定位方式选择:
1. 当页面元素有id属性时,最好尽量用id来定位。但由于现实项目中很多程序员其实写的代码并不规范,会缺少很多标准属性,这时就只有选择其他定位方法。
2. xpath很强悍,但定位性能不是很好,所以还是尽量少用。如果确实少数元素不好定位,可以选择xpath或cssSelector。
3. 当要定位一组元素相同元素时,可以考虑用 tagName 或 name。
4. 当有链接需要定位时,可以考虑 linkText 或 partialLinkText 方式。
❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀ 1.id 方式定位(By.id)
如百度页面:findElement(By.id("kw"));
❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀ 2.name方式定位(By.name)
如百度页面:findElement(By.name("wd"));
❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀ 3.标签名称定位(By.tagName)
如百度页面:findElement(By.tagName("input"));
标签名称 主要用于匹配多个页面元素的情况。 使用当要定位一组元素相同元素时,可以考虑用tagName或name
将查找到的元素对象进行计数、遍历、修改属性值
By.tagName("input")
By.tagName("label")
By.tagName("button")
......
❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀ 4.Class名称定位(By.className)
如百度页面:findElement(By.className("s_ipt"));
❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀ 5.链接文字定位(By.linkText() 、By.partialLinkText() )
通过超文本链接上的文字信息来定位元素,这种方式一般专门用于定位页面上的超文本链接
使用By.partialLinkText()方法进行定位时,可能会引起的问题是,当你的页面中不止一个超链接包含About时,findElement方法只会返回第一个查找到的元素,而不会返回所有符合条件的元素。如果你要想获得所有符合条件的元素,还是只能使用findElements方法。
❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀ 6. CSS定位:(By.cssSelector)
<span class="sp">
<input id="abc" name="def" class="ghi" type="text" maxlength='100' />
</span>
通过class属性定位:findElement(By.cssSelector(".ghi"));
通过id属性定位:findElement(By.cssSelector("#abc"));
通过标签名定位:findElement(By.cssSelector("input"));
通过父子关系定位: findElement(By.cssSelector("span > input"));
通过属性定位:findElement(By.cssSelector("input[maxlength='100']"));
注:各种浏览器对xpath的支持情况不一样,像IE就差点,会出现xpath在一个浏览器能定位到但在另一个浏览器定位不到的问题
❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀ 7.Xpath定位 (By.xpath)
(1)xpath路径定位:
绝对路径以单/号表示。当xpath的路径以/开头时,表示让Xpath解析引擎从文档的根节点开始解析。当//出现在xpath路径中时,表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级
相对路径则以//表示。当xpath路径以//开头时,则表示让xpath引擎从文档的任意符合的元素节点开始进行解析。而当/出现在xpath路径中时,则表示寻找父节点的直接子节点,
(2)xpath工具辅助定位:
a.chrome浏览器,安装Xpath-helper 。快捷键 ctrl+shift+x可以唤起xpath-helper框 (按住shift,并移动到指定区域,可以查找xpath)
b.chrome浏览器,F12--Elements 区域--通过指针选中指定元素--右击 --copy--xpath
c.Firefox浏览器,打开firebug
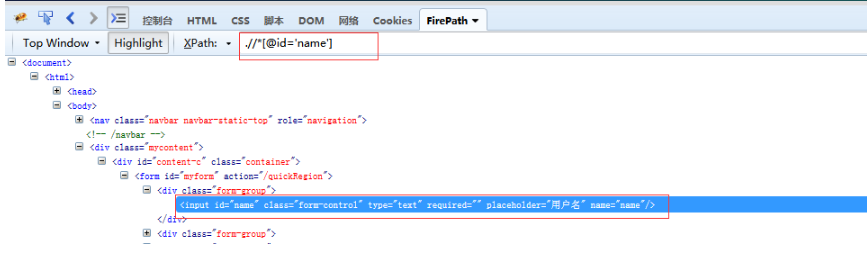
(3)动态元素定位 ex:
1.通过元素索引定位: By.xpath("//input[9]")
2.使用xpath多个属性定位 :By.xpath("//input[@id='kw1']")
By.xpath("//input[@type='name' and @name='kw1']")
4.使用部分属性值匹配(最强大的方法)
By.xpath("//input[start-with(@id,'file')
By.xpath("//input[ends-with(@id,'_11')
By.xpath("//input[contains(@id,'_')]")
5.通过查找动态id的规律,来获取id 并定位元素 。详见
6.通过获取xpath父节点(..),定位其哥哥节点(div[1]): By_xpath("//div[@id='D']/../div[1]")
(4)模糊匹配模式定位
a. contains关键字:
driver.findElement(By.xpath(“//a[contains(@href, ‘logout’)]”));
这句话的意思是寻找页面中href属性值包含有logout这个单词的所有a元素,由于这个退出按钮的href属性里肯定会包含logout,所以这种方式是可行的,也会经常用到。其中@后面可以跟该元素任意的属性名。
b. start-with:
driver.findElement(By.xpath(“//a[starts-with(@rel, ‘nofo’)]));
这句的意思是寻找rel属性以nofo开头的a元素。其中@后面的rel可以替换成元素的任意其他属性。
c. Text关键字:
driver.findElement(By.xpath(“//*[text()=’退出’])); 。
直接查找页面当中所有的退出二字,根本就不用知道它是个a元素了。这种方法也经常用于纯文字的查找。
d.超链接元素的文本内容,也可以用driver.findElement(By.xpath(“//a[contains(text(), ’退出’)]));
用于知道超链接上显示的部分或全部文本信息时,可以使用。
XPath与CSS的 功能的简单对比如下表所示
| 描述 | Xpath | CSS Path |
|---|---|---|
| 标签 | //div | div |
| 直接子元素 | //div/a | div > a |
| 子元素或后代元素 | //div//a | div a |
| 以id定位 | //div[@id=’idValue’]//a | div#idValue a |
| 以class定位 | //div[@class=’classValue’]//a |
div.classValue a 注:class值中有空格,可以用.代替空格,详见 |
| 同级弟弟元素 | //ul/li[@class=’first’]/following-sibling::li | ul>li.first + li |
| 属性 | //form/input[@name=’username’] |
form input[name=’username’] div[title=Move mouse here] |
| 多个属性 | //input[@name=’continue’ and @type=‘button’] | input[name=’continue’][type=’button’] |
| By index | //li[6] | li:nth(5) |
| 第4个子元素 | //ul[@id=’list’]/li[4] |
ul#list li:nth-child(4) 是li标签,且是第4个元素 ul#list li:nth-of-type(4) 父标签下第4个li元素 ,区别详见 |
| 第1个子元素 | //ul[@id=’list’]/li[1] | ul#list li:first-child |
| 最后1个子元素 | //ul[@id=’list’]/li[last()] | ul#list li:last-child |
| 属性包含某字段 | //div[contains(@title,’Title’)] | div[title*=”Title”] |
| 属性以某字段开头 | //input[starts-with(@name,’user’)] | input[name^=”user”] |
| 属性以某字段结尾 | //input[ends-with(@name,’name’)] | input[name$=”name”] |
| text中包含某字段 | //div[contains(text(), ‘text’)] | 无法定位 |
| 元素有某属性 | //div[@title] | div[title] |
| 父节点 | //div/.. | 无法定位 |
| 同级哥哥节点 | //li/preceding-sibling::div[1] | 无法定位 |
| 同级弟弟节点 |
//li/followding-sibling::div[1] ps: following-sibling获取当前节点的所有弟弟节点. |
无法定位 |
Xpath 与CSS 定位比较:
xpath定位时采用遍历页面的方式,在性能上CSS locator比XPath locator速度快,采用CSS选择器的方式更优,特别是在IE下面(IE没有自己的XPath 解析器(Parser))。
Xpath虽然性能指标较差,但是在浏览器中有比较好的插件支持,定位元素比较方便,对于性能要求严格的场景,可考虑通过xpath改写css的方式进行替换
❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀❀❀ ❀❀ frame 的定位切换,详见