我们知道无论是oracle,还是mysql,只要对某列分组,就只能查询分组列或者分组函数列,而对于分组后的整体数据单单靠一个分组函数查询不出来。
在以前开发时,使用的是oracle数据库,比如有很多年的数据,根据年限分组,获取每组最大值,在oracle中可以这样实现:
select *
from (select t.*,
row_number() over(partition by t.dqdm order by t.nf desc) cn --这么理解,按dqdm分组,每组按nf降序,这样row_number() 这列(别名cn) 会按照分好的组,每组都1、2、3,1、2、3的排
from t_sjk_dqmjxx t
where t.scbj = '0')
where cn = '1'--这时取第一个就是按dqdm排序,取每组年份最大的字段值了
但mysql没有类似的函数,需要我们使用用户变量来模拟实现类似的功能:
1.测试数据表结构:
CREATE TABLE `stud` (
`id` varchar(30) NOT NULL,
`name` varchar(30) NOT NULL,
`score` int(11) DEFAULT NULL,
`subject` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.插入测试数据
insert into `stud` (`id`, `name`, `score`, `subject`) values('1001','张三','98','语文');
insert into `stud` (`id`, `name`, `score`, `subject`) values('1002','张三','86','数学');
insert into `stud` (`id`, `name`, `score`, `subject`) values('1003','张三','73','英语');
insert into `stud` (`id`, `name`, `score`, `subject`) values('1004','李四','85','语文');
insert into `stud` (`id`, `name`, `score`, `subject`) values('1005','李四','92','数学');
insert into `stud` (`id`, `name`, `score`, `subject`) values('1006','李四','79','英语');
insert into `stud` (`id`, `name`, `score`, `subject`) values('1007','王五','68','语文');
insert into `stud` (`id`, `name`, `score`, `subject`) values('1008','王五','79','数学');
insert into `stud` (`id`, `name`, `score`, `subject`) values('1009','王五','92','英语');整理完是这样的表结构:

3.使用sql查询分组
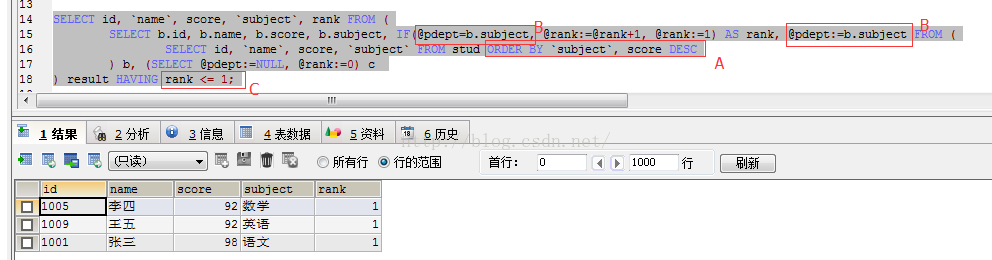
这里有几个说明的地方:
A:一定要自己手动排好序,因为我本意是按照科目分组,查出每个科目分数最高的学员信息,因此先按照subject排序,再按照score降序(asc查询的就是每科中成绩最低的学员信息了)
B:仿照这个改sql时,除了自己的表字段以外,B处是要手动替换的字段,因为我需要科目分组,所以需要写成subject,按照每个科目的rank进行1、2、3...这样的展示
C:rank <=1,1代表了选取每组第一行的数据
完成sql如下展示:
SELECT id, `name`, score, `subject`, rank FROM (
SELECT b.id, b.name, b.score, b.subject, IF(@pdept=b.subject, @rank:=@rank+1, @rank:=1) AS rank, @pdept:=b.subject FROM (
SELECT id, `name`, score, `subject` FROM stud ORDER BY `subject`, score DESC
) b, (SELECT @pdept:=NULL, @rank:=0) c
) result HAVING rank <= 1; 编辑于17.10.12:
这两天需要用到这方面的知识,但这个sql连我自己看着都麻烦,从网上找到被别人点过赞的。我也改写放到线上了。后来线上的一个数据还是有问题。分组取最值(或者说是需要的几条数据)失败。我这个麻烦归麻烦,写完也用下试试吧,结果真没问题。线上N个sql都用的这个求最值。但sql直接看实在有点乱。我再整理下吧:
上面的sql总结下就是下面的这些,已经颜色区分开了
SELECT aa, bb, cc, activityID,rank FROM (
SELECT aa, bb, cc,activityID, IF(@orderField=maxb.activityID, @rank:=@rank+1, @rank:=1) AS rank,@orderField:=maxb.activityIDFROM (
SELECT aa, bb, cc,activityIDFROM dates ORDER BY activityID DESC,endDate DESC, endTime DESC
)maxb, (SELECT @orderField:=NULL, @rank:=0) maxc
) result HAVING rank <= 1;
上面需要注意的就是:例如一个活动有可能有N个时间地点信息,现在要找出M个活动中最新的时间地点信息,按理说就是M条数据,参考:http://bjmx.xdf.cn/huodong/的应用示例(要把已结束的活动标记出来)
1.排序,我想把数据按照活动id分组,求出每个活动最新的时间地点信息(dates这个表,按照活动id、日期倒序、时间倒序排序)
自己的业务如要使用,第一个排序就是要分组的字段;第二个排序字段之后,就是求最值的字段,比如求时间最大值就按照时间倒序,时间最小值就是按照时间正序,这个我不用多说就好理解,这里面用黄色背景标出
2.分组,要对哪个进行分组,红色字体就替换成那个字段即可,这里面是activityID
3.可能要查其它字段,直接在绿色背景上标出即可,这里面是aa, bb, cc