今日学习内容概览:
今天主要阅读了一篇论文Temporal Segment Networks:Towards Good Practices for Deep Action Recognition(时间片段网络面向深度动作识别的良好实践),这篇ECCV2016的文章主要提出了TSN(temporal segment network)结构,被用来做视频的动作识别。TSN可以看做是双流(Two stream)系列的改进(双流网络——论文链接)。改论文主要解决了以下两个问题:
- 如何对长时间视频进行行为判断。
- 处理数据量少的问题,如何防止过拟合现象。
TSN网络结构如下:
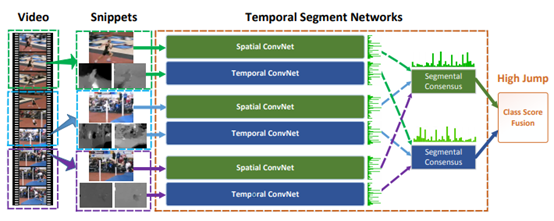
时间段网络:将一个输入视频分为K个段,并从每个段中随机选择一个简短的代码段。 不同片段的类别分数由分段共识函数融合,以产生分段共识,这是视频级别的预测。 然后将来自所有模态的预测进行融合以产生最终预测。 所有摘录上的ConvNets共享参数。
这里 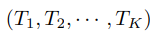 是一个片段序列。从其对应的片段
是一个片段序列。从其对应的片段 中随机采样每个片段
中随机采样每个片段 。
。 是表示带有参数W的ConvNet的函数,该函数在短代码段Tk上运行并为所有类别产生类别分数。分段共识函数G组合了多个简短摘要的输出,以获得其中的类假设的共识。基于此共识,预测函数H预测整个视频的每个动作类别的概率。在这里,我们选择H的广泛使用的Softmax函数。结合标准的分类交叉熵损失,关于分段共识的最终损失函数
是表示带有参数W的ConvNet的函数,该函数在短代码段Tk上运行并为所有类别产生类别分数。分段共识函数G组合了多个简短摘要的输出,以获得其中的类假设的共识。基于此共识,预测函数H预测整个视频的每个动作类别的概率。在这里,我们选择H的广泛使用的Softmax函数。结合标准的分类交叉熵损失,关于分段共识的最终损失函数 形成为
形成为
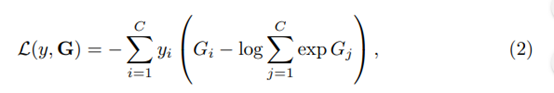
防止过拟合措施
为了防止过拟合,作者采取了多个措施:
- 交叉预训练。以图像为输入的spatial ConvNets网络可以用在imagenet数据集上预训练的网络来初始化。以光流作为输入的temporal stream ConvNets网络就通过交叉预训练进行初始化。交叉预训练其实是将图像领域的预训练模型迁移到光流领域。
- partial BN,通过冻结除第一个BN层以外的所有BN层的均值和方差。
网络结果测试
-
不同训练策略下双流网络的效果对比

-
关于网络的几种不同输入形式下two stream convnets的效果对比,数据集是UCF101

-
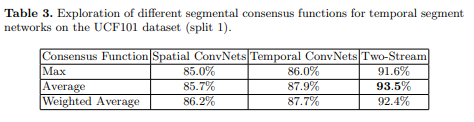
关于前面TSN公式中的不同g函数对实验结果的影响
-
在UCF101数据集(split 1)上探索不同的非常深的ConvNet架构
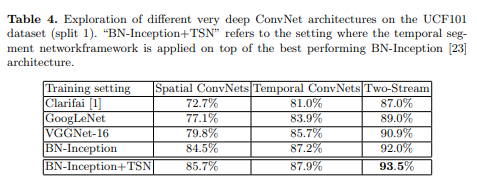
-
总结本文的一些基于双流网络的改进效果
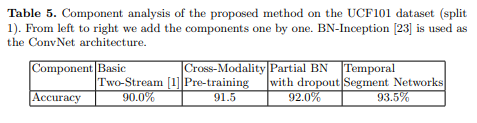
-
和其他视频行为识别算法在HMDB51和UCF101数据集上的对比
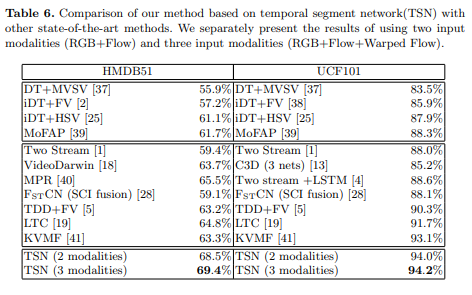
网络可视化

使用DeepDraw[42]进行动作识别的ConvNet模型的可视化。我们比较了三种情况:(1)没有预训练;
(2)pre-train;(3)时间段网络。对于空间卷积神经网络,我们绘制了三个生成的可视化彩色图像。
对于时间对流,我们用灰度绘制x(左)和y(右)方向的流图。注意,所有这些图像都是由纯随机像素生成的。