一. Meta Store
使用mysql客户端登录hadoop100的mysql,可以看到库中多了一个metastore
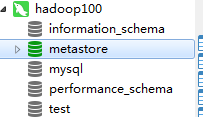
现在尤其要关注这三个表

DBS表,存储的是Hive的数据库

TBLS表,存储的是Hive中的表,使用DB_ID和DBS表关联

COLUMNS_V2存储的是每个表中的字段信息

Meta Store并不存储真实的数据,只是存储数据库的元数据信息,数据是存储在HDFS上的
二. HDFS
浏览器打开 http://hadoop100:50070/explorer.html#/ 在/目录下多了一个user目录

点进去

再点进去

再点进去

我们创建的表就出来了,难道没有人疑问default库哪里去了么?使用客户端,创建一个数据库~
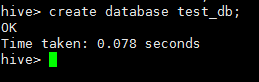
再刷新一下

所以,如果使用默认的default数据库,数据表将会放在hive/warehouse目录下.使用自定义的数据库,也会放在hive/warehouse目录下,再建表的话,会存到下一级目录下
其实这个目录,也是可以改的,修改conf/hive-stie.xml
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property>
三. JDBC连接Hive
1. 启动hiveserver2服务
bin/hiveserver2

阻塞是正常的,不要以为没起来...不想阻塞的话,可以使用后台守护的方式启动,bin/hiveserver2 & 加一个&符号
2.新开一个ssh窗口,启动beeline
bin/beeline

3. 连接hiveserver2
!connect jdbc:hive2://hadoop102:10000

4.爱之初体验
show databases;

5.Hive常用交互命令,新开一个ssh客户端,在不使用jdbc连接的情况下操作
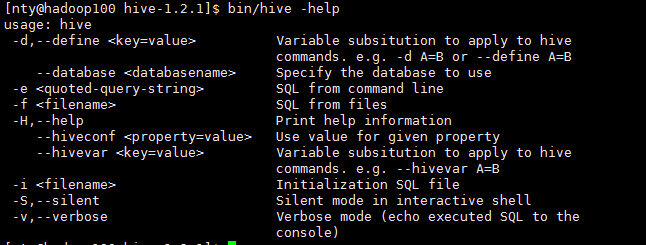
重点关注-e和-f参数,-e参数后面可以跟sql语句,-f参数后面可以跟一个sql文件

在opt/datas目录下新建一个sql文件,随便写条sql语句进去
select name from namelist;

6. 其他的一些操作
使用bin/hive连接,查看hdfs下的目录
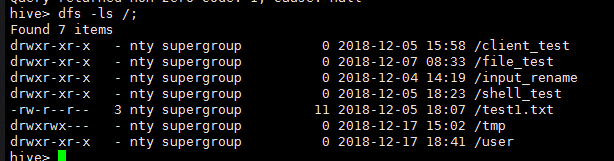
查看本地文件目录
四. 参数配置方式及优先级
1. 查看当前所有的配置信息
hive>set;
2. 参数的配置三种方式
1). 配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
2). 命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
例如:
bin/hive -hiveconf mapred.reduce.tasks=10;
注意:仅对本次hive启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;
3). 参数声明方式
可以在HQL中使用SET关键字设定参数
例如:
hive (default)> set mapred.reduce.tasks=100;
注意:仅对本次hive启动有效。
查看参数设置
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增,即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了