今天有缘看到董西成写的《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》,翻了翻觉得是很有趣的而且把hadoop讲得很清晰书,就花了一下午的时间大致拜读了一下(仅浏览了感兴趣的部分,没有深入细节)。现把觉得有趣的部分记录如下。
JobControl
把各个job配置好后,放入JobControl中,JobControl会根据它们之间的依赖关系,分别进行调度。
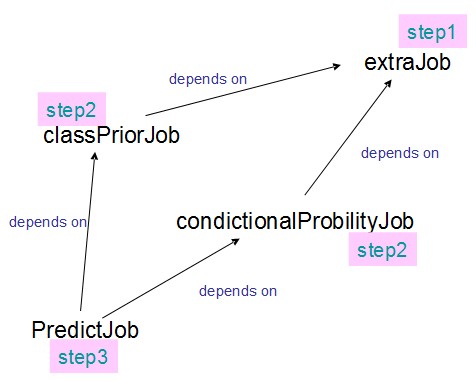
工作流引擎
除了JobControl外,还可以使用Oozie和Azkaban来进行工作流控制。相较于前者而言,Oozie和Azkaban可以使用图形化界面观看工作流的处理进度,另外还有其他更丰富的功能。
JobTracker
(Master)
是一个后台服务程序,启动后会一直监听并接收来自各个TaskTacker发送的心跳信息。心跳信息中包含节点资源的使用情况和任务运行情况。
作业控制:JobTracker在其内部以“三层多叉树”的方式描述和跟踪每个作业的运行状态。

当任何一个Task Attemp运行成功后,其上层对应的TaskInProgress会标注该任务运行成功;而当所有的TaskInProgress运行成功后,JobInProgress会标注整个作业运行成功。
JobTracker如何查找和定位各种对象?
为了查找和定位各种对象,JobTracker将相关信息封装成各种对象后,以key/value的形式保存到Map结构中。(在JDK中,Map以红黑树来实现)
1、作业ID查找对应的JobInProgress对象
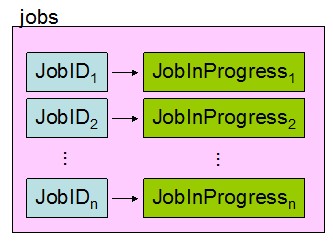
2、查找每个TaskTracker上运行的task

JobTracker的各种 操作(如监控、更新),实际上就是修改这些Map关系。
不过JobTracker存在单点故障(因为是Master/Slave结构)。如果已保存的任务或节点状态丢失,则所有正在运行的作业将会失败。
TaskTracker
(slave)
①运行于各个节点上的服务
②是JobTracker与Task之间的沟通桥梁,在两者间使用RPC进行通信。
对JobTracker和TaskTracker而言,前者为server,后者为client。
对TaskTracker和Task而言,前者为server,后者为client。
③执行两个功能:汇报心跳和执行命令
Hadoop对快排的优化
(1)轴枢选择
Hadoo将序列的首尾和中间元素的中位数作为轴枢,以避免出现极端不对称子序列的情况。(极端不对称子序列会导致快排算法的退化)
(2)子序列的划分
使用两个索引 i 和 j 分别从左右两端对序列进行扫描,并让索引i扫描到大于等于轴枢的元素停止,j扫描到小于等于轴枢的元素停止,然后交互两个元素(交换时索引不动),重复这个过程知道i和j相遇。
(3)对相同元素的优化
在每次划分子序列时,将与枢轴相同的元素集中存放在中间位置,让它们不再参与后续的递归处理,即将序列划分为三部分:小于轴枢、等于轴枢、大于轴枢。(这也是由于hadoop排序中会出现大量相等值的原因,这样做可以通过减少递归排序的数量从而提高算法的效率)
(4)减少递归次数
当子序列中元素数目小于13时,直接使用插入排序算法,不再使用递归。
第一代MapReduce框架的局限性
①扩展性差
JobTracker兼具资源管理和作业控制两个功能,因此成为系统性能扩展的最大瓶颈。
②单点故障
master/salve结构的通病
③资源利用率低
因为使用slot为资源分配模型,但slot粒度大,而且MapSlot和ReduceSlot不能share,因而会出现一种slot资源紧张而另一种空闲的尴尬状况。
④无法支持多种计算框架
几种比较vogue的框架有:
MapReduce:支持离线处理,可以被搜索引擎公司用于建立网页索引。
Storm:支持在线处理,tweeter使用的框架
Spark:迭代式计算框架,可以用于自然语言处理、数据挖掘,如PageRank计算、分类、聚类。对性能要求高的DM,可以使用MPI。
S4:流式处理框架,Yahoo。
而第一代的Hadoop只能支持MapReduce这一种计算框架。
互联网公司希望可以将这些框架统一用到自己的集群资源上,因此诞生了资源管理与调度平台,典型的代表有:
YARN(Apache),现可以运行MapReduce和Storm(今天才在InfoQ上看到的新闻)
Corona(Facebook)
Mesos(Berkeley)