node.js模块
在node.js开发中一个文件就可以认为是一个模块。
一、node.js模块分类
核心模块Code Module、内置模块、原生模块
fs
http
path
url
...
所有内置模块在安装node.js的时候就已经编译成二进制文件,可以直接加载运行(速读较快)
部分内置模块,在node.exe这个进程启动的时候就已经默认加载了,所以可以直接使用。
文件模块
按文件后缀来分
如果加载时,没有指定后缀名,那么就按照如下顺序依次加载相应模块
1.js
2.json
4.node(C/c++编写模块)
自定义模块
mime
cheerio
moment
mongo
...
二、加载顺序
1.require(一个路径)
require('./index2') //index2.js //index2.json //index2.node //index2文件夹->package.json文件->main(入口文件 app.js->index.js/index.json/index.node)->加载失败
在加载index2的时候,require会先去找index2.js文件,没有就去找.json文件,再没有就找node文件,如果这些都没有,它会认为index2是一个文件夹,如果找到了这个文件夹,require还会去找这个文件夹里面是否有package.json,如果没有就加载失败,如果有,就找package.json里的main(),就加载里面的index.js/index.json/index.node,如果没有,也是失败。
在加载文件模块的时候最好写上后缀,这样会省一些步骤
2.require()的参数不是一个路径,直接是一个模块名称
1).现在核心模块中查找,是否有名字一样的模块,如果有,则直接加载该核心模块
如:require('http')
2)如果核心模块中没有该模块,就很认为是一个第三方模块(自定义模块)
先会去当前js文件所在的目录下找node_modules文件夹,当前目录没有,会去当前执行的文件的父目录里面寻找
三、require加载注意事项
1.所以模块第一次加载完毕以后都会有缓存,第二次加载直接读取缓存,避免了二次开销
因为有缓存,所以模块中的代码只在第一次加载的时候执行一次
2.每次加载模块的时候都有限从缓存中加载,缓存中没有才会按照node.js加载模块规则去查找
3.核心模块Node.js源码编译的时候,都已经编译为二进制执行文件,所以加载速度较快(核心模块加载优先级仅次于缓存加载)
4.试图加载一个和核心模块同名的自定义(第三方模块)是不会成功的
自定义模块要么名字不要和核心模块同名,要么使用路径的方式加载
6.核心模块只能通过模块名称来加载
7.require()加载模块使用./相对路径时,是先对当前模块,不受node命令执行路径影响
8.建议在加载文件模块时,尽量添加文件后缀名
四、require加载原理

在a.js文件中
//加载b.js模块 require('./b.js');
在b.js文件中
function add(x,y){ return x+y; } var result=add(100,1000); console.log(result);
执行a.js

加载自定义模块b.js的时候,会执行一次b.js
修改a.js
//加载b.js模块 require('./b.js'); require('./b.js'); require('./b.js'); require('./b.js'); require('./b.js'); require('./b.js');
执行a.js

由此可见,require模块第一次加载会执行模块代码,后面加载的模块都是从缓存里面获取的,所以不会再去执行模块代码了。
在文件中查找第三方模块时依次查找的路径
console.log(module.paths);

源代码
1.检查Module.cache里有没有缓存的模块实例,如果缓存里面没有,就创建一个Module实例,将创建的Module保存到缓存里面,供下次使用
2.调用module.load()读取模块内容,然后调用modele.compile()编译执行(封装为一个沙盒)改模块
3.如果加载出错,就从缓存中删除该模块
4.返回module.export
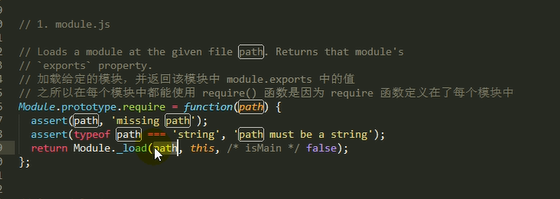
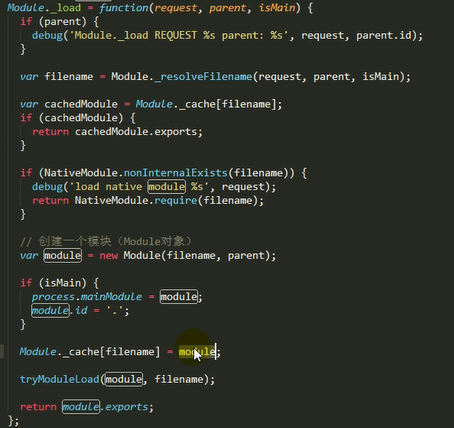
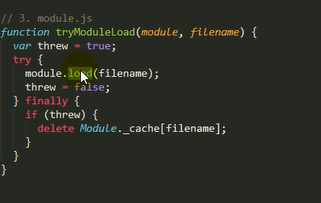
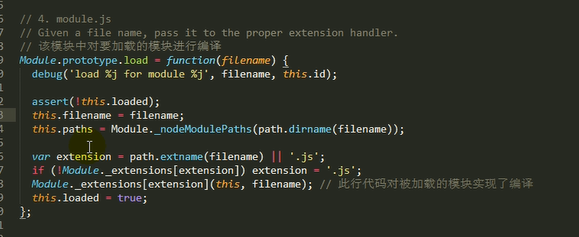
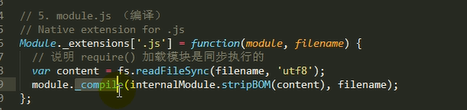

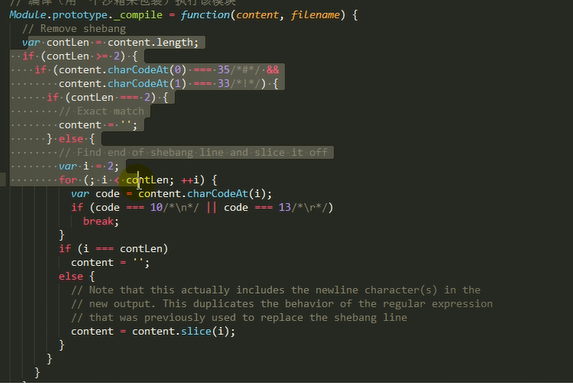
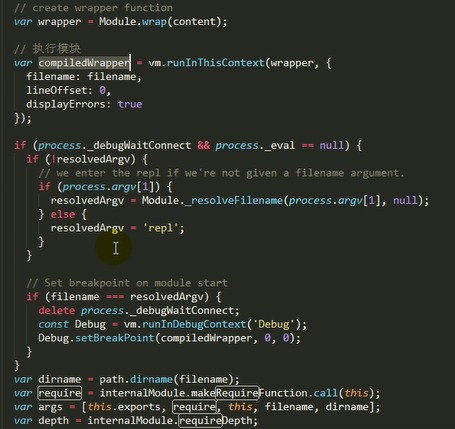

主要做的是通过module._load来加载模块,判断缓存,如果没在缓存里就创建