一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 1620 | 2010 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 300 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 30 |
| · Design | · 具体设计 | 180 | 120 |
| · Coding | · 具体编码 | 600 | 1440 |
| · Code Review | · 代码复审 | 500 | 10 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 70 |
| Reporting | 报告 | 95 | 155 |
| · Test Repor | · 测试报告 | 60 | 120 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1720 | 2170 |
二、计算模块接口
1.计算模块接口的设计与实现过程
设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
代码组织
包括以下2个类:
WordMap类 - 构建DFA树
- addToWordSet函数 - 将敏感词放入到HashSet中
- initWordMap函数 - 初始化敏感词库
Tool类 - 使用DFA树以及拼音、部首的转化
- getPyWord函数 - 中文敏感词拼音替代、拼音首字母替代
- initDictMap函数 - 初始化部首字典
- getBsWord函数 - 中文敏感词部首拆分
- checkKeyword函数 - 敏感词检测
关键算法
关键函数有敏感词检测checkKeyword函数、getPyWord函数、getBsWord函数等。
其中getPyWord函数主要调用库来实现(jpinyin.jar是我目前找到最全的),getBsWord函数主要是添加汉语拆字的字典,来检测偏旁部首拆分。
而checkKeyword函数采用了DFA算法 ,即确定有穷自动机,通过动作和当前状态得到下一个状态,即event+state=nextstate。在实现敏感词过滤的过程中,我们必须要减少运算,而DFA在DFA算法中几乎没有什么计算,只有状态的转换。
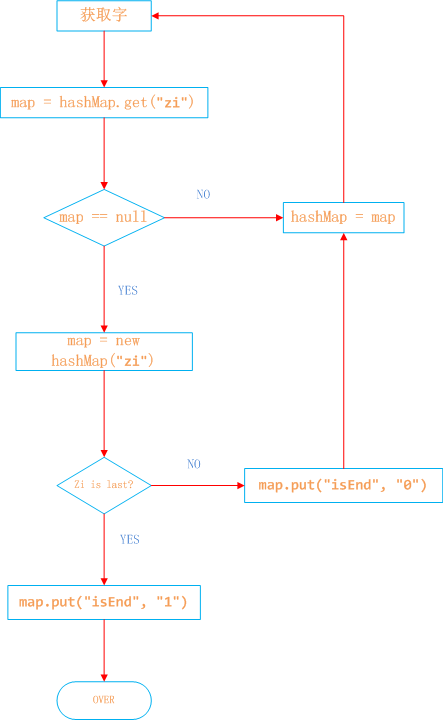
实现DFA算法的流程为:
- 词库整理:将敏感词放入到HashSet中
- 构建DFA树:详见下面的流程图
- DFA树的使用:逐个检测目标词中的字,最后一个字在树中且满足isEND=1,则是敏感词
int matchNum = 0; // 敏感词数量
String wordTxt = ""; // 检测到的敏感词
int beginIndex = 100000; // 文本首部
int endIndex = 0; // 文本尾部
char word;
Map currMap = keywordMap;
Map prevMap;
for(int i = 0; i < txt.length(); i++){
word = txt.charAt(i);
if(word >= 'A' && word <= 'Z'){
// 大小写字母替代
word -= 'A'-'a';
}else if(ChineseHelper.isTraditionalChinese(word)){
// 繁体字替代
word = ChineseHelper.convertToSimplifiedChinese(word);
}
// 判断该字是否存在于敏感词库中
prevMap = currMap;
currMap = (Map) currMap.get(word);
if(currMap != null){ // 存在
if(beginIndex > i){
beginIndex = i;
}
endIndex++;
wordTxt += word;
// 判断该字是否为结尾字
if("1".equals(currMap.get("isEnd"))){
if(i != txt.length() - 1 && (Map) currMap.get(txt.charAt(i+1))!=null){ // 最大规则
continue;
}
matchNum++;
ansArr.add("Line" + line + ": <" + wordTxt + ">"+txt.substring(beginIndex, beginIndex + endIndex));
beginIndex = 100000;
endIndex = 0;
wordTxt = "";
currMap = keywordMap;
}
}else{ // 不存在
if(endIndex > 0 && (word+"").matches("[^(a-zA-Zu4e00-u9fa5)]")){
// 过滤伪装字
endIndex++;
currMap = prevMap;
} else{
beginIndex = 100000;
endIndex = 0;
wordTxt = "";
currMap = keywordMap;
}
}
}
return matchNum;
}
独到之处有运算量小、检测速度快、便于维护 和几个难题:
- 敏感词输出怎么查找原词
- 最小匹配和最大匹配原则有什么区别
- 拼音替代功能要在什么时候实现(最后选择添加进HashSet中)
2.计算模块接口部分的性能改进
记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
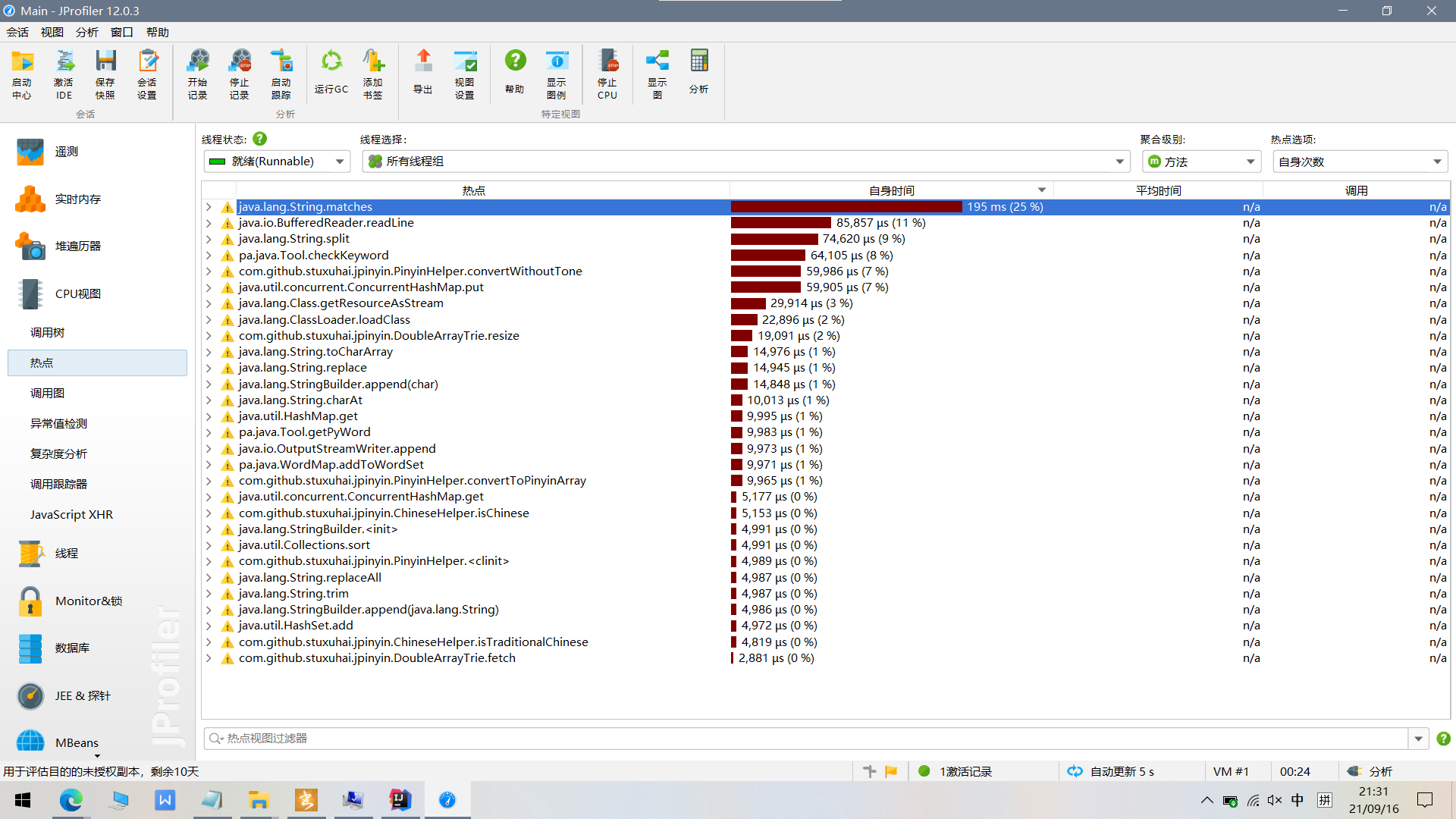
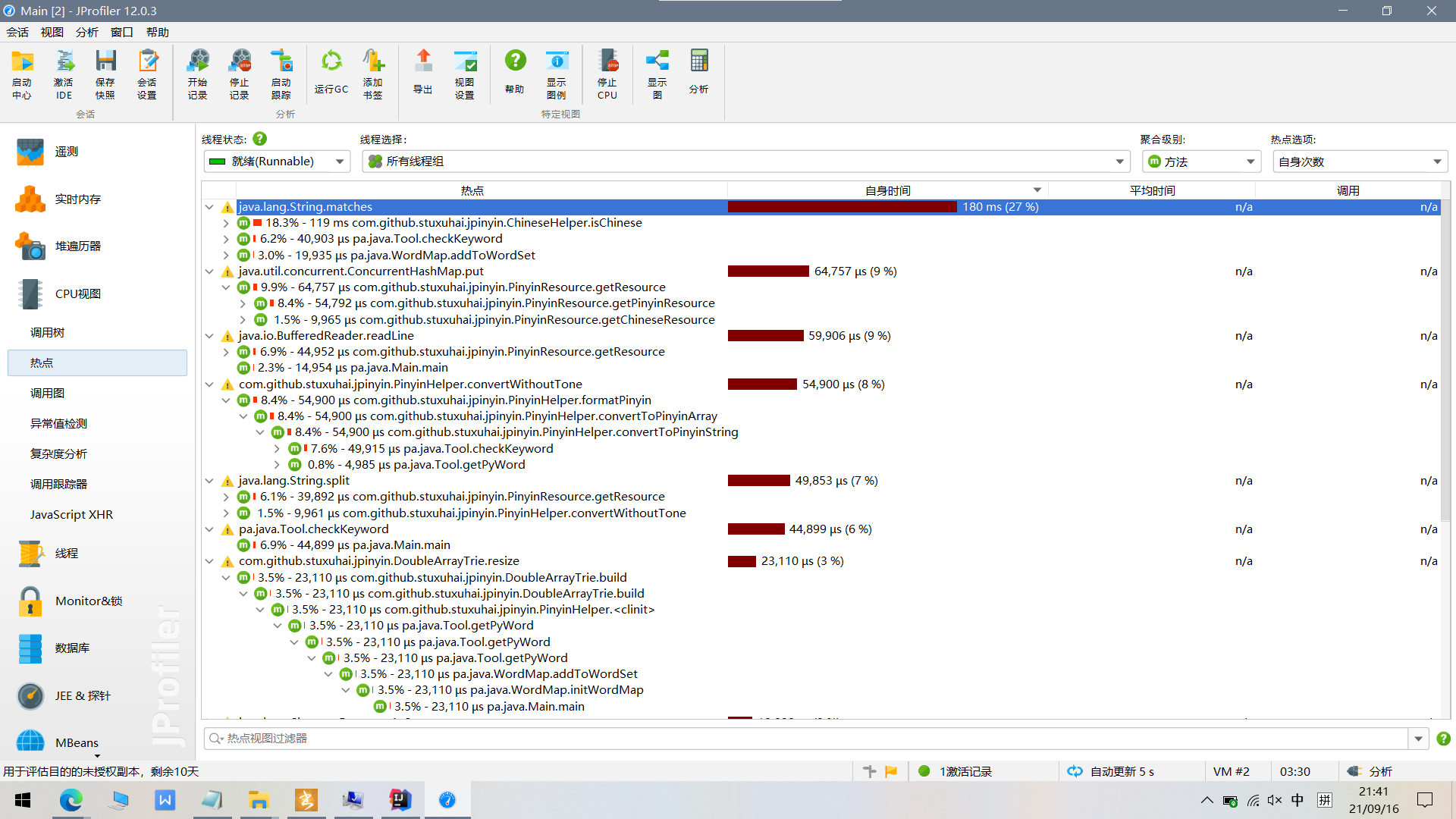
消耗最大的函数是matches函数,主要是jpinyin使用。一方面,很多功能都依赖于这个函数实现,函数比较累赘,考虑减少其他功能的调用;另一方面,jpinyin下的函数消耗也很大,考虑换一个更优秀的库?
3.计算模块部分单元测试展示
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
测试拼音、拼音首字母替代敏感词的添加
@Test
public void testGetPyWord() throws Exception {
// 敏感词
HashSet<String> keyWordsSet = new HashSet<>();
keyWordsSet.add("好人");
// 预期答案 共9个
HashSet<String> ansSet = new HashSet<>();
ansSet.add("好人");
ansSet.add("好ren");
ansSet.add("好r");
ansSet.add("hao人");
ansSet.add("h人");
ansSet.add("haoren");
ansSet.add("haol");
ansSet.add("hren");
ansSet.add("hl");
Tool tool = new Tool();
tool.getPyWord(0,"好人",keyWordsSet);
keyWordsSet.equals(ansSet);
}
4.计算模块部分异常处理说明
在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
读写异常:在使用流、文件和目录访问信息时引发的异常
拼音异常:发生在无法转换汉字拼音、拼音首字母的场景
三、心得
Java语言真的很难啊,相比之下Python简单很多。要是重来一次,我会选择Python,毕竟两种语言都是菜鸟水平。但最后也实现了基本需求,就是单元测试部分还没做得很清楚,IDEA相关的工具用得也很懵,希望下次效率能够提升吧!