一、问题现象
top 命令查看显示服务器负载情况,服务器负载1.31,而且长时间没降下去,CPU使用率99.9%也异常飚高
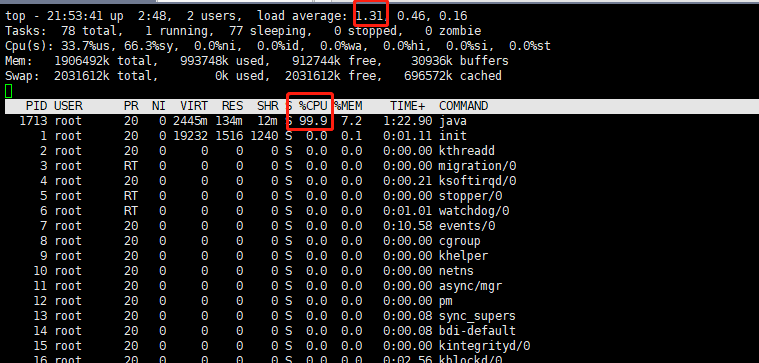
load average :系统平均负载均值,三列分别代表 1分钟、5分钟、15分钟。理论上,值越小越好。负载越高,说明可能跑的程序出现异常情况。
一般,如果只是 1 分钟内的负载比较高,其他两个负载参数较低, 这说明是暂时现象,问题不大。如果5分钟、15分钟负载都超过 1 的话,那就要考虑程序方面的问题了。
CPU使用率:有 10 个开发任务,4名开发人员,但是 10个任务都分配给一个人了,那么此时的CPU使用率为 25%,负载非常高。
CPU平均负载:负载就是cpu在一段时间内正在处理以及等待cpu处理的进程数之和的统计信息,也就是cpu使用队列的长度统计信息,这个数字越小越好(如果超过CPU核心*0.7就是不正常)。
高速入口,系统负载为0,此时没车,收费员闲着。负载0.5,一半的车流了,收费员比较闲。负载1,满负荷,没时间歇着了。负载1.5,车队已经排到500米开外了,没得歇。负载越高,过站时间越长。
二、查看分析
1、磁盘空间 df -l ,空余足,无问题

2、内存使用情况 free ,剩余充足

3、服务流量问题,由于是本地测试程序,无外部突发的高并发访问,排除。
4、JVM内存情况
4.1、 jmap -heap PID,无GC异常
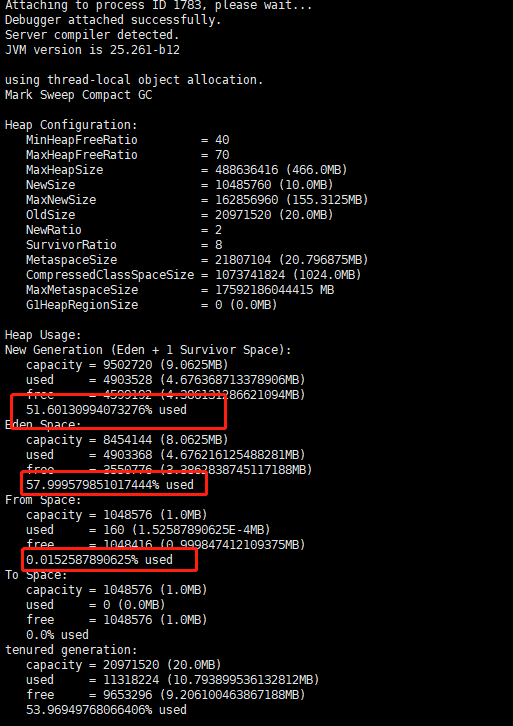
4.2、GC实时执行情况 jstat -gc PID 5000 ,每五秒输出一次GC情况。无频繁FGC情况,排除。

S0C / S1C:年轻代 Survivor 区容量
S0U / S1U:年轻代 Survivor 区使用量
EC / EU :年轻代 Eden 区容量 / 使用量
OC / OU :Old老年代容量 / 使用量
MC / MU :Metaspace 元空间初始大小 / 使用量
YGC / YGCT :程序启动到采样时的年轻代GC次数 / 耗时
FGC / FGCT:程序启动到采样时的老年代GC次数 / 耗时
5、查看运行中的Java程序进程
5.1、查看异常CPU使用率进程
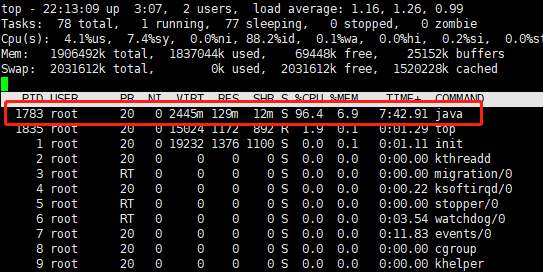
5.1、导出异常飚高的PID对应的线程快照信息, jstack -l PID > /opt/apps/12001/12001.stack
5.2、查看对应进程中哪个线程占用异常过高, top -H -p PID

5.3、对应线程PID十进制转为十六进制, printf "%x " PID

5.4、下载 5.1 中的快照文件到本地,或者直接查找文件内容 grep -C20 6f8 12001.stack

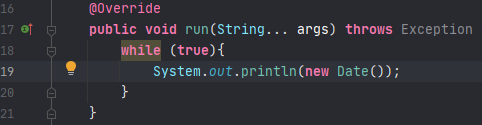
5.5、根据对应信息,去程序中查看,这里使用的是本地测试程序,线程一直RUNNABLE,程序中while无限循环,即为问题所在。
6、CPU使用率低负载高
原因:等待磁盘I/O完成的进程过多,导致进程队列长度过大,但是CPU运行的进程却很少,这样就体现到负载过大了,CPU使用率低。