为三步
1. tmp = i;
2 tmp = tmp+1;
3 i = tmp;)因为第二步,无法保证数据一致。所以可能在tmp+1这个步骤中,会导致多线程中数据的结果不一致。
volatile 是实现 LOCK 的关键。
synchronized
用来修饰 同步块和同步代码。保证在同一时间只能有一个线程进入到同步块/方法中。具有排他性。 是个隐式锁。他会自动获取释放锁。包括锁的重入。弊端就是不够灵活。不能实现锁的中端响应 和超时获取。
和volatile一样,是个关键字,是jvm级别的语义。 分为偏向锁,轻量锁,重量锁。 锁可以升级 和降级。
支持重入,获取到锁后,在获取锁,最后会自动递归的释放锁。
默认是非公平锁。
原子性
1cpu级别的原子一致性
通过总线锁保证原子性。当前锁在操作数据时,其他线程会被阻塞在外。效率低。
通过缓存一致性。
2java实现原子性 CAS算法
cas算法注意事项, 经典案例 ABA问题 ,通过加版本号来实现。cpu会一致循环 在尝试更新变量,cpu开销大。 只能保证一个共享变量的原子性。
锁
有意思的是除了偏向锁。其他全部使用了cas算法。
线程间的通信
volatile ,synchronized 都可以实现。
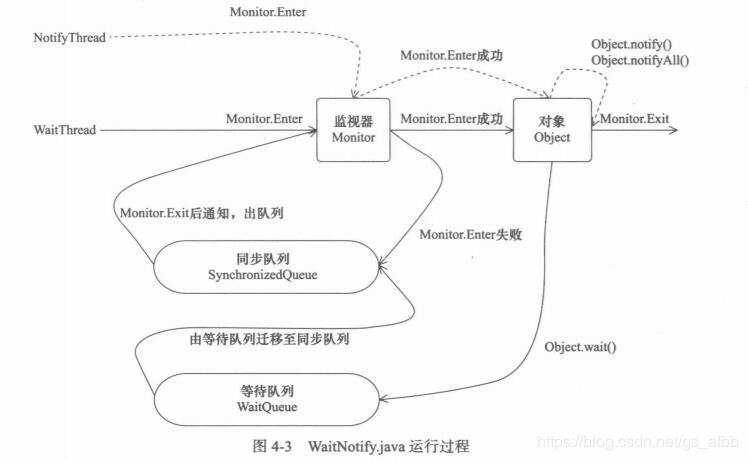
任意一个对象都有一个监视器。当调用synchronized时,本质是在获取对象的监控器,线程本身是不知道哪个线程获进入了同步代码,线程只能知道锁被人占用。如果没有获取到对象身上的监视器,就会阻塞在同步块或同步方法入口处,进入同步队列。变为BLOCK状态。
当获取锁的线程释放(object的前驱),就会激活同步队列里的线程,重新尝试对 对象监视器的获取。
这样的话,会一直在尝试获取对象的监视器,1cpu开销大,2也不能保证及时性 提出了等待/通知机制,
等待通知机制 并不等于 synchronized
等待通知的实现方式有2种,
1 Object.wait(),notify(),notifyAll() + synchronized 来实现,调用wait() 和notify()需要先对他进行加锁。只有一个同步队列和等待队列
伪代码:synchronized(object){
object.lock();
object.notify();
}
2 LOCK.lock(),unlock()+Condition 来实现 有一个同步队列和多个等待队列。
※引出一个问题:为什么wait(),notify(),notifyAll()方法要定义在 Object类里,而不是在Thread 里。
理解: 1.等待/通知机制 是任意一个对象都具有的,因为定义在Object类。任意一个对象都有同步队列和等待队列。
2.wait()和notify()重要的是实现等待/通知机制,不仅仅是同步方法。
3.每个对象都可以上锁。先对对象进行synchronized加锁,然后调用wait()方法和notify()来实现等待/通知。
4.获取锁本质是获取对象上的监视器,如果定义在Thread里,会对另一个线程造成入侵,如Thread 里的 suspend(),stop(),resume(),已被设置为过时,因为他会创建一个线程操作另外一个线程,而且资源不会释放,容易引发死锁等问题。
Lock
锁是用来控制多个线程访问共享资源的方式。
特点:缺少像synchronized这样的隐式获取和释放锁的便捷。但是拥有了锁获取与释放的可操作性。可中断的获取锁。超时获取锁等synchronized 不具备的特点。
锁的实现 是依赖于队列同步器AQS(AbstractQueuedSynchronized),AQS是实现Lock 的关键。
有公平锁和非公平锁,默认非公平锁,因为非公平锁效率更改,减少线程间的上下文切换。
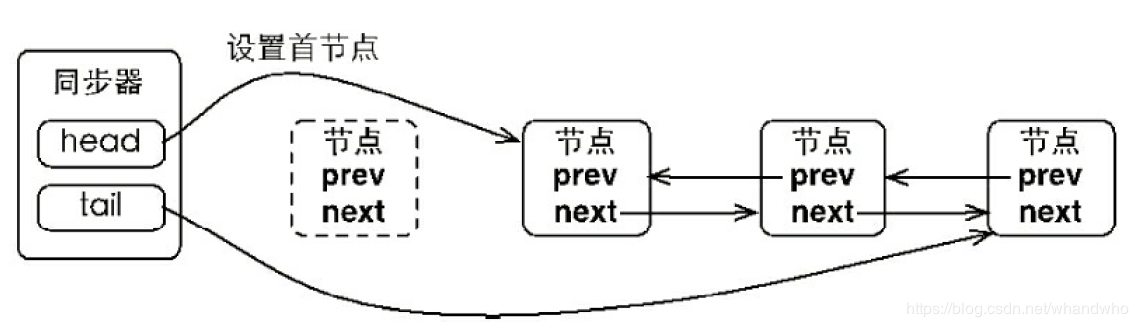
同步队列:
尾结点的加入需要通过cas算法,携带自己认为的尾结点和自己本身的节点,去队列里添加,不是就更新,是的话就成功添加了
头结点不需要 cas算法,因为已经确定了
这里涉及到一个理解:公平和非公平
-
加锁 :当一个线程请求锁时,发现锁已经被其他线程占用,那么就会创建一个代表自己的Node节点,然后加入到同步队列的尾部(这2个动作通过AbstractQueuedSynchronizer的addWaiter方法执行),这时候这个Node节点就变成了同步队列中的一个新尾节点,同时会将它的前置节点也就是之前的尾节点的waitStatus设置为-1(Node.SIGNAL:这个状态表示拥有这个状态的节点再释放锁后要唤醒它的后继节点),然后这个线程被挂起。
-
解锁:线程调用unlock方法进行解锁,首先会将state重设为0,然后设置非拥有锁(exclusiveOwnerThread = null),执行操作成功后,每次都会从同步队列的头部开始检查head节点的waitStatus是否为-1,如果为-1,则表示后续有需要唤醒的线程,当前线程会把head节点的waitStatus重设回0,然后唤醒head的后继节点所代表的线程,执行完毕,解锁成功
-
被唤醒的线程重新加锁:解锁成功后head节点的后继节点锁代表的线程被唤醒, 它会重新申请获取锁,此时因为上一个加锁的线程已经释放锁,所以当前state为0,被唤醒的线程会尝试将state为1,重设成功之后(因为此时可能有其他新来的线程与它争抢),当前线程会把代表自己的Node节点设置为新head节点,同时解除与原head节点的关系(设置原head节点的next属性值为null),重新获取锁成功。
公平锁的实现机理在于每次有线程来抢占锁的时候,都会检查一遍有没有等待队列 非公平锁在实现的时候多次强调随机抢占 与公平锁的区别在于新晋获取锁的进程会有多次机会去抢占锁。如果被加入了等待队列后则跟公平锁没有区别。
等待队列
不需要进行cas算法,因为本身已经获取到了lock,本省就是线程安全的,lock.lock()后用 await()方法,进入等待队列,所以不需要cas进行校验。先加入到等待队列才会进行锁的释放,保证等待队列的安全。然后调用signal()方法,先要获取到锁,如果是非公平的,先和其他线程试着抢占共享资源,如果失败进入同步队列,然后用cas来更新同步队列尾结点。
多个等待队列是被new 出来的。