Visual Metaphor

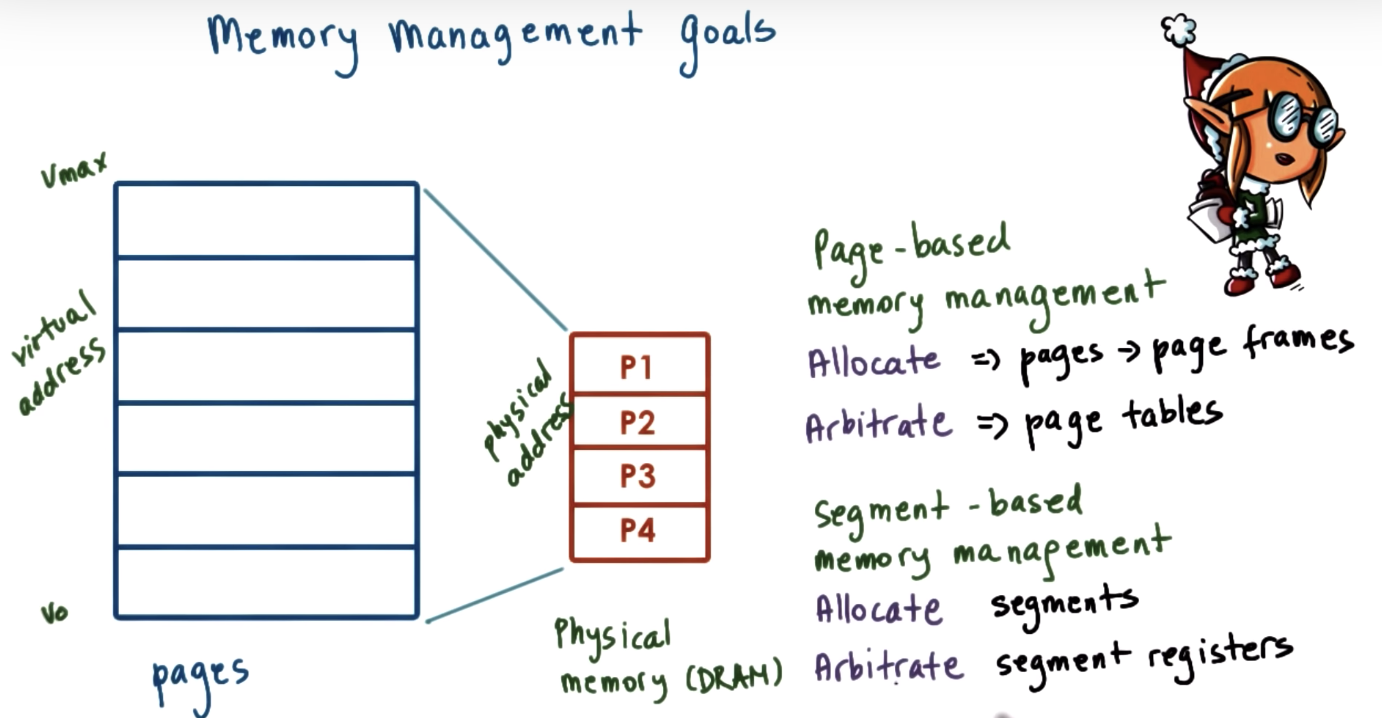
Memory Management: Goals

Memory Management: Hardware Support
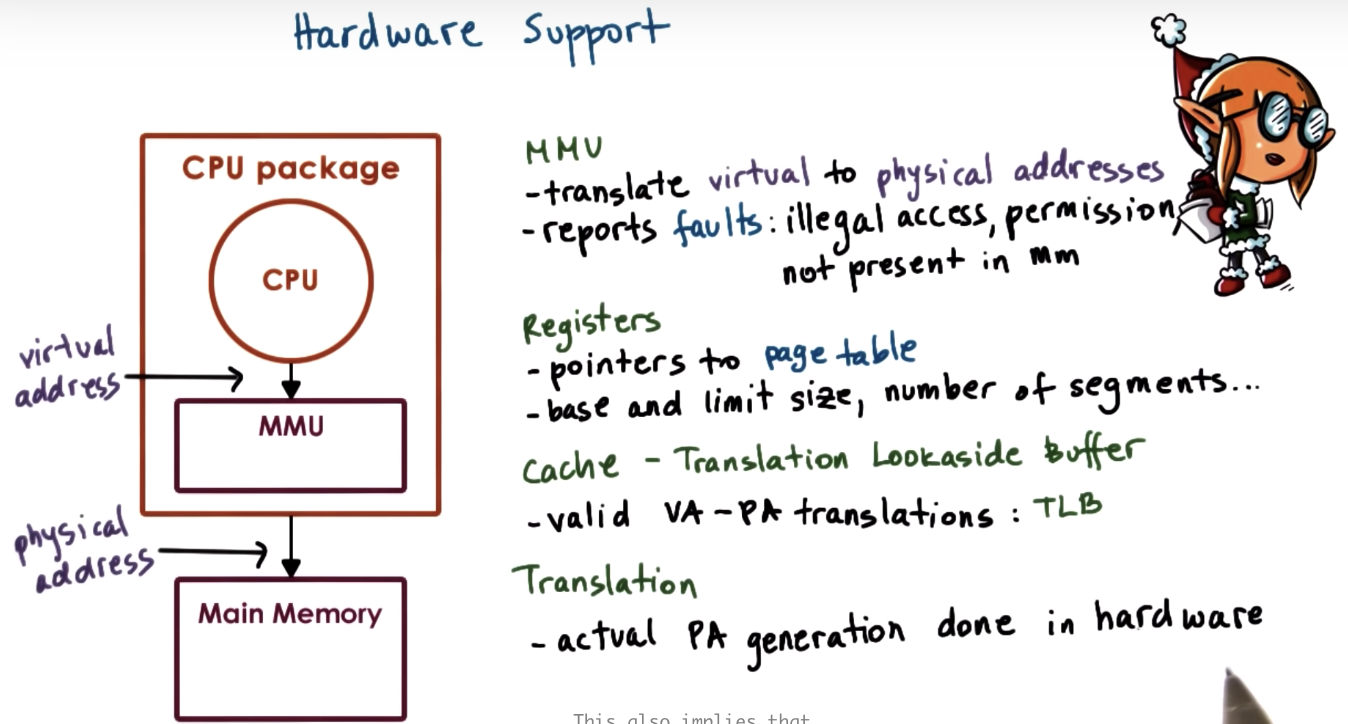
MMU: memory management unit
TLB: translation lookaside buffer
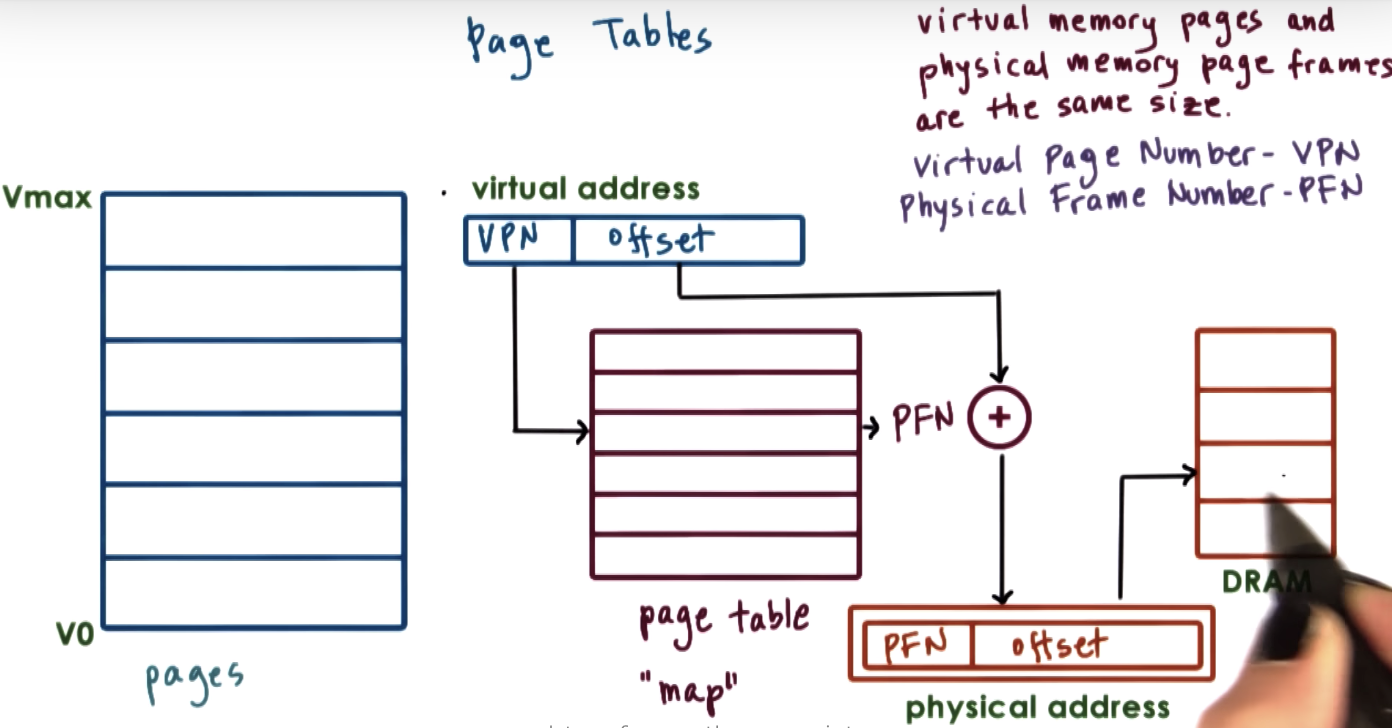
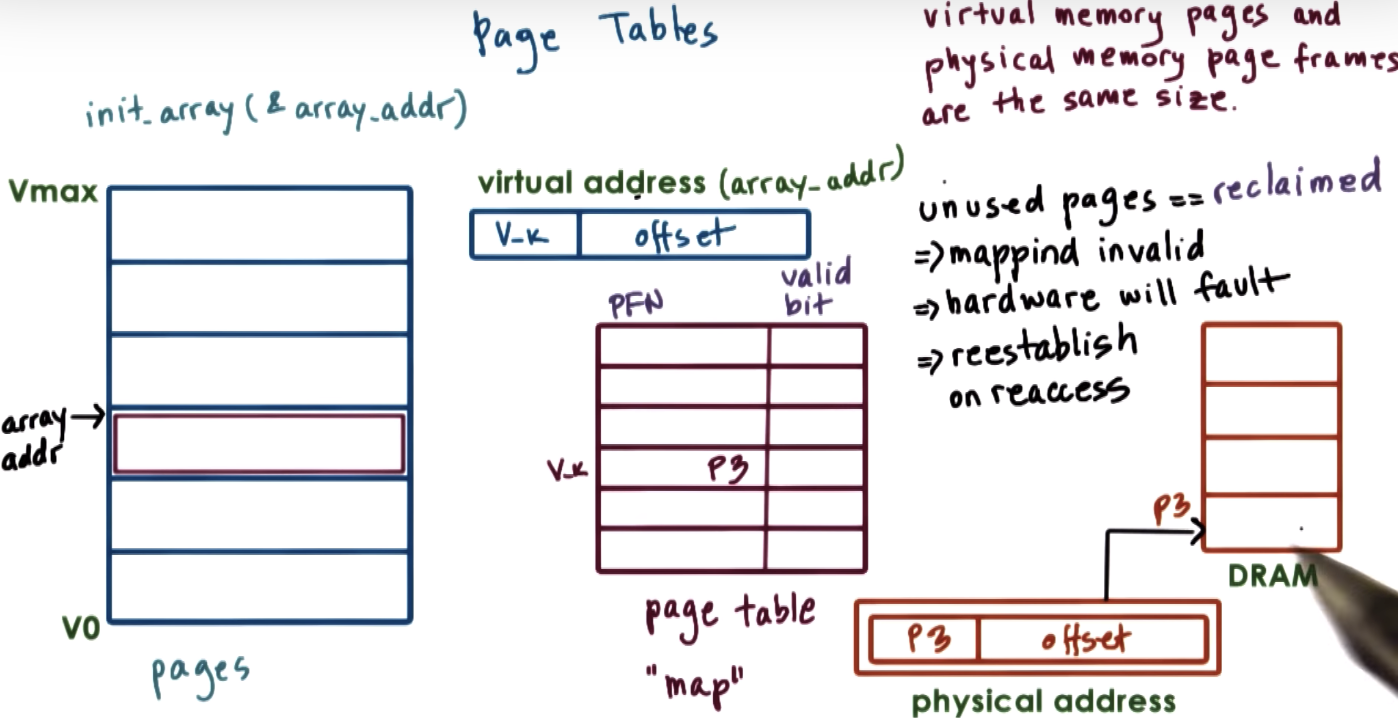
Page Tables
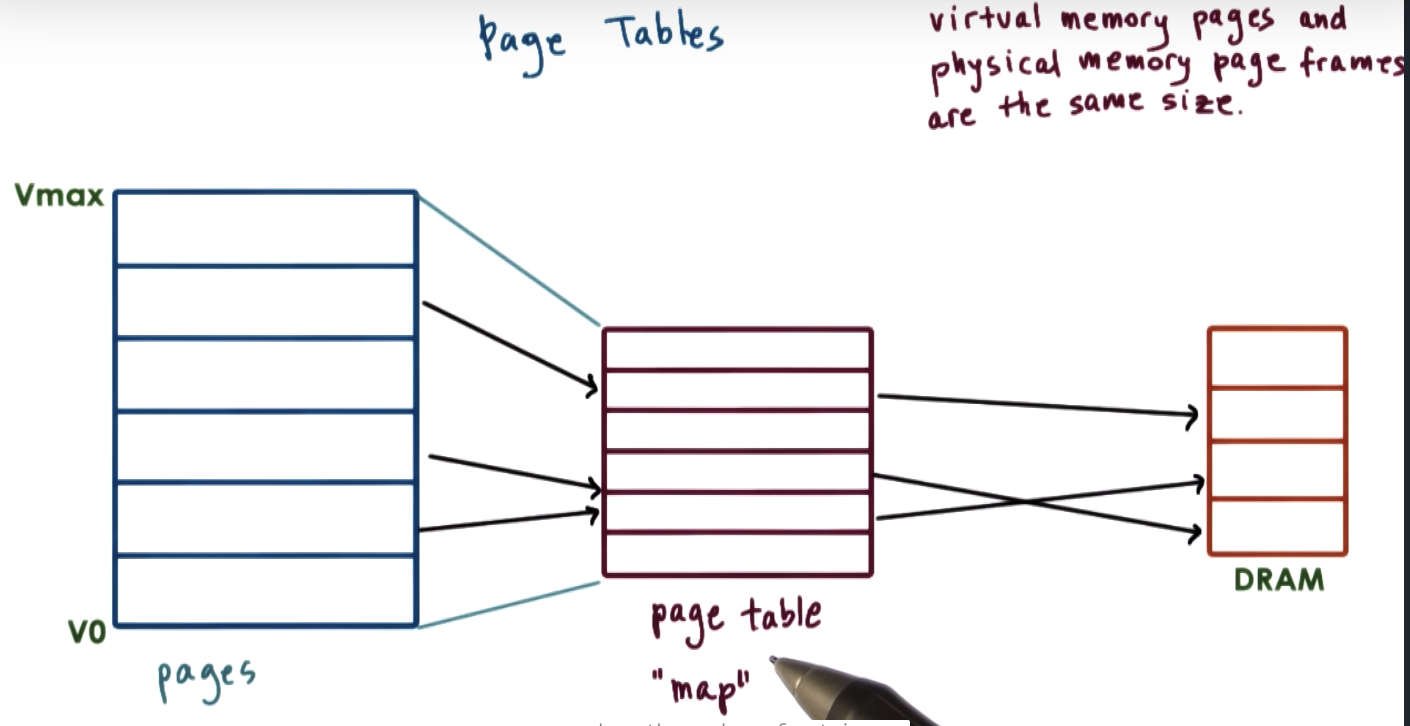
VPN: virtual page number
PFN: physical frame number

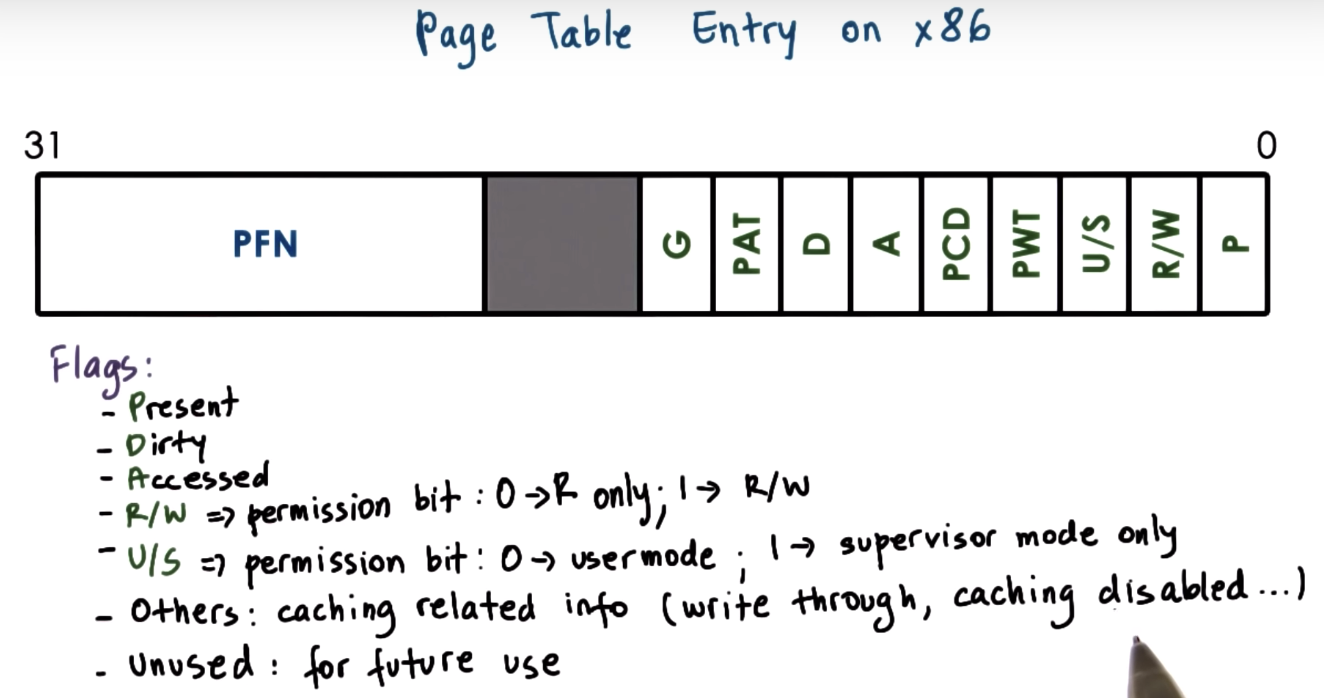
Page Table Entry

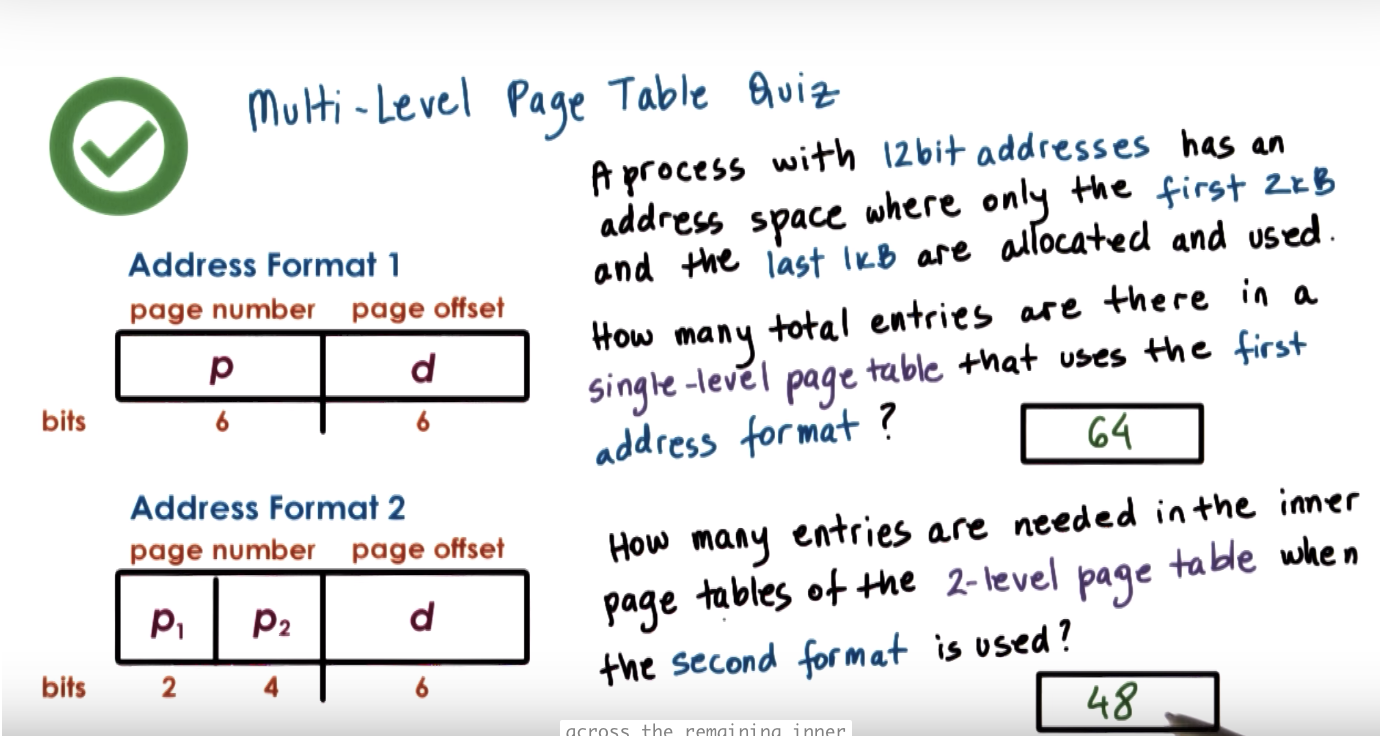
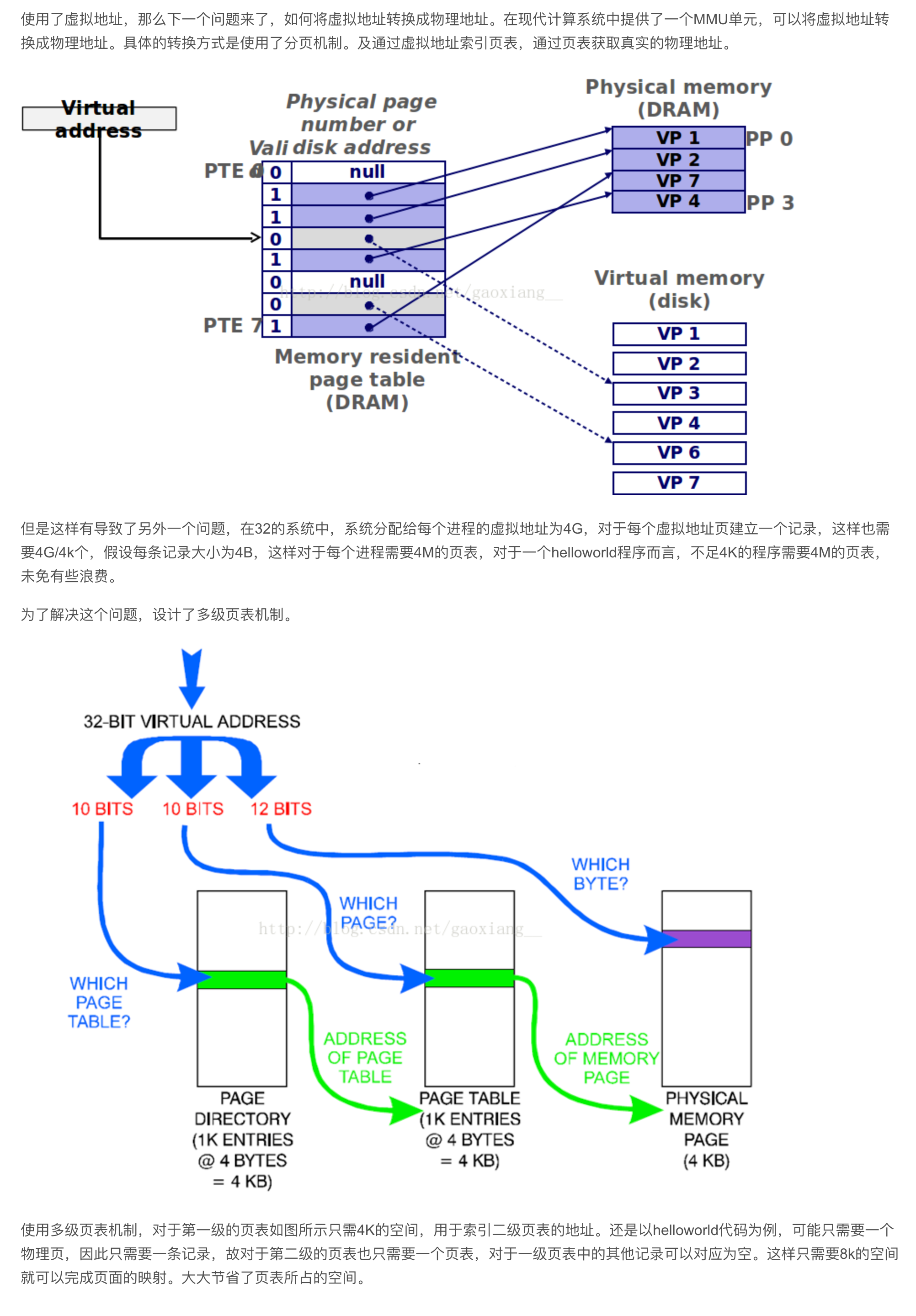
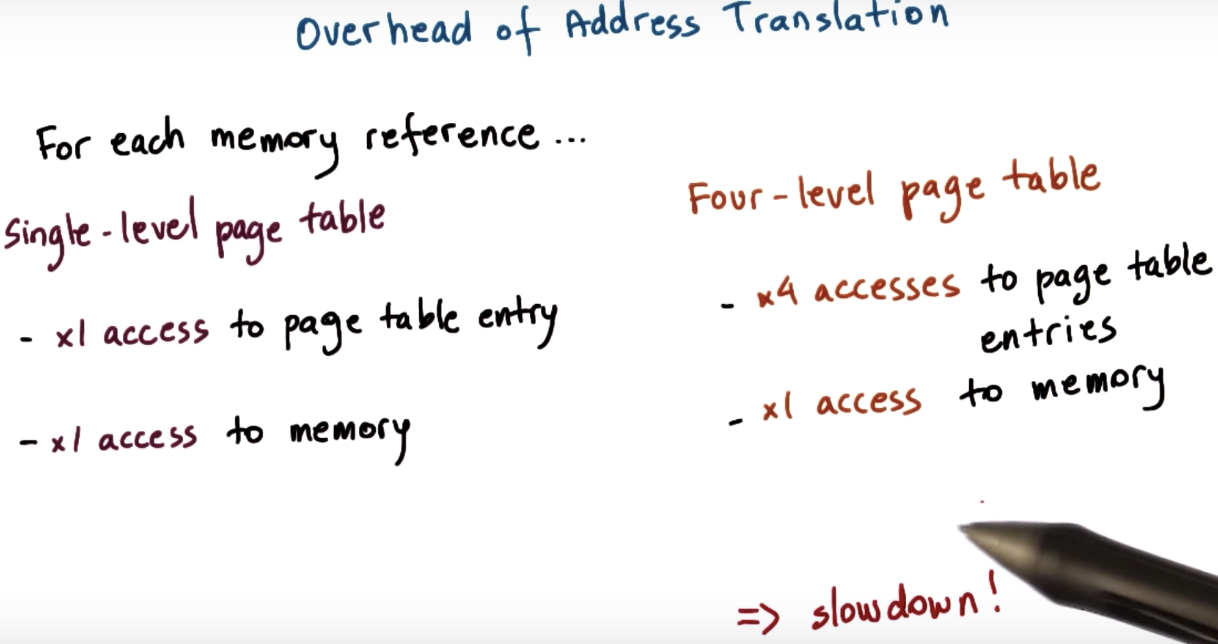
Page Table Size

page size => size of offset region => size of each frame in physical memory (fixed and small)
page table is a map, transforming a page index of the virtual memory to a frame index of the physical memory.


Multi Level Page Tables
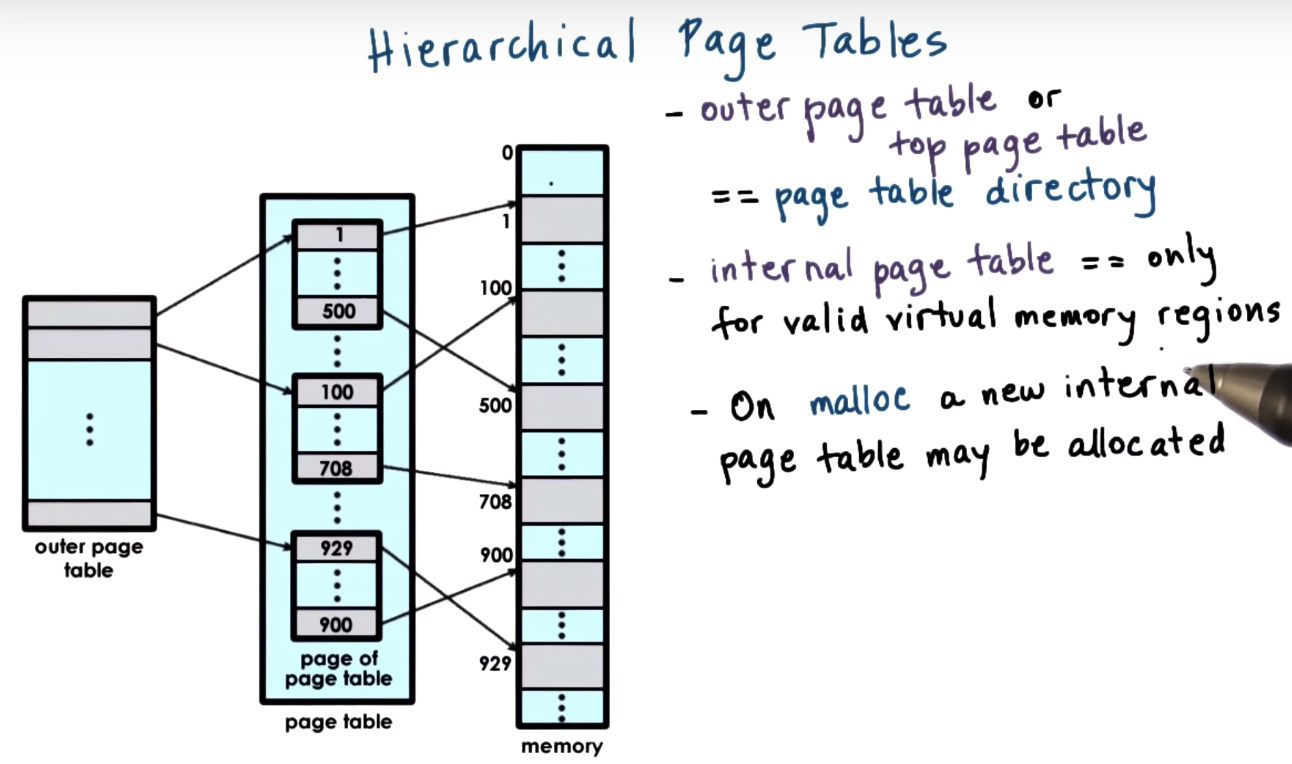

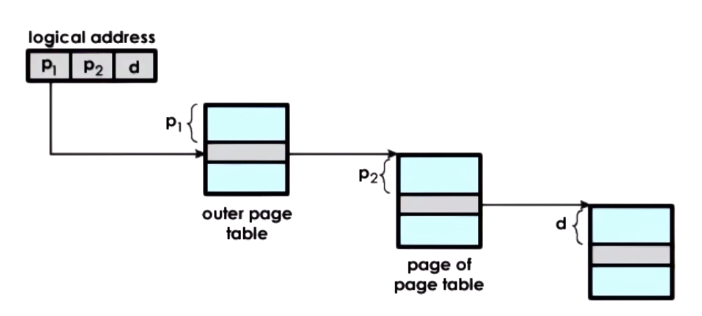



https://blog.csdn.net/gaoxiang__/article/details/41578339
Speeding Up Translation TLB

Inverted Page Tables
there's only one inverted page table in the system?

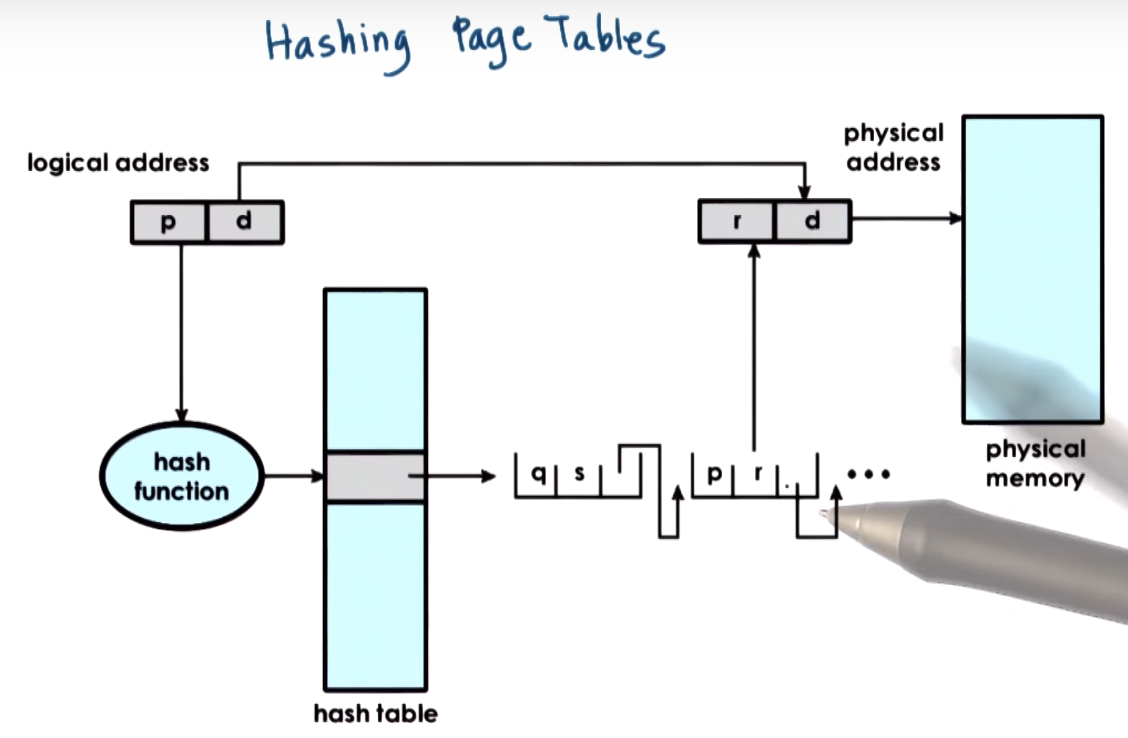
from part of the virtual address to a linked list of potential results.
http://blog.forec.cn/2017/01/03/os-concepts-8/

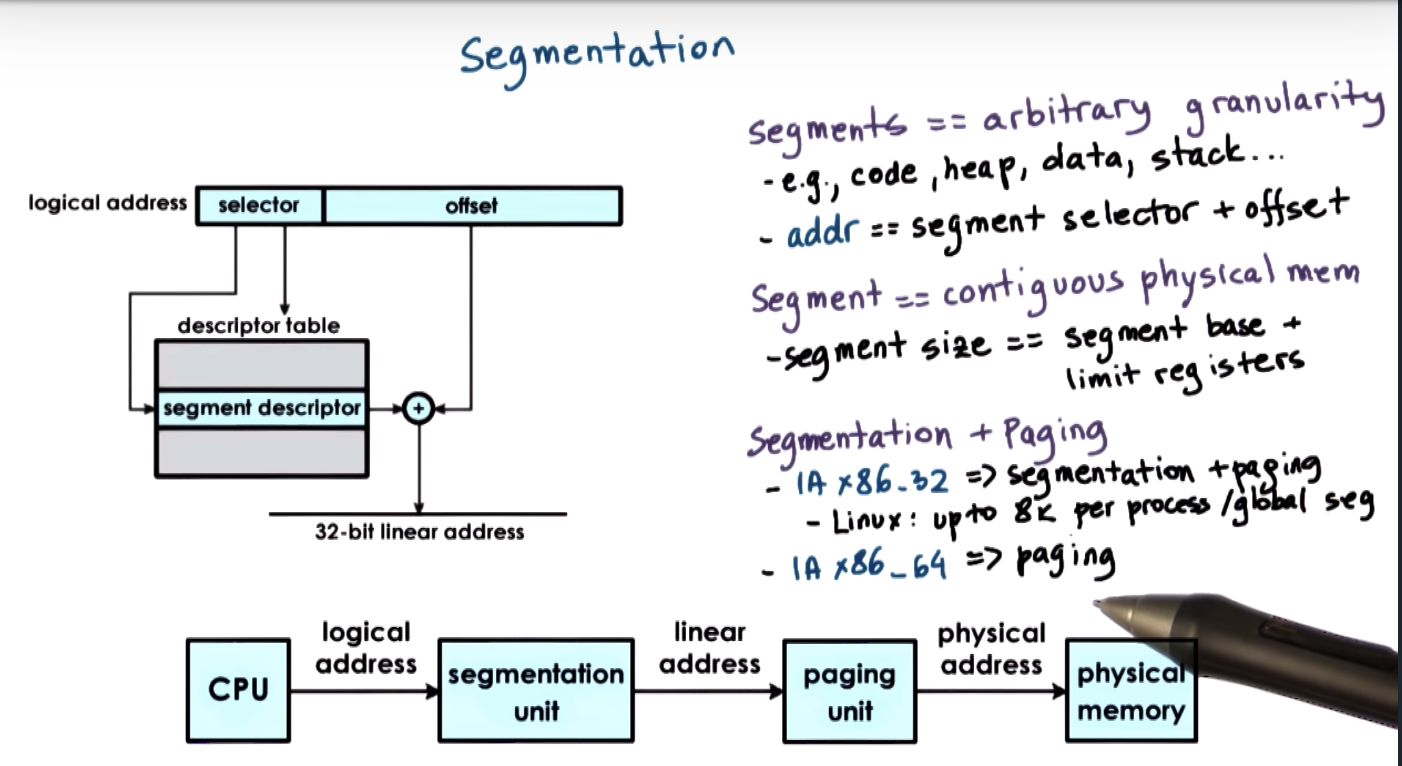
Segmentation
Page Size


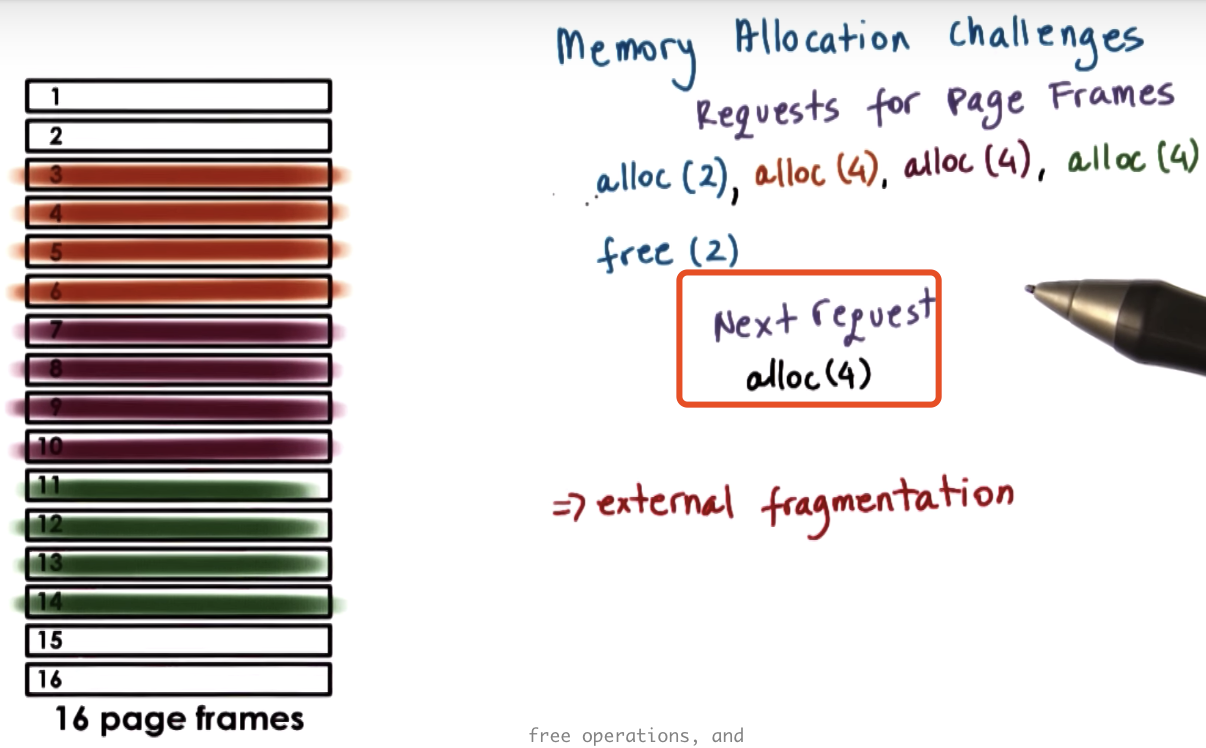
Memory Allocation

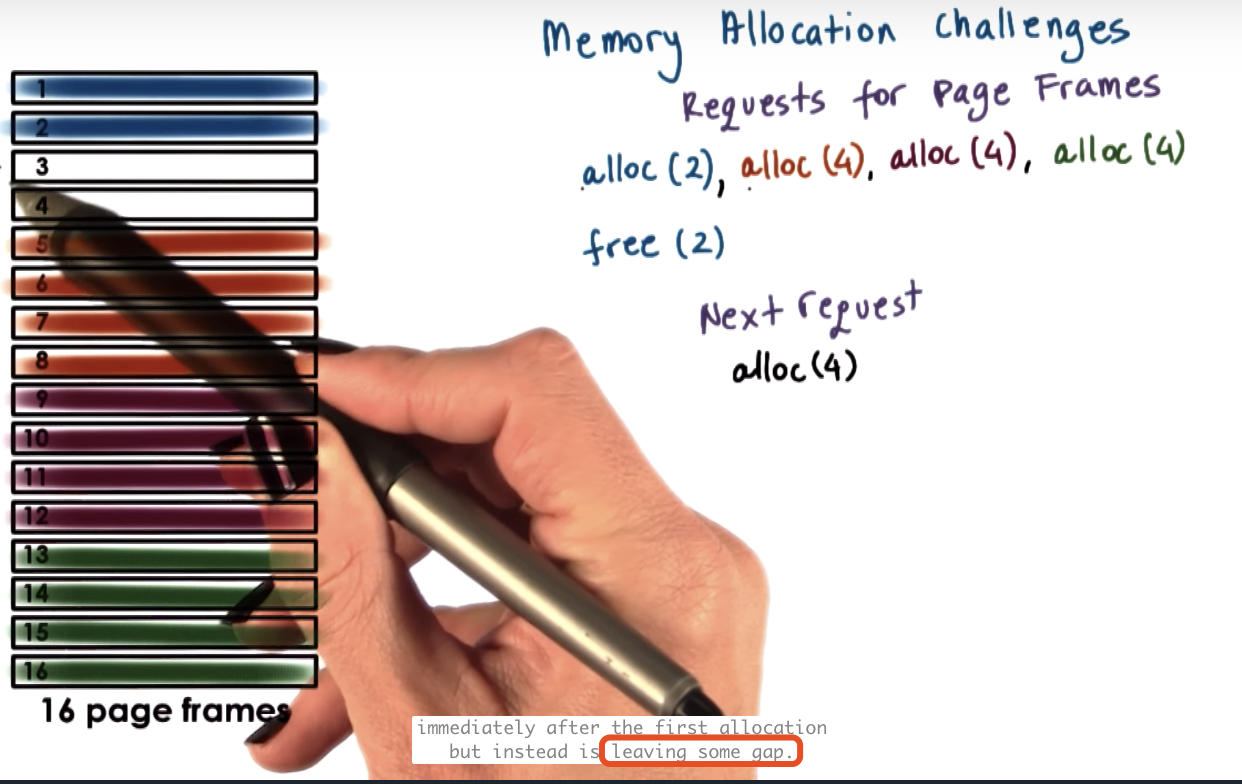
Memory Allocation Challenges


Linux Kernel Allocators

eg. task data structure's size is 1.7k, not closed to a power of two
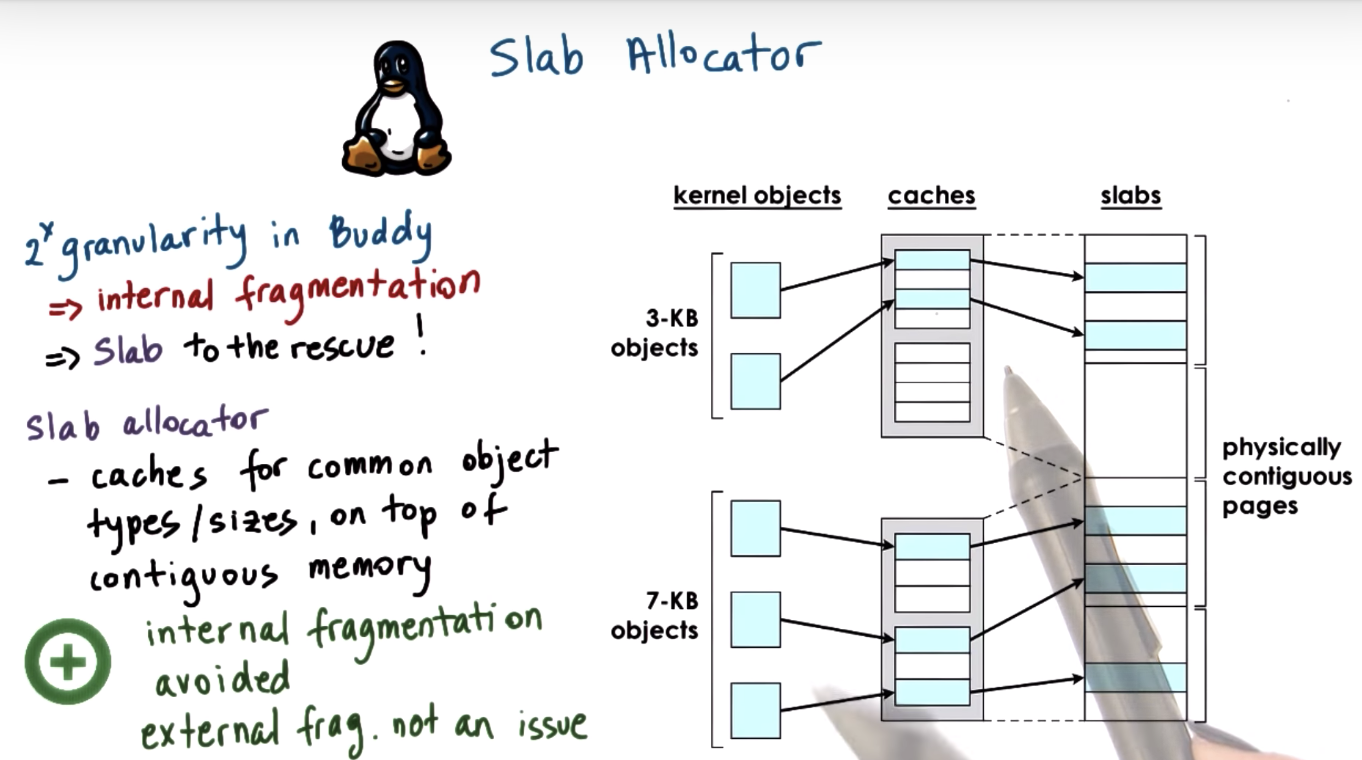
The slabs represent contiguously allocated physical memory. When the kernel starts, it will pre-create caches for the different object types.
eg. task_struct, directory entry objects
Then when an allocation comes from a particular object type, it will go straight to the cache and use one of the elements in this cache.
Or the kernel will create another slab if none of the slabs is available now.
https://stackoverflow.com/questions/37404769/whats-the-difference-between-slab-and-buddy-system
A slab is a collection of objects of the same size. It avoids fragmentation by allocating a fairly large block of memory and dividing it into equal-sized pieces. The number of pieces is typically much larger than two, say 128 or so.
There are two ways you can use slabs. First, you could have a slab just for one size that you allocate very frequently. For example, a kernel might have an inode slab. But you could also have a number of slabs in progressive sizes, like a 128-byte slab, a 192-byte slab, a 256-byte slab, and so on. You can then allocate an object of any size from the next slab size up.
Note that in neither case does a slab re-use memory for an object of a different size unless the entire slab is freed back to a global "large block" allocator.
The buddy system is an unrelated method where each object has a "buddy" object which it is coalesced with when it is freed. Blocks are divided in half when smaller blocks are needed. Note that in the buddy system, blocks are divided and coalesced into larger blocks as the primary means of allocation and returning for re-use. This is very different from how slabs work.
Or to put it more simply:
Buddy system: Various sized blocks are divided when allocated and coalesced when freed to efficiently divide a big block into smaller blocks of various sizes as needed.
Slab: Very large blocks are allocated and divided once into equal-sized blocks. No other dividing or coalescing takes place and freed blocks are just held in a list to be assigned to subsequent allocations.
The Linux kernel's core allocator is a flexible buddy system allocator. This allocator provide the slabs for the various slab allcoators.
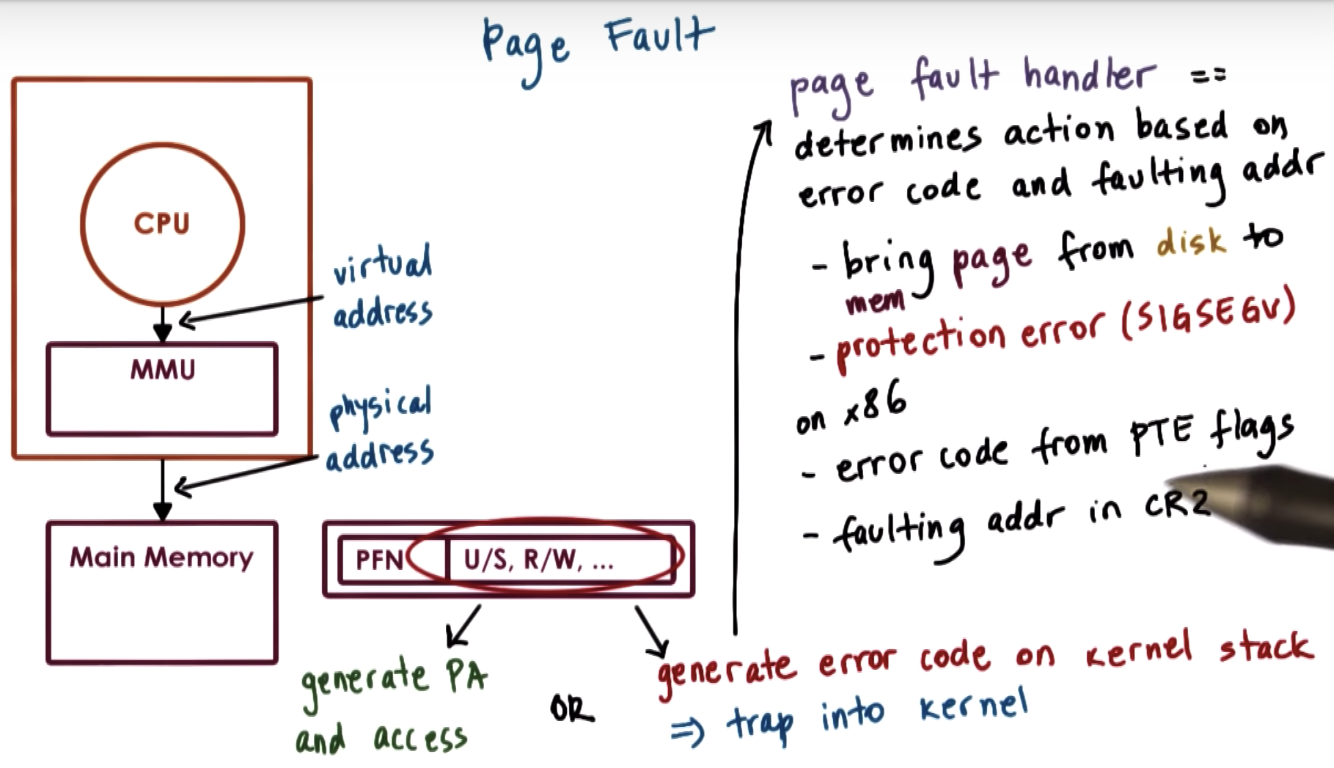
Demand Paging

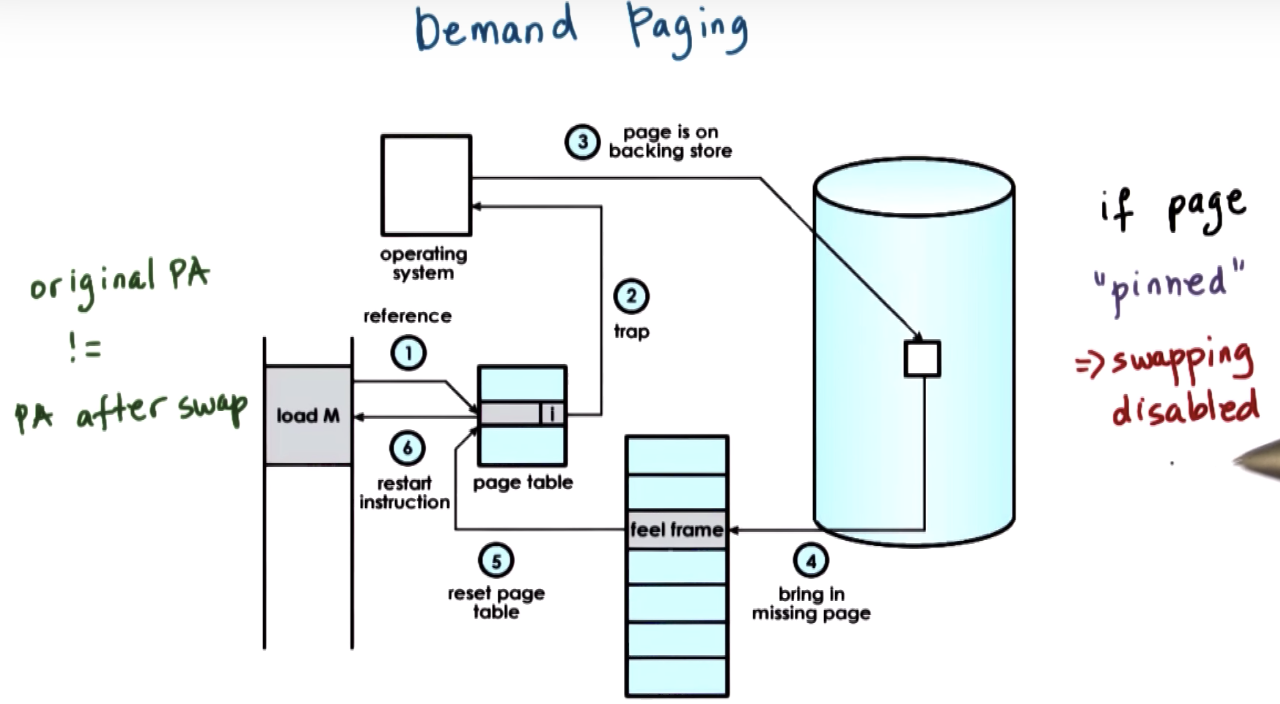
① reference => page table => not in memory => kernel raises an exception (page fault) => exception is pushed into OS kernel
=> OS knows that it has previously move the memory page onto disk => ③④ OS issues an I/O operation => OS determines the free frame in physical memory
=> OS updates/resets the page table
BTW, Direct memory access => DMA => disable swapping
Page Replacement




Errata
It should be further specified that 11 page-sized entries are accessed one-by-one and then manipulated one-by-one in a the loop. Assume the following structure:
int i = 0;
int j = 0;
while(1) {
for(i = 0; i < 11; ++i) {
// access page[i]
}
for(j = 0; j < 11; ++j) {
// manipulate page[i]
}
break;
}Copy On Write





PA: physical address
We call this mechanism "Copy on Write" because the copy cost will only be paid when we nned to perform a write operation.
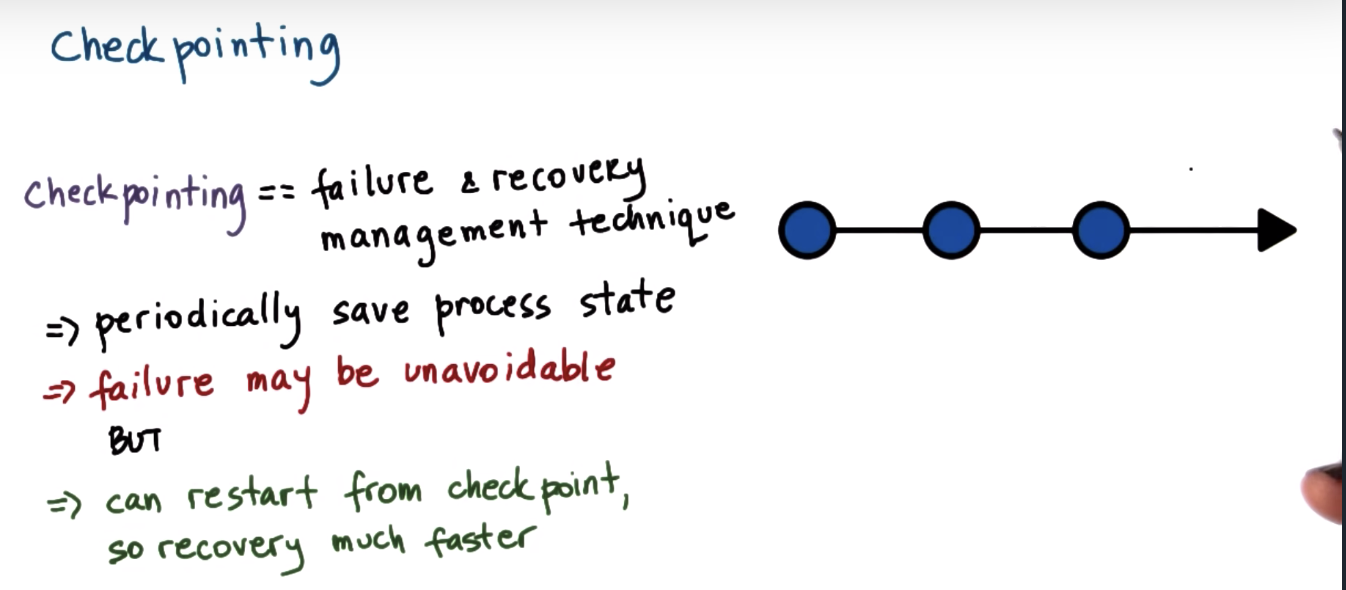
Failure Management Checkpointing