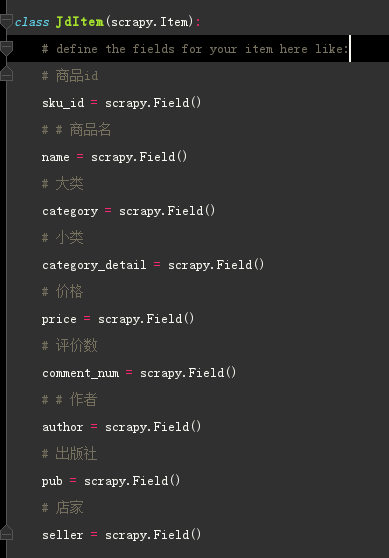
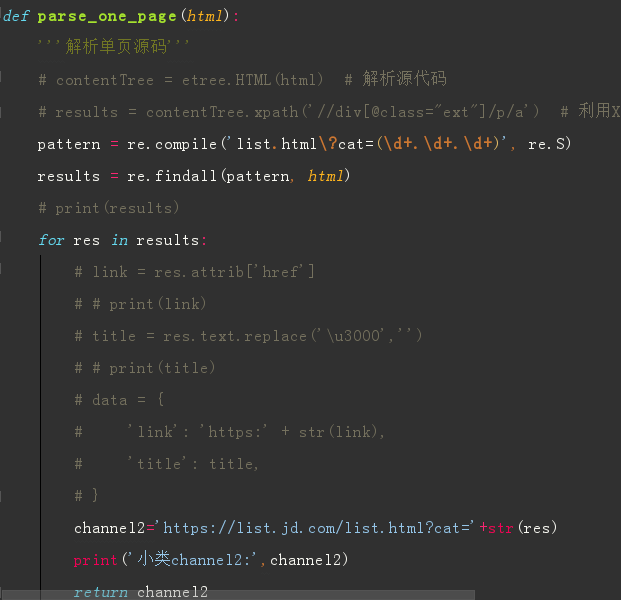
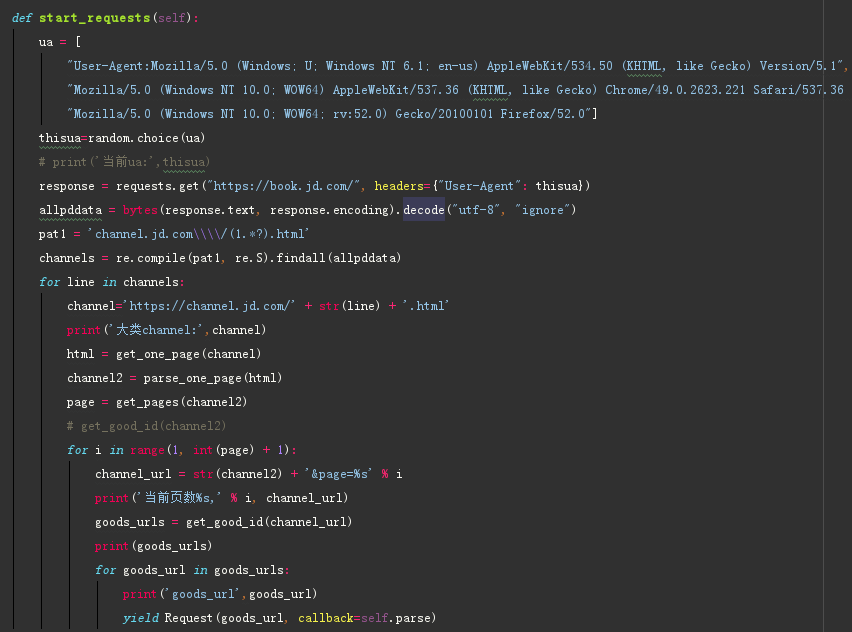
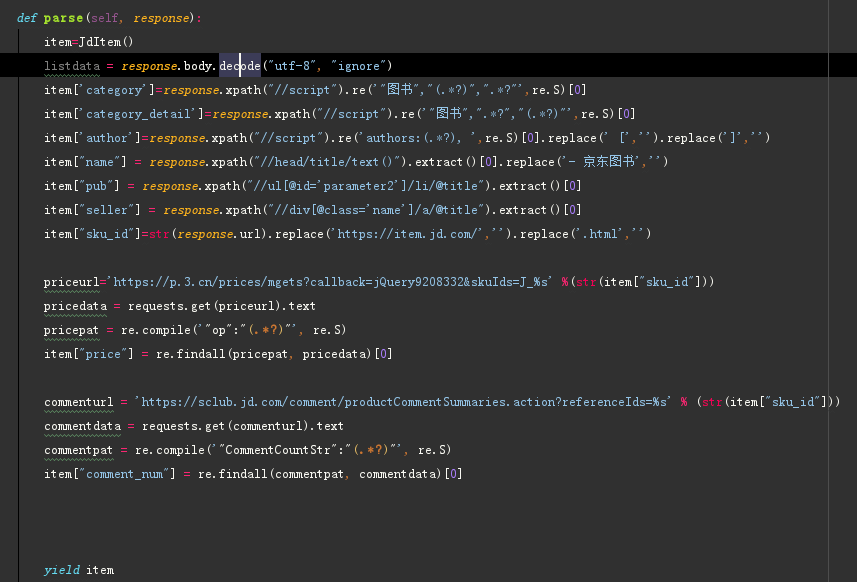
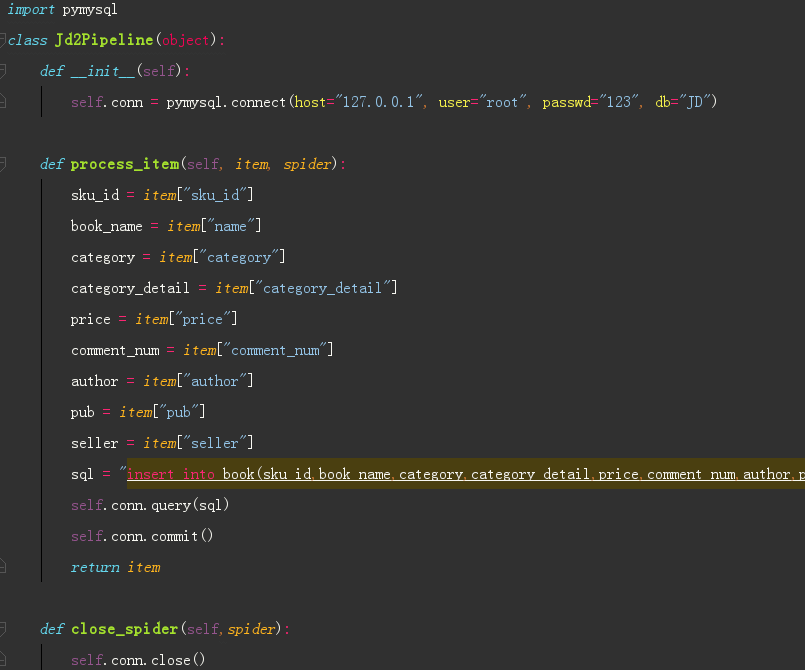
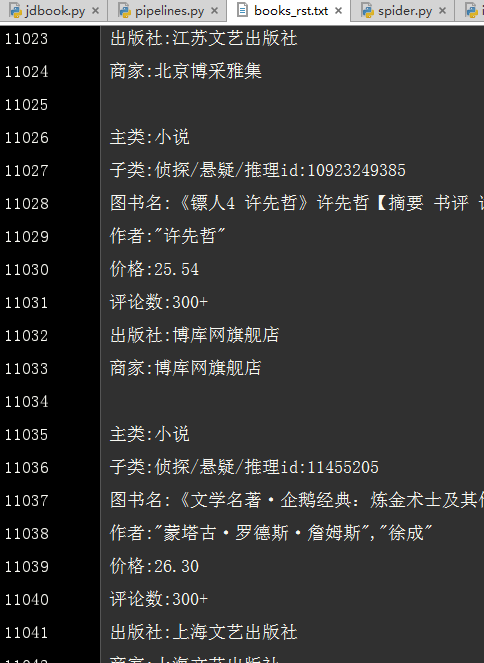
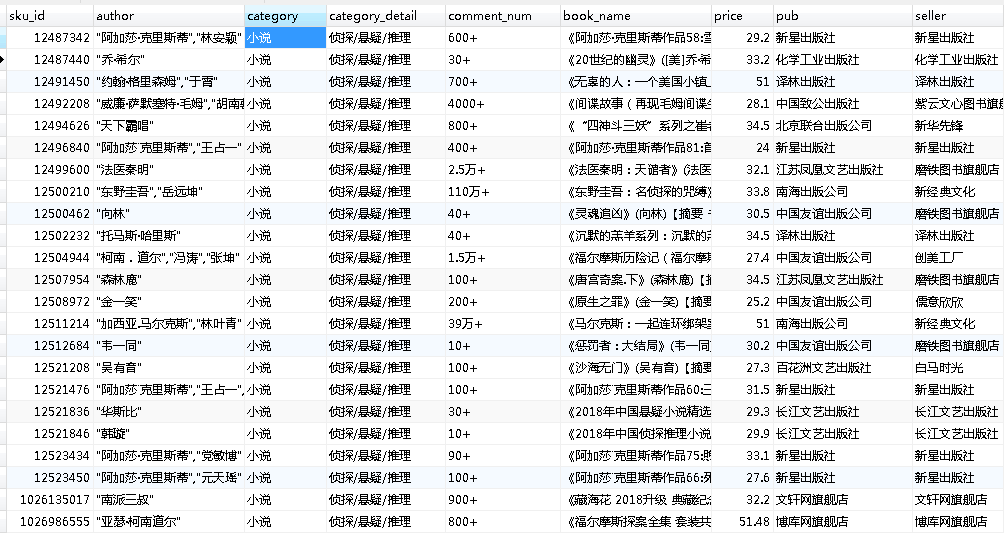
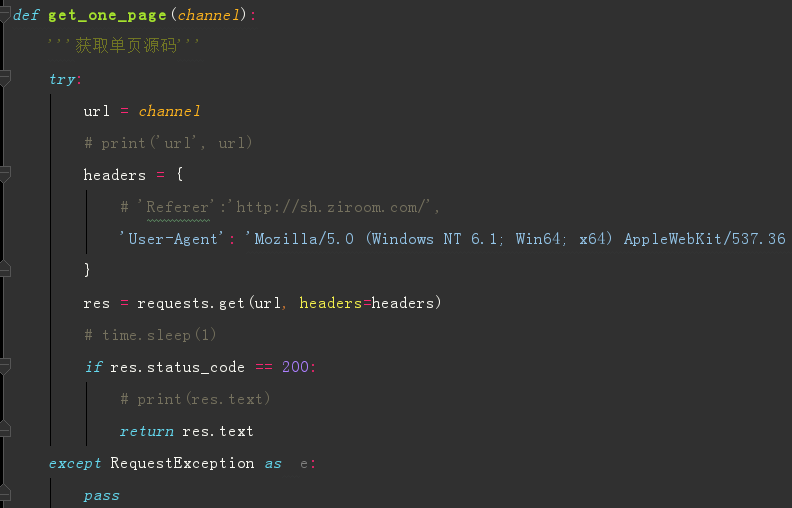
Python 爬虫 JD商品-scrapy+requests 目标站点需求分析 JD商品信息抓取 需求信息字段 涉及的库 scrapy, requests,re lxml 获取单页源码 解析单页源码 获取总页数 获取商品url 解析商品信息 保存本地文件 保存mysql数据库 结果