KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法,由他们的名字首字母组成)。
KMP算法的关键是利用已经部分匹配的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。
在介绍KMP之前先说一说朴素解法,也就是最简单的暴力解法,朴素解法是采用穷举的方式一个一个对比达到查找的功能,模式串与主串匹配失败后又要重新从模式串的开头继续匹配,不考虑模式串已经判断过的字符,所以效率差。
下面是朴素解法的实现代码:
int sub_str_index(const char* s, const char* p) // s是主串,p是模式串 { int ret = -1; // ret记录返回值,初始化为-1表示没有找到 int sl = strlen(s); int pl = strlen(p); int len = sl - pl; // len记录主串的查找边界,避免主串剩余字符不足,提高效率 for(int i=0; (ret<0) && (i<=len); i++) // 如果没有找到匹配的,且主串不会到边界 { bool equal = true; // equal用于记录临时的匹配情况,为了下面的循环,默认为真 for(int j=0; equal && (j<pl); j++) // 判断当前位置主串是否与模式串完全匹配 equal = (s[i + j] == p[j]); ret = (equal ? i : -1); // 如果模式串全部匹配成功就返回匹配主串首字符的下标,否则返回-1表示失配 } return ret; }
接下来介绍KMP算法:
KMP算法是利用已知的信息减少无效匹配判断的一种算法。
这是阮一峰的讲解,我觉得非常好,供参考:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
另外youtube上的黄浩杰也讲的不错,方便的朋友可以去看看。
下面这张图来自阮一峰博客,我做了一些修改,用它来举例子:

经过几次查找后,这里模式串的D和主串的空格失配了,为了提高查找效率,我们发现直接把模式串向后移动4位可以更高效的匹配,因为主串当前的3个字符都不能和模式串匹配,从而省去了前面3次匹配的过程,实现效率的提升。
这个例子是要右移4位,4是怎么来的呢,是通过模式串已经匹配的最后一个字符的位置(这里就是模式串的第6个字符B,数组下标为5)减去模式串最长匹配数2得到的,那2又是怎么来的呢,2是模式串前缀与模式串后缀最多能匹配的字符个数,也就是部分匹配值
首先我们要先搞懂什么是前缀、后缀、部分匹配值以及部分匹配表
拿上面的模式串"ABCDABD"来说
前缀就是取从开头到任意一个字符的子串;后缀则是取任意一个字符到末尾的子串;当然长度为0或者为模式串的总长度就没有意义了,所以这两个长度不计算

下面这幅图是在部分匹配成功后又匹配失败的部分匹配值计算演示图;
现在假设需要匹配第7个字符D(数组下标为6),注意D左边的B和A都匹配成功了,这时候直接使用最后一个匹配字符也就是前一个字符B(第6个字符)在前缀中的位置的部分匹配值;最后一个匹配字符是第6个字符B,它所对应的前缀位置通过它自己的部分匹配表记录了(也就是2),这就是说这个字符B和模式串第2个字符(数组下标为1)是对应的,第二个字符B的部分匹配值为0,所以不能匹配的第7个字符的部分匹配值也是0;
 最长匹配字符数就是最终的部分匹配值
最长匹配字符数就是最终的部分匹配值
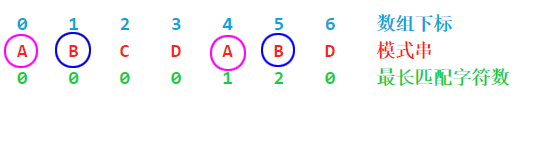
部分匹配值就是某个后缀最多与前缀匹配的字符个数,上面这张图可以看到前缀是A开头,所以后缀也得是A开头才能匹配,这时候有ABD这个后缀能匹配,再贪婪一点,还能匹配更多吗,发现最多只能匹配2个字符,所以它的部分匹配值就是2;
部分匹配表是记录部分匹配值的一个数据结构,因为我们能匹配的模式串长度是不确定的,所以需要针对每个位置生成一个部分匹配值
这里就要用到KMP算法的部分匹配表了,部分匹配表用于记录模式串前缀与模式串后缀最多能匹配的字符个数;通过这个计数我们就能知道移动的位数了,因为它记录了当前字符最长匹配的字符个数,所以得出下面的公式:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
使用计算公式我们就可以计算出右移的位数,已匹配字符数为6(已匹配ABCDAB),最后一个匹配的字符B的部分匹配表为2,所以右移6-2=4位.
网上很多人把这个部分匹配表写成next数组,我这里根据老师的代码写成了int类型的指针,用堆空间记录,长度与模式串长度一致,每个单位为int类型,等效于int数组。
int* make_pmt(const char* p)· // 部分匹配表生成函数,给定模式串指针作为参数,返回int*记录部分匹配表,可充当数组使用,长度为模式串长度;参数合法性由调用者判断 { int len = strlen(p); int* ret = static_cast<int*>(malloc(sizeof(int) * len)); // 申请堆空间用于记录部分匹配表,使用者需要释放 if( ret != NULL ) // 只有堆空间申请成功才能操作 { int ll = 0; // ll==>longest length,最长部分匹配值,初始化最长部分匹配值为0 ret[0] = 0; // 第一个元素没有匹配的所以直接写为0 for(int i=1; i<len; i++) // 从第二个元素开始遍历 { while( (ll > 0) && (p[ll] != p[i]) ) // 如果已经有匹配过的字符,但是下一个字符不匹配 { ll = ret[ll-1]; // 把ll重置为模式串的第ll个字符的部分匹配值,数组下标从0开始所以要减1,p[11-1]的部分匹配值存储于ret[ll-1]; } if( p[ll] == p[i] ) // 每匹配成功一个字符ll就递增 { ll++; } ret[i] = ll; // 进入下一轮循环前要把ll值保存进部分匹配表,即ret[i]记录p[i]的最长部分匹配表 } } return ret; }
下面是kmp函数:
int String::kmp(const char* s, const char* p) // s主串,p模式串 { int ret = -1; int sl = strlen(s); int pl = strlen(p); int* pmt = make_pmt(p); // 获取子串的部分匹配表,注意该函数返回的是堆空间,用完需要释放 if( (pmt != NULL) && (0 < pl) && (pl <= sl) ) // 只有当部分匹配表获取成功、模式串长度大于0且不超过源串长度的时候才需要计算 { for(int i=0, j=0; i<sl; i++) // for初始化i和j变量,i用于遍历每个主串的字符,j用于记录已匹配的模式串字符数 { while( (j > 0) && (s[i] != p[j]) ) // 有已匹配字符但是后续字符又匹配失败时 { j = pmt[j-1]; // 移动模式串,使模式串第一个字符对齐到主串下一个匹配的字符位置,这是一次性移动,不再是暴力搜索中的每次只移动一次 } if( s[i] == p[j] ) // 如果匹配成功,记录匹配模式串字符个数的j加1 { j++; } if( j == pl ) // 如果当前已匹配的模式串字数与模式串长度相等说明匹配成功 { ret = i + 1 - pl; // 返回匹配源串的第一个字符的下标并跳出循环结束寻找;此时i指向的是匹配的主串的最后一个字符,减去子串长度后等于第一个匹配的字符的前一个,所以要加1往后挪一个 break; } } } free(pmt); // 记得释放部分匹配值生成函数申请的堆空间 return ret; }