爬虫面试案例系列01
### 需求:爬取https://m.vmall.com/help/hnrstoreaddr.htm荣耀线下门店中的门店详情信息。页面显示如下:
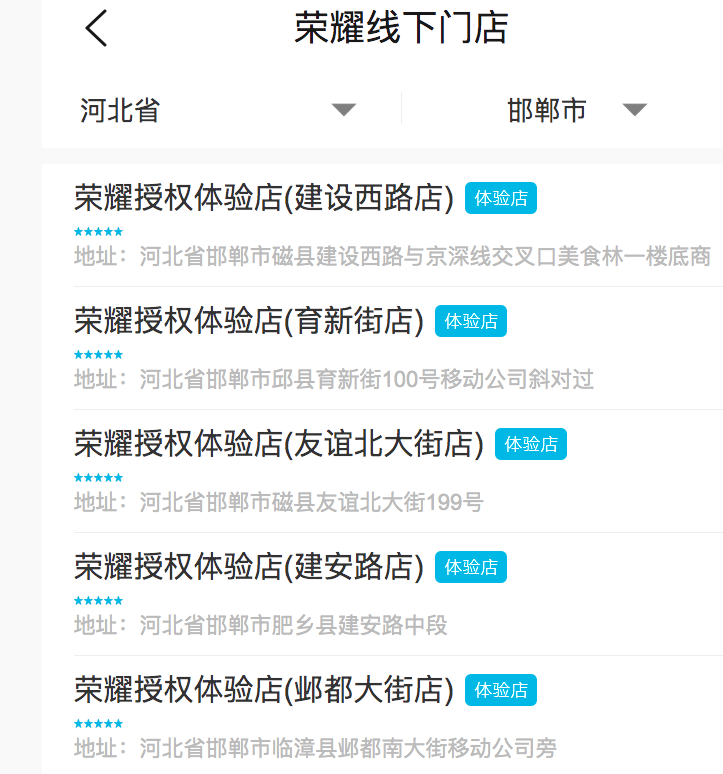
- 首页显示
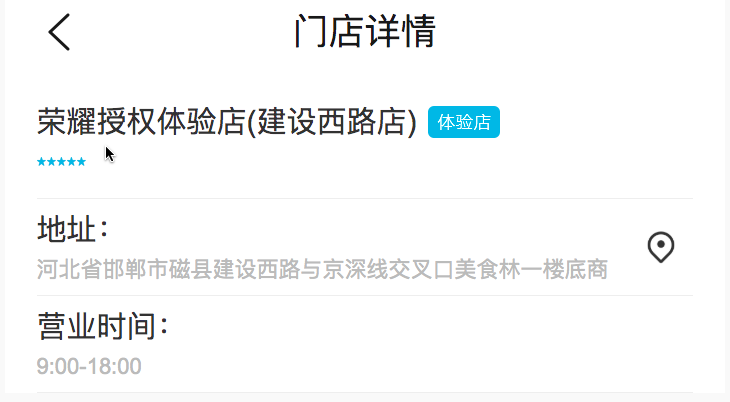
- 详情页显示
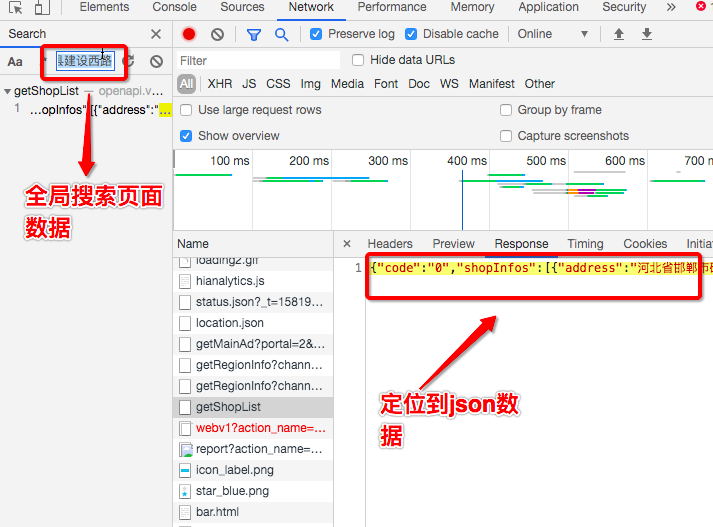
### 基于抓包工具分析如下:
- 
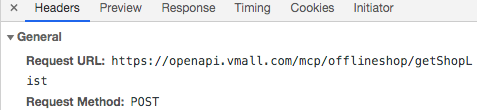
### 查看定位到数据包的请求头信息:
- 请求的url和请求方式如下:
- 请求携带的请求参数如下:

- 注意:请求参数为字典格式并非常规的键值对,所以在代码实现中需要使用dumps将字典转成json串作为请求参数
### 代码实现:爬取到首页对应的门店信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import requestsimport jsonurl = 'https://openapi.vmall.com/mcp/offlineshop/getShopList'data = { "portal":"2", "lang":"zh-CN", "country":"CN", "brand":"1", "province":"河北省", "city":"邯郸市", "pageNo":"2", "pageSize":"20"}#必须使用dumps操作json_data = requests.post(url,data=json.dumps(data)).json() |
- 请求到的数据为:
{ "code": "0", "shopInfos": [{ "address": "河北省邯郸市磁县建设西路与京深线交叉口美食林一楼底商", "brand": 1, "city": "邯郸市", "dist": "磁县", "distance": 0.0, "id": 111616, "isStar": 1, "latitude": "36.364752", "longitude": "114.390096", "name": "荣耀授权体验店(建设西路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "9:00-18:00", "shopCode": "RYRA03100602", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市邱县育新街100号移动公司斜对过", "brand": 1, "city": "邯郸市", "dist": "邱县", "distance": 0.0, "id": 111897, "isStar": 1, "latitude": "36.815125", "longitude": "115.173926", "name": "荣耀授权体验店(育新街店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03100954", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市磁县友谊北大街199号", "brand": 1, "city": "邯郸市", "dist": "磁县", "distance": 0.0, "id": 108067, "isStar": 1, "latitude": "36.387417", "longitude": "114.379099", "name": "荣耀授权体验店(友谊北大街店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03104185", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市肥乡县建安路中段", "brand": 1, "city": "邯郸市", "dist": "肥乡县", "distance": 0.0, "id": 111932, "isStar": 1, "latitude": "36.559004", "longitude": "114.813224", "name": "荣耀授权体验店(建安路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03100613", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市临漳县邺都南大街移动公司旁", "brand": 1, "city": "邯郸市", "dist": "临漳县", "distance": 0.0, "id": 111678, "isStar": 1, "latitude": "36.33081", "longitude": "114.613037", "name": "荣耀授权体验店(邺都大街店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03100610", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市成安县西关口西行200路南", "brand": 1, "city": "邯郸市", "dist": "成安县", "distance": 0.0, "id": 107586, "isStar": 1, "latitude": "36.447977", "longitude": "114.692388", "name": "荣耀授权体验店(政府街店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03103736", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市馆陶县新华街国土资源局斜对过", "brand": 1, "city": "邯郸市", "dist": "馆陶县", "distance": 0.0, "id": 111751, "isStar": 1, "latitude": "36.548521", "longitude": "115.294026", "name": "荣耀授权体验店(新华街店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03100615", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市武安市中兴路1666号", "brand": 1, "city": "邯郸市", "dist": "武安市", "distance": 0.0, "id": 106905, "isStar": 1, "latitude": "36.692459", "longitude": "114.191067", "name": "荣耀授权体验店(中兴路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03100255", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市永年区洺兴路电子一条街口", "brand": 1, "city": "邯郸市", "dist": "永年区", "distance": 0.0, "id": 111771, "isStar": 1, "latitude": "36.782304", "longitude": "114.494515", "name": "荣耀授权体验店(洺兴路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03100611", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市鸡泽县鸡泽镇会盟南大街89", "brand": 1, "city": "邯郸市", "dist": "鸡泽县", "distance": 0.0, "id": 111786, "isStar": 1, "latitude": "36.919418", "longitude": "114.882834", "name": "荣耀授权体验店(会盟南大街店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:00-18:30", "shopCode": "RYRA03100614", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市曲周县振兴路移动手机大卖场", "brand": 1, "city": "邯郸市", "dist": "曲周县", "distance": 0.0, "id": 107216, "isStar": 1, "latitude": "36.780474", "longitude": "114.964419", "name": "荣耀授权体验店(振兴路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "9:00-18:30", "shopCode": "RYRA03101174", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市武安市新华大街145号", "brand": 1, "city": "邯郸市", "dist": "武安县", "distance": 0.0, "id": 107729, "isStar": 1, "latitude": "36.695474", "longitude": "114.184811", "name": "荣耀授权体验店(新华大街店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03103735", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市大名县大名府路东段路南(妇幼保健院对过)", "brand": 1, "city": "邯郸市", "dist": "大名县", "distance": 0.0, "id": 111832, "isStar": 1, "latitude": "36.288208", "longitude": "115.171058", "name": "荣耀授权体验店(大名府路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:00-18:30", "shopCode": "RYRA03100612", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市广平县人民路166号", "brand": 1, "city": "邯郸市", "dist": "广平县", "distance": 0.0, "id": 108001, "isStar": 1, "latitude": "36.488035", "longitude": "114.957763", "name": "荣耀授权体验店(人民路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03103980", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市邯山区陵园路114号金茂大厦一楼", "brand": 1, "city": "邯郸市", "dist": "邯山区", "distance": 0.0, "id": 126945, "isStar": 1, "latitude": "36.59796329", "longitude": "114.4948675", "name": "荣耀授权体验店(陵园路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "8:30-18:30", "shopCode": "RYRA03100100", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "河北省邯郸市涉县振兴路与龙山大街交叉口东南角", "brand": 1, "city": "邯郸市", "dist": "涉县", "distance": 0.0, "id": 111607, "isStar": 1, "latitude": "36.567255", "longitude": "113.680533", "name": "荣耀授权体验店(振兴路店)", "pictures": [], "province": "河北省", "score": 5, "serviceTime": "9:00-18:00", "shopCode": "RYRA03100599", "starShopPic": "https://res.vmallres.com/pimages//offlineshop/FOMuBZyeqTWYYJgMLPP2.jpg", "type": 1 }, { "address": "中长街老检查院对面", "brand": 1, "city": "邯郸市", "dist": "鸡泽县", "distance": 0.0, "id": 137612, "isStar": 0, "latitude": "36.921823", "longitude": "114.882514", "name": "邯郸鸡泽航天中长街旗舰店", "pictures": [], "province": "河北省", "score": 4, "serviceTime": "10:00-18:30", "shopCode": "RY0000000001", "starShopPic": "", "type": 0 }, { "address": "磁州路130号", "brand": 1, "city": "邯郸市", "dist": "磁县", "distance": 0.0, "id": 137613, "isStar": 0, "latitude": "36.379835", "longitude": "114.395066", "name": "邯郸磁县盛尧磁州路电信店", "pictures": [], "province": "河北省", "score": 4, "serviceTime": "10:00-18:30", "shopCode": "RY0000000001", "starShopPic": "", "type": 0 }, { "address": "滏阳北大街新世纪商业广场1楼", "brand": 1, "city": "邯郸市", "dist": "峰峰矿区", "distance": 0.0, "id": 137614, "isStar": 0, "latitude": "36.428341", "longitude": "114.217691", "name": "邯郸峰峰太行新世纪店", "pictures": [], "province": "河北省", "score": 4, "serviceTime": "10:00-18:30", "shopCode": "RY0000000001", "starShopPic": "", "type": 0 }, { "address": "建设街移动公司路南西侧泰山通讯", "brand": 1, "city": "邯郸市", "dist": "肥乡区", "distance": 0.0, "id": 137625, "isStar": 0, "latitude": "36.559058", "longitude": "114.811038", "name": "邯郸肥乡泰山建设街店", "pictures": [], "province": "河北省", "score": 4, "serviceTime": "10:00-18:30", "shopCode": "RY0000000001", "starShopPic": "", "type": 0 }], "success": true, "totalRows": 60} |
- 请求到的数据分析:
- 数据为门店相关数据,其中每一个门店有其对应的一个id值,我们需要将id值解析出来,在后面请求详情页会使用到
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import requestsimport jsonurl = 'https://openapi.vmall.com/mcp/offlineshop/getShopList'data = { "portal":"2", "lang":"zh-CN", "country":"CN", "brand":"1", "province":"河北省", "city":"邯郸市", "pageNo":"2", "pageSize":"20"}#从中解析出idjson_data = requests.post(url,data=json.dumps(data)).json()for dic in json_data['shopInfos']: _id = dic['id'] #解析出门店的id值 |
### 请求每一个门店详情页的数据

- 请求的url和请求方式:

- 请求参数:

发现只有shopId为动态变化的请求参数其他都是固定不变的,然后该shopId就是上一步我们解析出来的门店id,则基于门店id作为请求详情页的请求参数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import requestsimport jsonurl = 'https://openapi.vmall.com/mcp/offlineshop/getShopList'data = { "portal":"2", "lang":"zh-CN", "country":"CN", "brand":"1", "province":"河北省", "city":"邯郸市", "pageNo":"2", "pageSize":"20"}#从中解析出idjson_data = requests.post(url,data=json.dumps(data)).json()for dic in json_data['shopInfos']: _id = dic['id'] #拼接详情页的url detail_url = 'https://openapi.vmall.com/mcp/offlineshop/getShopById?portal=2&version=10&country=CN&shopId={}&lang=zh-CN'.format(_id) finally_data = requests.get(url=detail_url).json() print(finally_data)#每一页详情页url的数据 |
【推广】
免费学中医,健康全家人
原文地址:https://www.cnblogs.com/duhong0520/p/13284022.html
- 推荐文章
- 完美解决固定容器高度,文字内容一行或多行,文字上下居中,解决兼容性
- 使用vue给导航栏添加链接
- 有关vue的总结
- 分页插件代码
- JSON.stringify 在OA差旅中转换为字符串传给后端,(使用from表单的形式)
- JSON.stringify的使用方法
- $.map和$.extend来复制数组(OA差旅)
- 改动位置
- 远程调试js注意事项
- 令子元素垂直居中(并且子元素的高度不固定)
- 筛选条件代码
- 跟我学算法-Logistic回归
- 跟我学算法-集成算法
- 跟我学算法
- 跟我学算法-决策树
- 跟着太白老师学python day11 可迭代对象和迭代器
- 跟着太白老师学python day11 闭包 及在爬虫中的基本使用
- 跟着太白老师学python day11 函数名的应用 globals(), locals()
- 跟着太白老师学python day10 函数嵌套, global , nonlocal
- 跟着太白老师学python day10 名称空间,作用域和取值顺序,变量的加载顺序
- 跟着太白老师学python 10day 函数的动态参数 *args, **kwargs, 形参的位置顺序
- IO 流之字符流的缓冲区
- Java IO异常处理方式
- Java IO 流
- Java 其他对象的 API
- Java 集合框架之 JDK 1.5 新特性
- Java 集合框架工具类
- Java 集合框架之 Map
- Java 集合框架查阅技巧
- Java 集合框架之泛型