一、使用索引
1,索引类型
1、普通索引 普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件 (WHERE column=)或排序条件(ORDERBY column)(GROUP BY column)中的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如 一个整数类型的数据列)来创建索引。 2、唯一索引 普通索引允许被索引的数据列包含重复的值。比如说,因为人有可能同名,所以同一个姓名在同一个“员工个人资料”数据表里可能出现两次或更多次。 如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字UNIQUE把它定义为一个唯一索引。这么做的好 处:一是简化了MySQL对这个索引的管理工作,这个索引也因此而变得更有效率;二是MySQL会在有新记录插入数据表时,自动检查新记录的这个字段的值 是否已经在某个记录的这个字段里出现过了;如果是,MySQL将拒绝插入那条新记录。也就是说,唯一索引可以保证数据记录的唯一性。事实上,在许多场合, 人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。 3、主索引 在前面已经反复多次强调过:必须为主键字段创建一个索引,这个索引就是所谓的“主索引”。主索引与唯一索引的唯一区别是:前者在定义时使用的关键字是PRIMARY而不是UNIQUE。 4、外键索引 如果为某个外键字段定义了一个外键约束条件,MySQL就会定义一个内部索引来帮助自己以最有效率的方式去管理和使用外键约束条件。 5、复合索引 索引可以覆盖多个数据列,如像INDEX(columnA,columnB)索引。这种索引的特点是MySQL可以有选择地使用一个这样的索 引。如果查询操作只需要用到columnA数据列上的一个索引,就可以使用复合索引INDEX(columnA,columnB)。不过,这种用法仅适用 于在复合索引中排列在前的数据列组合。比如说,INDEX(A,B,C)可以当做A或(A,B)的索引来使用,但不能当做B、C或(B,C)的索引来使 用。
2,索引方法:(摘自高性能mysql)
Indexes are implemented in the storage engine layer, not the server layer. Thus, they are not standardized: indexing works slightly differently in each engine, and not all engines support all types of indexes. Even when multiple engines support the same index type, they might implement it differently under the hood.
B-Tree indexes
The general idea of a B-Tree is that all the values are stored in order, and each leaf page is the same distance from the root. Figure 5-1 shows an abstract representation of a BTree index, which corresponds roughly to how InnoDB’s indexes work. MyISAM uses a different structure, but the principles are similar.
A B-Tree index speeds up data access because the storage engine doesn’t have to scan the whole table to find the desired data. Instead, it starts at the root node(not shown in this figure). The slots in the root node hold pointers to child nodes, and the storage engine follows these pointers. It finds the right pointer by looking at the values in the node pages, which define the upper and lower bounds of the values in the child nodes. Eventually, the storage engine either determines that the desired value doesn’t exist or successfully reaches a leaf page.
Leaf pages are special, because they have pointers to the indexed data instead of pointers to other pages. (Different storage engines have different types of “pointers”to the data.) Our illustration shows only one node page and its leaf pages, but there may be many levels of node pages between the root and the leaves. The tree’s depth depends on how big the table is.
Because B-Trees store the indexed columns in order, they’re useful for searching for ranges of data. For instance, descending the tree for an index on a text field passesthrough values in alphabetical order, so looking for “everyone whose name begins with I through K” is efficient.
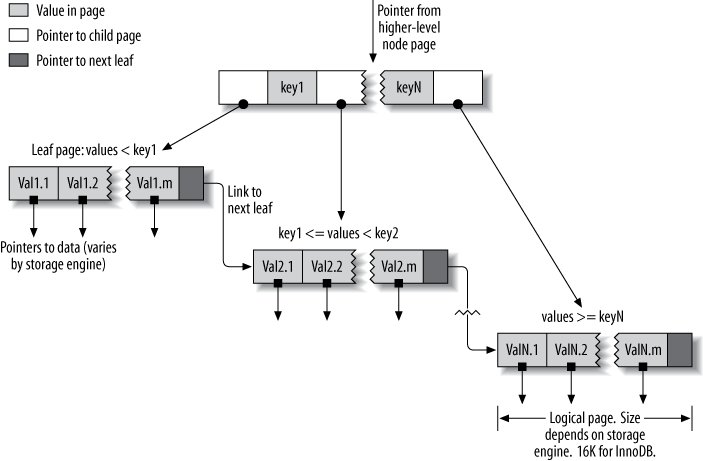 Figure 5-1. An index built on a B-Tree (technically, a B+Tree) structure
Figure 5-1. An index built on a B-Tree (technically, a B+Tree) structure
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) );
Types of queries that can use a B-Tree index. B-Tree indexes work well for lookups by the full key value, a key range, or a key prefix. They are useful only if the lookup uses a leftmost prefix of the index.
- Match the full value(全值匹配): A match on the full key value specifies values for all columns in the index. For example, this index can help you find a person named Cuba Allen who was born on 1960-01-01.
- Match a leftmost prefix(匹配最左前缀):This index can help you find all people with the last name Allen. This uses only the first column in the index.
- Match a column prefix(匹配列前缀):You can match on the first part of a column’s value. This index can help you find all people whose last names begin with J. This uses only the first column in the index.
- Match a range of values(匹配范围值):This index can help you find people whose last names are between Allen and Barrymore. This also uses only the first column.
- Match one part exactly and match a range on another part(精确匹配某一列并范围匹配另一列):This index can help you find everyone whose last name is Allen and whose first name starts with the letter K (Kim, Karl, etc.). This is an exact match on last_name and a range query on first_name.
- Index-only queries(只访问索引的查询:覆盖索引):B-Tree indexes can normally support index-only queries, which are queries that access only the index, not the row storage.
Because the tree’s nodes are sorted, they can be used for both lookups (finding values) and ORDER BY queries (finding values in sorted order). In general, if a B-Tree can help you find a row in a particular way, it can help you sort rows by the same criteria. So, our index will be helpful for ORDER BY clauses that match all the types of lookups we just listed.
Here are some limitations of B-Tree indexes:
- They are not useful if the lookup does not start from the leftmost side of the indexed columns. For example, this index won’t help you find all people named Bill or all people born on a certain date, because those columns are not leftmost in the index. Likewise, you can’t use the index to find people whose last name ends with a particular letter.
- You can’t skip columns in the index. That is, you won’t be able to find all people whose last name is Smith and who were born on a particular date. If you don’t specify a value for the first_name column, MySQL can use only the first column of the index.
- The storage engine can’t optimize accesses with any columns to the right of the first range condition. For example, if your query is WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23', the index access will use only the first two columns in the index, because the LIKE is a range condition (the server can use the rest of the columns for other purposes, though). For a column that has a limited number of values, you can often work around this by specifying equality conditions instead of range conditions. We show detailed examples of this in the indexing case study later in this chapter.
Now you know why we said the column order is extremely important: these limitations are all related to column ordering. For high-performance applications, you might need to create indexes with the same columns in different orders to satisfy your queries.
Some of these limitations are not inherent to B-Tree indexes, but are a result of how the MySQL query optimizer and storage engines use indexes. Some of them may be removed in the future.
Hash indexes
A hash index is built on a hash table and is useful only for exact lookups that use every column in the index.* For each row, the storage engine computes a hash code of the indexed columns, which is a small value that will probably differ from the hash codes computed for other rows with different key values. It stores the hash codes in the index and stores a pointer to each row in a hash table.
In MySQL, only the Memory storage engine supports explicit hash indexes. They are the default index type for Memory tables, though Memory tables can have B-Tree indexes too. The Memory engine supports nonunique hash indexes, which is unusual in the database world. If multiple values have the same hash code, the index will store their row pointers in the same hash table entry, using a linked list.
Here’s an example. Suppose we have the following table: CREATE TABLE testhash ( fname VARCHAR(50) NOT NULL, lname VARCHAR(50) NOT NULL, KEY USING HASH(fname) ) ENGINE=MEMORY; containing this data: mysql> SELECT * FROM testhash; +--------+-----------+ | fname | lname | +--------+-----------+ | Arjen | Lentz | | Baron | Schwartz | | Peter | Zaitsev | | Vadim | Tkachenko | +--------+-----------+ Now suppose the index uses an imaginary hash function called f( ), which returns the following values (these are just examples, not real values): f('Arjen') = 2323 f('Baron') = 7437 f('Peter') = 8784 f('Vadim') = 2458 The index’s data structure will look like this: Slot Value 2323 Pointer to row 1 2458 Pointer to row 4 7437 Pointer to row 2 8784 Pointer to row 3
As a result, lookups are usually lightning-fast. However, hash indexes have some limitations:
- Because the index contains only hash codes and row pointers rather than the values themselves, MySQL can’t use the values in the index to avoid reading the rows. Fortunately, accessing the in-memory rows is very fast, so this doesn’t usually degrade performance.
- MySQL can’t use hash indexes for sorting because they don’t store rows in sorted order.
- Hash indexes don’t support partial key matching, because they compute thehash from the entire indexed value. That is, if you have an index on (A,B) and your query’s WHERE clause refers only to A, the index won’t help.
- Hash indexes support only equality comparisons that use the =, IN( ), and <=>operators (note that <> and <=> are not the same operator). They can’t speed up range queries, such as WHERE price > 100.
- Accessing data in a hash index is very quick, unless there are many collisions(multiple values with the same hash). When there are collisions, the storage engine must follow each row pointer in the linked list and compare their values to the lookup value to find the right row(s).
- Some index maintenance operations can be slow if there are many hash collisions.For example, if you create a hash index on a column with a very low selectivity(many hash collisions) and then delete a row from the table, finding the pointer from the index to that row might be expensive. The storage engine will have to examine each row in that hash key’s linked list to find and remove the reference to the one row you deleted.
These limitations make hash indexes useful only in special cases. However, when they match the application’s needs, they can improve performance dramatically. An example is in data-warehousing applications where a classic “star” schema requires many joins to lookup tables. Hash indexes are exactly what a lookup table requires.
3,建立、删除索引(索引类型)
******最简单的一种,Navicat for mysql 直接创建
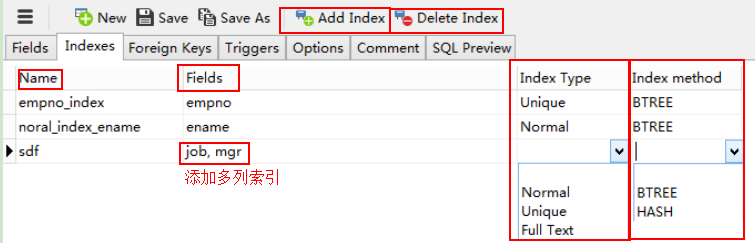
******用sql语句建立索引******
总方法:
ALTER TABLE table_name ADD index_type index_name (colunm) ALTER TABLE table_name ADD index_type index_name(column1,column2,column3) -- 添加多列索引 ALTER TABLE table_name DROP INDEX index_name -- 删除索引 CREATE index_type index_name ON table_name (colunm) CREATE index_type index_name ON table_name (column1,column2,column3) -- 添加多列索引 DROP INDEX index_name ON table_name -- 删除索引 1)主键索引:PRIMARY KEY:主键是默认添加,只是上面不显示 ALTER TABLE emp ADD PRIMARY KEY (emp_id) 2)唯一索引:UNIQUE ALTER TABLE emp ADD UNIQUE empno_index (empno) ALTER TABLE emp ADD UNIQUE INDEX empno_index(empno) -- INDEX 可以有可以没有 CREATE UNIQUE INDEX empno_index ON emp (empno) -- INDEX 必须有 注意:1)如果是column_list的话,比如:empno, ename要同时相同才能产生效果:唯一 3)普通索引:INDEX ALTER TABLE emp ADD INDEX noral_index_ename (ename) 4)全文索引 :FULLTEXT ALTER TABLE table_name ADD FULLTEXT (column)
4,关于sql优化
1、 索引要建立在值比较唯一的字段上,这样做才是发挥索引的最大效果,比如主键的id字段,唯一的名字name字段等等。如果索引建立在唯一值比较少的字段,比如性别gender字段,寥寥无几的类别字段等,刚索引几乎没有任何意义。 2、 对于那些定义为text、image和bit数据类型的列不应该增加索引。因为这些列的数据量要么相当大,要么取值很少。 3、 当修改性能远远大于检索性能时,不应该创建索引。修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引(即:经常更新的字段不适合加索引)。 4、 在WHERE和JOIN中出现的列需要建立索引。WHERE 里面的条件, 会自动判断,有没有 可用的索引,如果有, 该不该用。 5,出现在where条件里面的字段适合建索引,频繁作为查询条件的字段适合加索引。
6,on、where、having这三个都可以加条件的子句中,on是最先执行,where 次之,having 最后,因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,where 也应该比having快点的(所以为什么要在on条件之后加索引) 1,用join代替子查询,减少临时表的使用 1,使用连接查询(JOIN)来代替子查询(Sub-Queries,就是说不要IN),之所以更有效率一些,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。IN的话明显需要临时表 2,尽量不要SELECT * 查询全部,而是要查询相对应的部分字段就可以了即使是查询全部,也不要用*,因为数据库还要解析这个*号呢 3,避免不带任何条件的SQL语句的执行。 4、SQL语句用大写因为数据库总是先解析sql语句,把小写的字母转换成大写的再执行。 5、优化HAVING字句,GROUP BY(where 执行在groupby 之前,having执行在groupby之后,groupby以及orderby本来就会导致全表查询,所以其性能可想而知)避免使用HAVING 子句, HAVING 只会在groupby检索出所有记录之后才对结果集进行过滤.这个处理需要排序,总计等操作。如果能通过WHERE 子句限制记录的数目,那就能减少这方面的开销 低效: SELECT JOB,AVG(SAL)FROM EMP GROUP BY JOB HAVING JOB= 'PRESIDENT' OR JOB ='MANAGER' 高效: SELECT JOB,AVG(SAL)FROM EMP WHERE JOB ='PRESIDENT'OR JOB='MANAGER' GROUPby JOB 6、别名是大型数据库的应用技巧,就是表名、列名在查询中以一个字母为别名,查询速度要比建连接表快1.5倍。 7,选取最适用的字段属性。MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了。同样的,如果可以的话,我们应该使用MEDIUMINT而不是BIGINT来定义整型字段。 另外一个提高效率的方法是在可能的情况下,应该尽量把字段设置为NOTNULL,这样在将来执行查询的时候,数据库不用去比较NULL值。对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。这样,我们又可以提高数据库的性能。
5,聚集索引
1,myisam引擎没有聚集索引概念,innodb默认主键是聚集索引,如果没有逐渐则非空的索引是聚集索引,如果都没有则生成一个隐藏列为聚集索引 2,聚集索引不是一种单独的索引类型,而是一种存储数据方式。其具体细节依赖于实现方式,但是InnoDB的聚集索引实际上在同样的结构中保存了B-Tree索引和数据行。 3,当表有聚集索引的时候,它的数据行实际保存在索引的叶子页中。术语“聚集”指实际的数据行和相关的键值都保存在一起。每个表只能有一个聚集索引,因为不能一次把行保存在两个地方。(但是,覆盖索引可以模拟多个聚集索引)????
四、分区分表
一个庞大的数据表,我们可以添加索引来优化查询速度,如果加了索引效果还不好,这时候我们就采用分表和分区技术来做。
一般当单表的数据超过1000w条时,我们就要分表来提高速度。(这个1000w待验证)
为什么要分表和分区?
日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表。这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕。分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率。
什么是分表?
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,我们可以称为子表,每个表都对应三个文件,MYD数据文件,.MYI索引文件,.frm表结构文件。这些子表可以分布在同一块磁盘上,也可以在不同的机器上。app读写的时候根据事先定义好的规则得到对应的子表名,然后去操作它。
什么是分区?
分区和分表相似,都是按照规则分解表。不同在于分表将大表分解为若干个独立的实体表,而分区是将数据分段划分在多个位置存放,可以是同一块磁盘也可以在不同的机器。分区后,表面上还是一张表,但数据散列到多个位置了。app读写的时候操作的还是大表名字,db自动去组织分区的数据。
如:某用户表的记录超过了600万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区。当然也可根据其他的条件分区。
mysql分表和分区有什么联系呢?
1.都能提高mysql的性高,在高并发状态下都有一个良好的表现。
2.分表和分区不矛盾,可以相互配合的,对于那些大访问量,并且表数据比较多的表,我们可以采取分表和分区结合的方式(如果merge这种分表方式,不能和分区配合的话,可以用其他的分表试),访问量不大,但是表数据很多的表,我们可以采取分区的方式等。
3.分表技术是比较麻烦的,需要手动去创建子表,app服务端读写时候需要计算子表名。采用merge好一些,但也要创建子表和配置子表间的union关系。
4.表分区相对于分表,操作方便,不需要创建子表。
附:查看总数据库大小、单张数据库大小、以及其单张表大小
(记得一定要按顺序来)
1、进入information_schema 数据库(存放了其他的数据库的信息)
use information_schema;
2、查询所有数据的大小:
select concat(round(sum(data_length/1024/1024),2),'MB') as data from tables;
3、查看指定数据库(vishnusit2)的大小:
select concat(round(sum(data_length/1024/1024),2),'MB') as data from tables where table_schema='vishnusit2';
4、查看指定数据库(vishnusit2)的某个表的大小(pool_sanstorage_host_lun)
select concat(round(sum(data_length/1024/1024),2),'MB') as data from tables where table_schema='vishnusit2' and table_name='pool_sanstorage_host_lun';