1. TDIDT:找到最佳decision attribute,然后将数据分开
如ID3,所选attribute一定是categorical attributes(yes,no等), 不能是数值型的
另一个方法为CaRT,这节课不做太多涉及
2. ID3的选取原则为测算entropy:数据混乱程度;分类很好时entropy为0,0.5时为1
分类时即将high entropy转化为lowentropy,引入information gain的概念来衡量entropy的降低,即原始set的entropy与经过classification之后entropy的差值
选取information gain最大的attribute,以此进行划分
3. information gain的局限性在于有的attribute里面划分的情况更多,故而更有可能达到更小的entropy,故而引入splitEntropy, 从而将attribute的分类也考虑在里面
4. decision tree的overfitting:如果对参与training的点来说,training set的error比entire set的error小;而对没有参与training的点来说,training set的error比entire set的大
解决的方法是pruning,pre-pruning指符合条件时停止growing(只选取一部分attribute,或者分类没有完全结束的时候就停下来。其他方法有限制leaf node的个数等),post-pruning指完成后删掉一部分(用training构成完整树之后,用validation检测,去掉错误率反而升高的brunch;mini error每构建一层树就进行一次检测,用cross-validation;smallest tree指建造树的过程中记录准确率,找到符合想要的准确度条件下最小的tree)
5. tree to rules
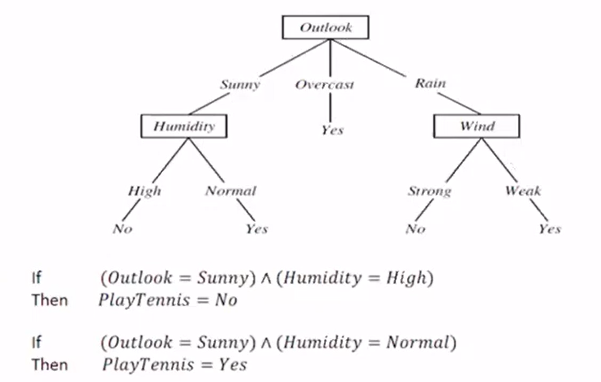
6. 对数值而言,我们按照大小做出来class table,在正负之间做出划分,从而进行classification
7. 若training set过大我们可以建立window,如有1000个数据,用100个做出tree,然后检测剩下900,将错误的重新加入1000个里面,然后重新建立tree
8. regression tree:split之后用均值代表这一class中的值,然后每一class中算出MSE,希望MSE越小越好,然后求加权平均。按照最小的进行split
9. model tree:不断split直到我们认为可以对所有部分进行linear regression,使每一段的标准差尽可能小(SDR)