从生意社爬取数据
从采集> 保存到db3> 读取数据库 的一条龙服务
输出:
用FILE explorer来查看的数据库文件截图:
用Variable explorer 来查看的全局变量变量列表, 用Array editor来查看的dataframe截图:
变量列表:

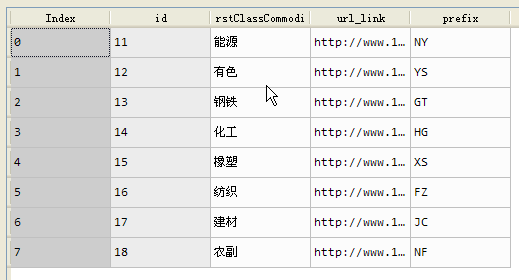
一类商品表:
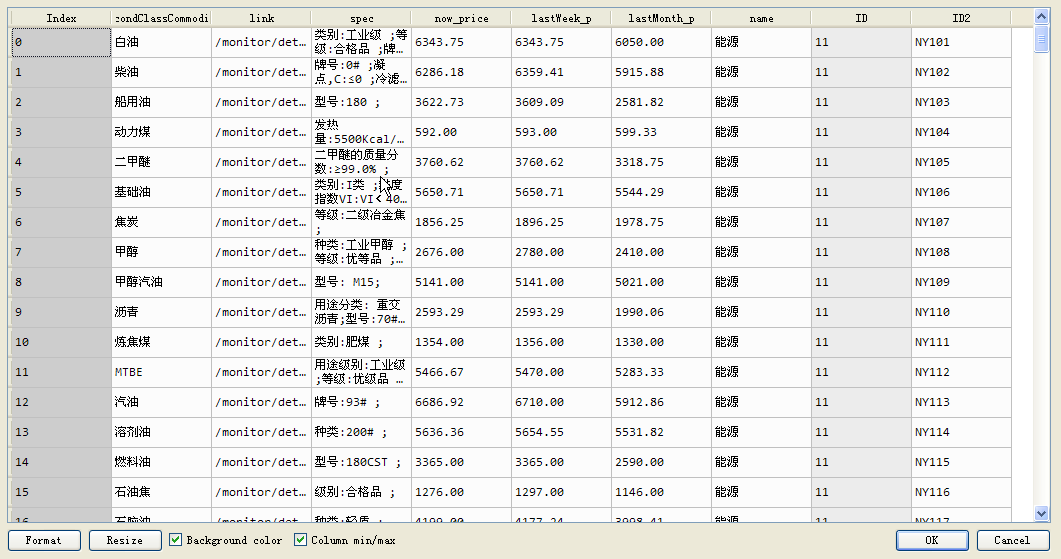
二类商品表:
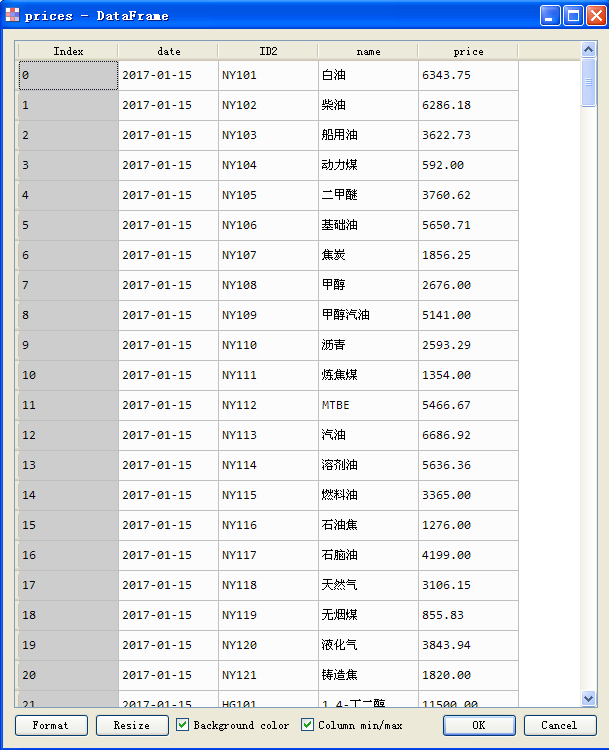
监测商品价格表:
代码
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 13 08:36:58 2017
@author: Administrator
"""
from pprint import pprint
import sys
import requests
from lxml import etree
from bs4 import BeautifulSoup
import sqlite3 as sql
import numpy as np
import pandas as pd
from datetime import datetime
#soup = BeautifulSoup(ihtml, 'lxml', from_encoding='utf-8') # 显示地声明解析器, 否则会有警告
#soup = BeautifulSoup(ihtml, 'lxml', from_encoding=iencoding) # 显示地声明解析器, 否则会有警告
u'''
3种方式查看帮助之:初始化一个soup对象
在edit里面: 键入`BeautifulSoup.__init__()`, 然后ctrl+i, 帮助发送到Obj_Inspector
在Ipython console里面: 键入: `BeautifulSoup.__init__()??`, 然后回车
在Obj_Inspector里面: 首先在来源多选框里选择'console', 然后在Object组合框里键入或者选择
bs4.BeatifulSoup.__init__ ==>帮助信息出来了.
如果还想看源代码的话, 请点击右侧的options图标按钮, 选择"show source"显示源代码
def __init__(self, markup="", features=None, builder=None,
parse_only=None, from_encoding=None, exclude_encodings=None,
**kwargs):
'''
def idom(url):
u'''
功能:
获取url对应的Dom对象, 返回Element Tree对象
param:
url: 要访问的网页的url地址
return:
Element Tree对象, 网页的DOM节点树
'''
#url='http://www.100ppi.com/monitor/'
resp=requests.get(url)# 发送 GET 请求, 返回response对象
html = resp.text # 响应对象的文本属性
#encoding = resp.encoding
dom = etree.HTML(html) # 返回root node of the document
return dom
def crawle_firstClassCommodity(
dom,
anchor_path='//div[starts-with(@class,"title_b2")]/span/a'):
u'''
功能:
从生意社网站, 抓取一级分类的大宗商品名称, 商品价格监测的连接地址
param:
dom:
anchor_path:
return:
dataframe of 第一级分类商品的数据框, 列名称为:['id','firstClassCommodity','url_link']
'''
# F12=> 审查元素=> 右击元素的属性区=>选择edit Attribute=> select and copy
# class="title_b2 w666 fl", 对于这种复杂的属性值, 匹配时需要用starts-with函数
# 比如: [starts-with(@class, "title_b2")], 否则属性无法匹配
anchors = dom.xpath(anchor_path)
# xpath方法返回的总是list对象, 即便是只有一个元素
# 用锚点标签(计算过程里的中间变量或者叫上下文节点)的xpath方法, 分别获取它的属性值和上层的文本.
# 获取它的href属性值: .xpath('@href')[0]
# 获取它的上层文本: .xpath('text()')[0]
firstClassCommodity= []
link = []
for each in anchors: # each means each_anchor, 每一个锚点标签
#print
#print '字典的项目{}'.format(each.attrib.items())
#print '字典的键',each.attrib.keys()
#print '字典的值', each.attrib.values()
#print '该a标签的href属性的值=', each.attrib.get('href')
#print each.xpath('text()')[0]
#.xpath(//text()) .xpath(/text()) .xpath(text()), .xpath(text())[0]
#注意上述的四个个表达式得到截然不同的结果, 最后一个的才是正确的
firstClassCommodity.append(each.xpath('text()')[0])
#link.append(url + each.attrib.get('href') ) # 获取属性, 通过操作元素字典的方法
#print each.xpath('@href')[0] # 获取属性, 通过元素的xpath方法
link.append(url + each.xpath('@href')[0] )
data = {'firstClassCommodity':firstClassCommodity,
'url_link': link,
'id': [int(e[-2:]) for e in link]
}
df = pd.DataFrame(data,
#index= data['id'],
columns=['id','firstClassCommodity','url_link']
)
#df=df.sort_index()
df=df.sort_values(by='id') #按id列递增排序
df=pd.DataFrame(df.values, columns=df.columns)
s='NY|YS|GT|HG|XS|FZ|JC|NF'
df['prefix'] = s.split('|')
#print df
return df
#list_text=dom.xpath('//div/span/a/text()')
#for each in list_text:
# print each
def crawle_secondClassCommodity(dom, table_path='//table[@width="100%"]'):
u'''
功能:
从生意社网站, 抓取二级分类的大宗商品名称, 商品价格监测的连接地址
param:
dom:
table_path:
return:
df of 列名称: []
'''
table = dom.xpath(table_path)[0]
rows = table.xpath('tr')
h=[]
h2=[]
for row in rows:
anchor=row.xpath('td/a')
if len(anchor)>0:
anchor=anchor[0]
text=anchor.xpath('text()')[0]
link=anchor.xpath('@href')[0]
h.append([text, link])
datas = row.xpath('td/text()')
row2=[]
for data in datas:
row2.append(data)
#print row2
h2.append(row2)
last_date = h2[0:1][0][0:1][0]
#pprint( last_date) # '(2017-01-15)'
dt_last_date=datetime.strptime(last_date[1:11], '%Y-%m-%d').date()
#print dt_last_date
#pprint(h2)
df=pd.DataFrame(h, columns=['secondClassCommodity', 'link'])
#print df
#pprint(h2)
# 整理df2:
# 整理第一行: 第一列插入一个空值,
# 删除第2行, 重构(index)
columns = ['spec','now_price','lastWeek_p','lastMonth_p']
df2=pd.DataFrame(h2, columns=columns)
s=df2.ix[0,:]
s.values[1:4]=s.values[0:3]
s.values[0]=None
df2.ix[0,:] = s.values
df2=df2.drop(1,axis=0,inplace=False)
df2=pd.DataFrame(df2.values, columns=columns)
idf= pd.concat([df,df2], axis=1)
return idf,dt_last_date
def test1():
u'''
#####################
#基本用法:
#####################
'''
html = '''
<head>
<meta charset="utf-8"/>
<body>
<h1 class="header">登录</h1>
<form action="/login" method="post">
<label for="username">用户: </label><input type="text" name="username" />
<label for="password">密码:</label><input type="password" name="password" />
<input type="submit" value="Submit" />
</form>
</body>
</head>
'''
# 生成DOM
dom = etree.HTML(html)
# 取内容 /text()
contents = dom.xpath('//h1[@class="header"]/text()')
#print(contents[0])
print contents[0]
# 取属性 /@attrib
attribs = dom.xpath('//form/label[@for="username"]/@for')
#print(attribs[0])
print attribs[0]
def test2():
u'''
#####################
#复杂用法:
#####################
'''
html2 = '''
<head>
<meta charset="utf-8"/>
<body>
<div class="content">
==> 有相同字符开头的属性的标签:
<p id="test-1">需要的内容1</p>
<p id="test-2">需要的内容2</p>
<p id="test-default">需要的内容3</p>
</div>
<div class="question">
==> 签嵌套标签:
<p id="class3">美女,
<font color="red">你的微信号是多少?</font>
</p>
</div>
</body></head>
'''
dom = etree.HTML(html2)
# 取有相同字符开头的属性的标签的内容 starts-with(@attrib, "abcd")
contents2 = dom.xpath('//p[starts-with(@id, "test")]/text()')
#print(contents2)
#pprint(contents2)
for e in contents2:
#pprint(e)
print e
# 取标签嵌套标签的所有内容 xpath('string(.)')
contents3 = dom.xpath('//div[@class="question"]/p')[0].xpath('string(.)')
contents3 = contents3.replace('
', '').replace(' ', '')
print(contents3)
def concat_2ndCommodity(df,df2, dt_last_date):
u'''
功能
----
合并第二类商品, 生成一个267行的数据框, 添加了一类和二类商品的ID编号
param
----
df :
第一类大宗商品数据表
df2 :
第二类大宗商品数据表, 但是里面有多余的行需要删除
dt_last_date :
从crawl_secondClassCommodity()函数返回的日期,
也就是网页里大宗商品的最新价格对应的日期
return
----
df_all : 267行9列的数据框(267种大宗商品的分类表)
price : 267种商品的最新行情数据表
'''
#mask=[]
#for v in df2.secondClassCommodity.values:
# mask.append(v in df.firstClassCommodity.values)
mask=[v in df.firstClassCommodity.values for v in df2.secondClassCommodity.values]
#print df2[mask].ix[:,0:3]
df3=df2[mask]
list1 = df3.index.values.tolist()
list1.append(len(df2))
i=0
for v in list1:
if i==0:
i+=1
continue
else:
fClassName = df2.ix[list1[i-1], 'secondClassCommodity']
mask_name = df.firstClassCommodity==fClassName
fClassID = df[mask_name].id.values[0]
fClassPrefix = df[mask_name].prefix.values[0]
#print u'第一类商品name and ID are: ', fClassName, fClassID
#print u'该商品的索引范围为: ', list1[i-1]+1, v-1
lv = list1[i-1] + 1
#df_tmp = df2.ix[lv:v-1,('secondClassCommodity','spec',)]
#df_tmp = df2.ix[lv:v-1, :] # 会有警告:SettingWithCopyWarning:
df_tmp = df2.ix[lv:v-1, :].copy() #切片之后还要添加列数据, 所以要用切片的copy()
df_tmp['name']=fClassName
df_tmp['ID']=fClassID
df_tmp = pd.DataFrame(df_tmp.values, columns=df_tmp.columns) #重构df的index
list_id2 = [fClassPrefix + str(v) for v in df_tmp.index.values + 101]
df_tmp['ID2'] = list_id2
#print df_tmp.ix[:,('secondClassCommodity','name','ID','spec',)]
if i==1:
df_all=df_tmp
elif i>1:
df_all = pd.concat([df_all,df_tmp])
i+=1
df_all = pd.DataFrame(df_all.values, columns=df_all.columns)
price=pd.DataFrame(
{
'date':dt_last_date, # 可爱的pandas竟然能自动地把一个日期转为日期序列, 太棒了! awsome!
'ID2': df_all.ID2,
'name': df_all.secondClassCommodity,
'price': df_all.now_price,
}, columns=['date','ID2', 'name', 'price'])
return df_all, price
def createTableInDB_and_InsertData(df, tableName, DB='100ppi.db3'):
u'''
功能
----
依据df创建sqlite数据库, 数据表
param
-----
df:
数据框
tablename:
数据库里的表名
DB:
sqlite3类型的数据库文件名
return
-----
db3文件
example
------
createTableInDB_and_InsertData(df, 'fcc') # fcc means firstClassCommodity
'''
#ls
con = sql.connect(DB)
df.to_sql(tableName, con)
#%%
if __name__=='__main__':
#df.reindex
url='http://www.100ppi.com/monitor/'
#==============================================================================
# dom=idom(url)
# df=crawle_firstClassCommodity(dom)
# df2,dt = crawle_secondClassCommodity(dom)
# #print df2.head(10).ix[:,(0,3, 2)]
# df_all, price = concat_2ndCommodity(df,df2,dt)
#==============================================================================
#createTableInDB_and_InsertData(df, 'fcc') # fcc means firstClassCommodity TABLE in DB
#createTableInDB_and_InsertData(df_all, 'scc') # scc means secondClassCommodity TABLE in DB
#createTableInDB_and_InsertData(price, 'prices') # prices means prices TABLE in DB
#==============================================================================
# con=sql.connect('100ppi.db3')
# df = pd.read_sql_query('select * from fcc',con, index_col='index')
# df2 = pd.read_sql_query('select * from scc',con, index_col='index')
# prices = pd.read_sql_query('select * from prices',con, index_col='index')
#
# url_base = 'http://www.100ppi.com'
# mask= df2.secondClassCommodity==u'白糖'
# sugar_link = url_base + df2[mask].link.values[0]
# print 'sugar_link: {}'.format(sugar_link)
# mask= df2.name==u'农副'
# #print u'
农副商品:
{}'.format(df2[mask].ix[:,('secondClassCommodity','ID2','link')])
#==============================================================================