Kafka的特性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic(话题)可以分多个partition(分区), consumer group(消费组) 对partition进行consume(消费)操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同
kafka基本原理:
生产者将数据生产出来,交给 broker 进行存储,消费者需要消费数据了,就从broker中去拿出数据来,然后完成一系列对数据的处理操作。
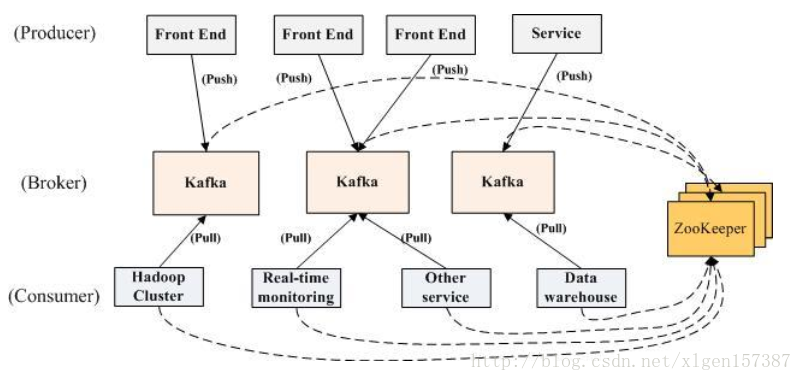
多个 broker 协同合作,producer 和 consumer 部署在各个业务逻辑中被频繁的调用,三者通过 zookeeper管理协调请求和转发。这样一个高性能的分布式消息发布订阅系统就完成了。
消息系统的核心作用就是三点:解耦,异步和缓冲
Kafka核心组件
- Topic :消息根据Topic进行归类
- Producer:发送消息者
- Consumer:消息接受者
- broker:每个kafka实例(server)
- Zookeeper:依赖集群保存meta信息。
Kafka的使用场景
- 日志收集:Kafka可以收集各种日志文件,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
kafka消费者的三种消费语义
- At most once 消息可能会丢,但绝不会重复传输
- At least one 消息绝不会丢,但可能会重复传输
- Exactly once 每条消息肯定会被传输一次且仅传输一次
Kafka数据丢失问题
1)使用同步模式的时候,有3种状态保证消息被安全生产,在配置为1(只保证写入leader成功)的话,如果刚好leader partition挂了,数据就会丢失。
producer.type=sync
request.required.acks=1
2)还有一种情况可能会丢失消息,就是使用异步模式的时候,当缓冲区满了,如果配置为0(还没有收到确认的情况下,缓冲池一满,就清空缓冲池里的消息), 数据就会被立即丢弃掉。
producer.type=async
request.required.acks=1
batch.mun.messages=100//在异步模式下,一个Batch发送的消息数量,product会等待直到发送的消息数量达到这个值,之后才会发送,该配置默认值200,但是如果数量不够,达到queue.buffer.max.ms时也会直接发送
queue.buffering.max.ms=100//使用异步模式数据缓冲最大的时间,换句话说该配置会每隔100ms发送数据,这个会相应的提高吞吐量,但是会增加消息达到的时间,默认值为5000ms
queue.buffering.max.messages=100//发送队列缓冲长度,默认值10000条数据
queue.enqueue.timeout.ms=10000//当消息在达到queue.buffering.max.messages配置时候,会阻塞一定时间后,如果队列任然没有enqueue(producter然仍没有发送任何消息),此时producer可以继续阻塞或者将消息抛出,此timeout值用于控制阻塞的时间,如果值为-1(默认值)则 无阻塞超时限制,消息不会被抛弃;如果值为0 则立即清空队列,消息被抛弃。
而对于配置Product Configs最重要4个参数
- metadata.broker.list
- request.required.acks
- producer.type
- serializer.class
############################# Producer Basics #############################
# list of brokers used for bootstrapping knowledge about the rest of the cluster
# format: host1:port1,host2:port2 ...
metadata.broker.list=localhost:9092
# name of the partitioner class for partitioning events; default partition spreads data randomly
#partitioner.class=
# specifies whether the messages are sent asynchronously (async) or synchronously (sync)
producer.type=sync//支持设置sync同步和异步async
request.required.acks=0
//默认值为0,该值延迟性最低但持久性保证最低,一旦服务器宕机数据有丢失的风险,设置该值后,product不会等待brocker返回的ack,如leader已死,但producer并不知情,发出去的信息broker就收不到)。
//1:这意味着producer在leader已成功收到的数据并得到确认后发送下一条message。此选项提供了更好的耐久性为客户等待服务器确认请求成功(被写入死亡leader但尚未复制将失去了唯一的消息)。
//-1:这意味着producer在follower副本确认接收到数据后才算一次发送完成。 此选项提供最好的耐久性,我们保证没有信息将丢失,只要至少一个同步副本保持存活。 三种机制,性能依次递减 (producer吞吐量降低),数据健壮性则依次递增。
# specify the compression codec for all data generated: none, gzip, snappy, lz4.
# the old config values work as well: 0, 1, 2, 3 for none, gzip, snappy, lz4, respectively
compression.codec=none
# message encoder
serializer.class=kafka.serializer.DefaultEncoder
# allow topic level compression
#compressed.topics=