由于主流网站都使用JavaScript展示网页内容,和前面简单抓取静态网页不同的是,在使用JavaScript时,很多内容并不会出现在HTML源代码中,而是在HTML源码位置放上一段JavaScript代码,最后呈现出来的数据是通过JavaScript提取服务器返回的数据加载到源代码中进行呈现。因此爬取静态网页的技术可能无法正常使用。因此,我们需要用到动态网页抓取的两种技术:
1.通过浏览器审查元素解析真实网页地址;
2.使用selenium模拟浏览器的方法。
我们这里先介绍第一种方法。
以爬取《Python 网络爬虫:从入门到实践》一书作者的个人博客评论为例。网址:http://www.santostang.com/2017/03/02/hello-world/
1)“抓包”:找到真实的数据地址
右键点击“检查”,点击“network”,选择“js”。刷新一下页面,选中页面刷新时返回的数据list?callback....这个js文件。右边再选中Header。如图:
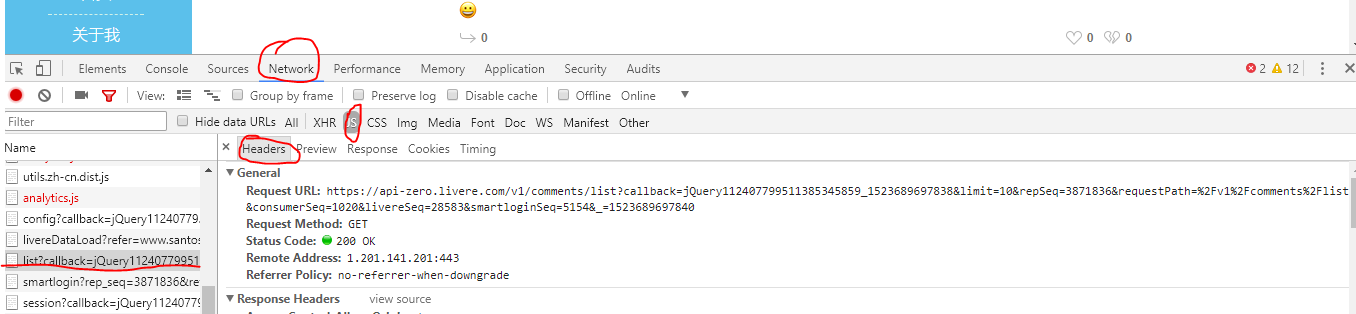
其中,Request URL即是真实的数据地址。
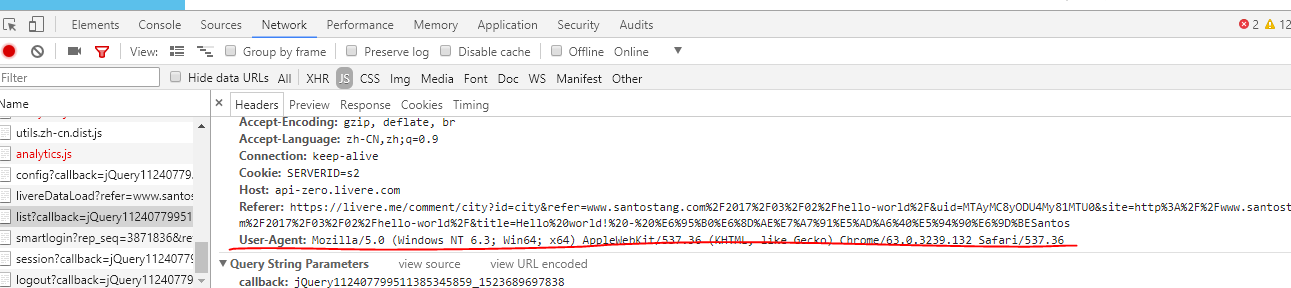
在此状态下滚动鼠标滚轮可发现User-Agent。
2)相关代码:
import requests import json headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} link="https://api-zero.livere.com/v1/comments/list?callback=jQuery112405600294326674093_1523687034324&limit=10&offset=2&repSeq=3871836&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1523687034329" r=requests.get(link,headers=headers) # 获取 json 的 string json_string = r.text json_string = json_string[json_string.find('{'):-2] json_data=json.loads(json_string) comment_list=json_data['results']['parents'] for eachone in comment_list: message=eachone['content'] print(message)
输出为:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗? 为何静态网页抓取不了? 奇怪了,我按照书上的方法来操作,XHR也是空的啊 XHR没有显示任何东西啊。奇怪。 找到原因了 caps["marionette"] = True 作者可以解释一下这句话是干什么的吗 我用的是 pycham IDE,按照作者的写法写的,怎么不行 对火狐版本有要求吗 4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应 from selenium import webdriver from selenium.webdriver.firefox.firefox_binary import FirefoxBinary caps = webdriver.DesiredCapabilities().FIREFOX caps["marionette"] = False binary = FirefoxBinary(r'C:Program FilesMozilla Firefoxfirefox.exe') #把上述地址改成你电脑中Firefox程序的地址 driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps) driver.get("http://www.santostang.com/2017/03/02/hello-world/") 我是番茄 为什么刷新没有XHR数据,评论明明加载出来了
代码解析:
1)对于代码 json_string.find() api解析为:
Docstring: S.find(sub[, start[, end]]) -> int Return the lowest index in S where substring sub is found, such that sub is contained within S[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. Type: method_descriptor
所以代码 json_string.find('{') 即返回”{“在json_string字符串中的索引位置。
2)若在代码中增加一句代码 print json_string,则该句输出结果为(由于输出内容过多,只截取了开头和结尾,关键位置均作了红色标记):
/**/ typeof jQuery112405600294326674093_1523687034324 === 'function' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256433/B9E06FBF9013D49CADBB5B623E8226C8/100","memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松 Santos","site":"http://www.santostang.com/2017/03/02/hello-world/","email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?" 。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
由上面输出结果可知,我们在代码中加入 json_string = json_string[json_string.find('{'):-2]的重要性。
若不加入json_string.find('{')则该结果不是合法的json格式,不能顺利构成json文件;若不截取到倒数第二位,则结果包含多余的);也构不成合法的json格式。
3)对于代码comment_list=json_data['results']['parents']和message=eachone['content'] 中的中括号中的字符串类型的标签定位,可在上面2)中关键部位查找,即完成截取后的合法的json文件由“results”和“parents”两者所包含故使用两个中括号逐级定位,又由于我们爬取的是评论,其内容在该json文件的“content”标签中,故使用["content"]进行定位。
据观察,在真实的数据地址中的offset是页数。
爬取所有页面的评论:
import requests import json def single_page_comment(link): headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} r=requests.get(link,headers=headers) # 获取 json 的 string json_string = r.text json_string = json_string[json_string.find('{'):-2] json_data=json.loads(json_string) comment_list=json_data['results']['parents'] for eachone in comment_list: message=eachone['content'] print(message) for page in range(1,4): link1="https://api-zero.livere.com/v1/comments/list?callback=jQuery112405600294326674093_1523687034324&limit=10&offset=" link2="&repSeq=3871836&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1523687034329" page_str=str(page) link=link1+page_str+link2 print(link) single_page_comment(link)
输出为:
https://api-zero.livere.com/v1/comments/list?callback=jQuery112405600294326674093_1523687034324&limit=10&offset=1&repSeq=3871836&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1523687034329 在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。 在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。 在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。 测试 为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗? 菜鸟一只,求学习群 lalala1 我来试一试 :smiley: 我来试一试 :smiley: 应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了 :grinning: https://api-zero.livere.com/v1/comments/list?callback=jQuery112405600294326674093_1523687034324&limit=10&offset=2&repSeq=3871836&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1523687034329 现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗? 为何静态网页抓取不了? 奇怪了,我按照书上的方法来操作,XHR也是空的啊 XHR没有显示任何东西啊。奇怪。 找到原因了 caps["marionette"] = True 作者可以解释一下这句话是干什么的吗 我用的是 pycham IDE,按照作者的写法写的,怎么不行 对火狐版本有要求吗 4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应 from selenium import webdriver from selenium.webdriver.firefox.firefox_binary import FirefoxBinary caps = webdriver.DesiredCapabilities().FIREFOX caps["marionette"] = False binary = FirefoxBinary(r'C:Program FilesMozilla Firefoxfirefox.exe') #把上述地址改成你电脑中Firefox程序的地址 driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps) driver.get("http://www.santostang.com/2017/03/02/hello-world/") 我是番茄 为什么刷新没有XHR数据,评论明明加载出来了 https://api-zero.livere.com/v1/comments/list?callback=jQuery112405600294326674093_1523687034324&limit=10&offset=3&repSeq=3871836&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1523687034329 为什么刷新没有XHR数据,评论明明加载出来了 为什么刷新没有XHR数据,评论明明加载出来了 第21条测试评论 第20条测试评论 第19条测试评论 第18条测试评论 第17条测试评论 第16条测试评论 第15条测试评论 第14条测试评论
注意:page变量取自int,进行字符串拼接前需要进行转换,即page_str=str(page)
参考书目:唐松,来自《Python 网络爬虫:从入门到实践》