1.简介
按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath。xpath 的定位方法, 非常强大。 使用这种方法几乎可以定位到页面上的任意元素。
2.什么是xpath?
xpath 是XML Path的简称, 由于HTML文档本身就是一个标准的XML页面,所以我们可以使用Xpath 的用法来定位页面元素。
XPath 是XML 和Path的缩写,主要用于xml文档中选择文档中节点。基于XML树状文档结构,XPath语言可以用在整棵树中寻找指定的节点。XPath 定位和CSS定位相比有更大的灵活性。XPath 在文档树中某个节点既可以向前搜索,也可以向后搜索,CSS定位只能在文档树中向前搜索,但XPath的定位速度比CSS 慢一些。
3.xpath定位的缺点
xpath 这种定位方式, webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素, 这是个非常费时的操作, 如果脚本中大量使用xpath做元素定位的话, 脚本的执行速度可能会稍慢。
4.常用定位方法(8种)
(1)id
(2)name
(3)class name
(4)tag name
(5)link text
(6)partial link text
(7)xpath(今天讲解)
(8)css selector
5.自动测试实战
以百度首页为例,将xpath的各种定位方法一一讲解和分享一下。
5.1大致步骤
1.访问度娘首页。
2.通过xpath定位到元素,点击一下。
5.2模糊定位starts-with关键字
有一种特殊的情况:页面元素的属性值会被动态地生成,即每次看到的页面元素属性值是不一样的,这种页面元素会加大定位的难度,使用模糊属性值定位方法可以部分解决问题。
XPath常用的函数如下:
Starts-with()
定位表达式的实例://img[starts-with(@alt,'div1')]
这个实例表示查找图片alt属性开始位置包含‘div1’关键字的页面元素。
start-with定位,以‘//’开头,具体格式为
xxx.By.xpath("//标签[starts-with(@属性,'内容')]")
具体例子:
//input[starts-with(@name,'name1')] 查找name属性中开始位置包含'name1'关键字的页面元素
具体步骤:
在被测试百度网页中, 按照宏哥在上卷中5.2中的方法 (1)查找输入框并输入“北京宏哥”,(2)查找“百度一下”按钮,(3)点击“百度一下”按钮。
XPath表达式:
(1)//input[starts-with(@name,'wd')]
(2)//input[starts-with(@value,'百度一下')]
java定位语句:
(1)WebElement searchBox = driver.findElement(By.xpath( "//input[starts-with(@name,'wd')]" ));
(2)WebElement SearchButton = driver.findElement(By.xpath("//input[starts-with(@value,'百度一下')]"));
5.2.1代码设计

5.2.2参考代码
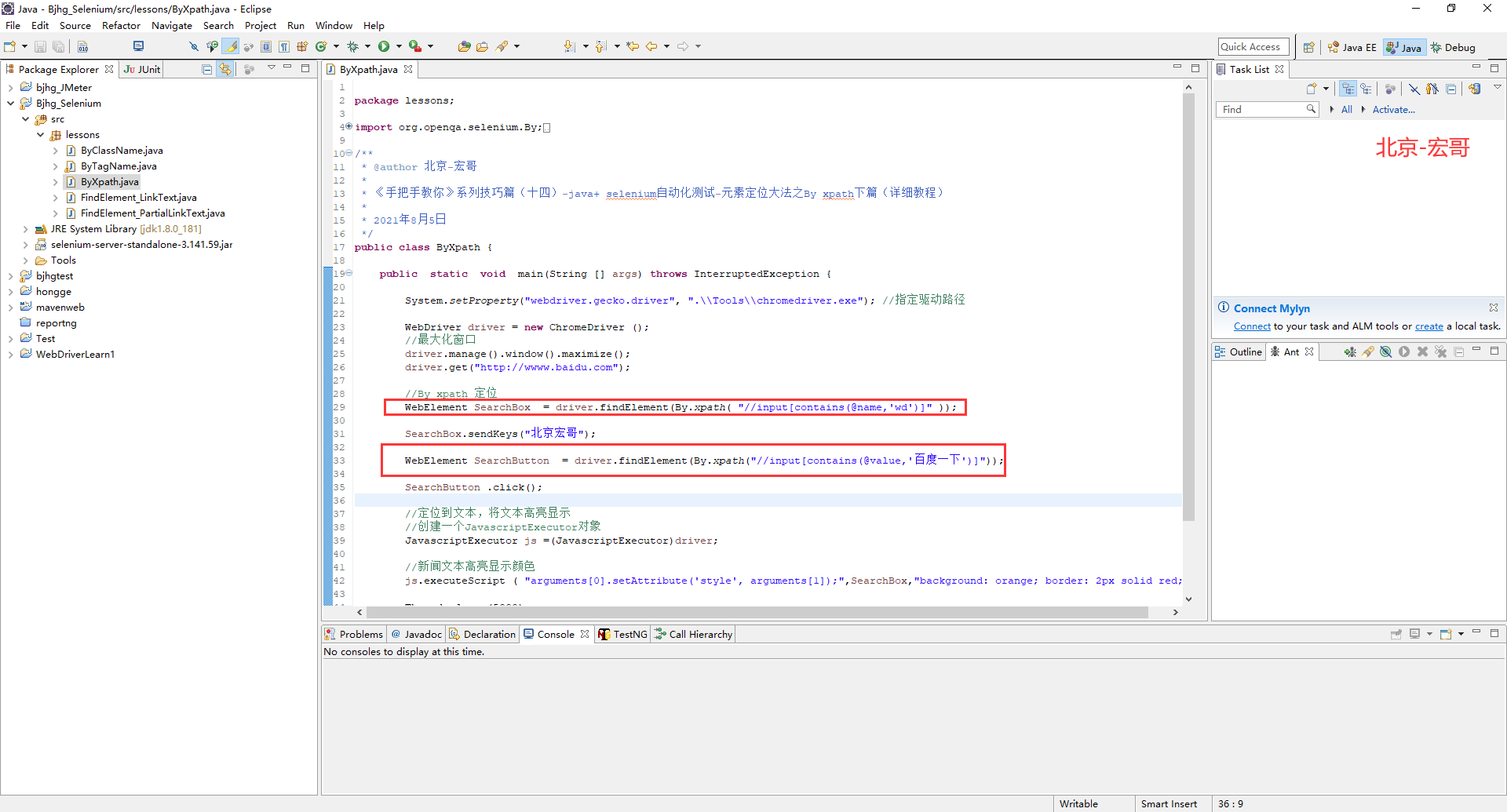
package lessons; import org.openqa.selenium.By; import org.openqa.selenium.JavascriptExecutor; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; /** * @author 北京-宏哥 * * 《手把手教你》系列技巧篇(十四)-java+ selenium自动化测试-元素定位大法之By xpath下篇(详细教程) * * 2021年8月5日 */ public class ByXpath { public static void main(String [] args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", ".\Tools\chromedriver.exe"); //指定驱动路径 WebDriver driver = new ChromeDriver (); //最大化窗口 driver.manage().window().maximize(); driver.get("http://wwww.baidu.com"); //By xpath 定位 WebElement SearchBox = driver.findElement(By.xpath( "//input[starts-with(@name,'wd')]" )); SearchBox.sendKeys("北京宏哥"); WebElement SearchButton = driver.findElement(By.xpath("//input[starts-with(@value,'百度一下')]")); SearchButton .click(); //定位到文本,将文本高亮显示 //创建一个JavascriptExecutor对象 JavascriptExecutor js =(JavascriptExecutor)driver; //新闻文本高亮显示颜色 js.executeScript ( "arguments[0].setAttribute('style', arguments[1]);",SearchBox,"background: orange; border: 2px solid red;"); Thread.sleep (5000); driver.quit(); } }
5.2.3运行代码
1.运行代码,右键Run AS->java Application,控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作,如下小视频所示:
5.3模糊定位contains关键字
Contains()
定位表达式的实例://img[contains(@alt,'g1')]
这个实例表示查找图片alt属性包含‘g1’关键字的页面元素。Contains()函数属于XPath函数的高级用法,使用的场景比较多,页面元素的属性值只要具有固定不变的几个关键字,就可以在元素属性经常发生一定程度的变化的时候,依然可以使用Contains函数进行定位。
索引号定位,以‘//’开头,具体格式为:
xxx.By.xpath("//标签[contains(@属性,'内容')]")
具体例子:
//input[contains(@name,'na')] 查找name属性中包含na关键字的页面元素
具体步骤:
在被测试百度网页中, 按照宏哥在上卷中5.2中的方法 (1)查找输入框并输入“北京宏哥”,(2)查找“百度一下”按钮,(3)点击“百度一下”按钮。
XPath表达式:
(1)//input[contains(@name,'wd')]
(2)//input[contains(@value,'百度一下')]
java定位语句:
(1)WebElement searchBox = driver.findElement(By.xpath( "//input[contains(@name,'wd')]" ));
(2)WebElement SearchButton = driver.findElement(By.xpath("//input[contains(@value,'百度一下')]"));
5.3.1代码设计
5.3.2参考代码
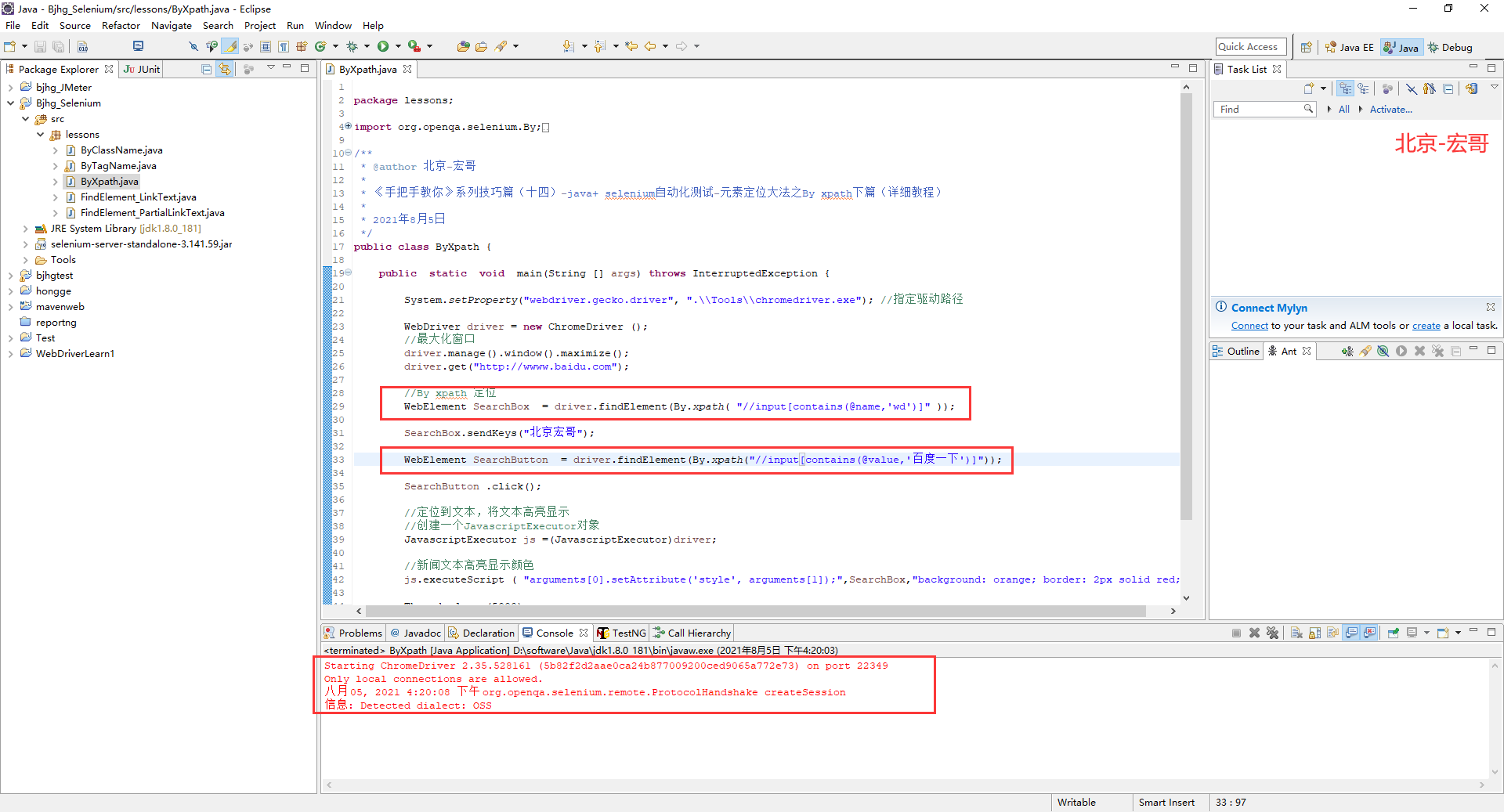
package lessons; import org.openqa.selenium.By; import org.openqa.selenium.JavascriptExecutor; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; /** * @author 北京-宏哥 * * 《手把手教你》系列技巧篇(十四)-java+ selenium自动化测试-元素定位大法之By xpath下篇(详细教程) * * 2021年8月5日 */ public class ByXpath { public static void main(String [] args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", ".\Tools\chromedriver.exe"); //指定驱动路径 WebDriver driver = new ChromeDriver (); //最大化窗口 driver.manage().window().maximize(); driver.get("http://wwww.baidu.com"); //By xpath 定位 WebElement SearchBox = driver.findElement(By.xpath( "//input[contains(@name,'wd')]" )); SearchBox.sendKeys("北京宏哥"); WebElement SearchButton = driver.findElement(By.xpath("//input[contains(@value,'百度一下')]")); SearchButton .click(); //定位到文本,将文本高亮显示 //创建一个JavascriptExecutor对象 JavascriptExecutor js =(JavascriptExecutor)driver; //新闻文本高亮显示颜色 js.executeScript ( "arguments[0].setAttribute('style', arguments[1]);",SearchBox,"background: orange; border: 2px solid red;"); Thread.sleep (5000); driver.quit(); } }
5.3.3运行代码
1.运行代码,右键Run AS->java Application,控制台输出,如下图所示:
2.运行代码后电脑端的浏览器的动作,如下小视频所示:
5.4text() 函数 文本定位
使用text()函数可以定位到包含某些关键字的页面元素。
文本内容的定位是利用 html 的 text 字段进行定位的方法,可以看做是属性值定位的衍生
//button[text()='下一步']
由于 “下一步” 这几个字是浏览器界面就可以看到的,我们称为 “所见即所得”,这种特征改的可能性非常小,所以非常未定,优先推荐使用。
与属性值类似,文本内容也支持 starts-with 和 contains 模糊匹配。
text()函数文本定位,以‘//’开头,具体格式为:
xxx.By.xpath("//标签[text()='文本']")
或者
xxx.By.xpath("//标签[contains(text(),'文本')]")
具体例子:
driver.findElement(By.xpath("//*[text()='百度搜索']"));
driver.findElement(By.xpath("//a[contains(text(),'搜索')]"));
具体步骤:
在被测试百度网页中, 按照宏哥在上卷中5.2中的方法 (1)查找“百度热搜”,(2)点击“百度热搜”按钮。
XPath表达式:
(1)//a/div[text()='百度热搜']
//或者
(2)//a/div[contains(text(),'百度热搜')]
java定位语句:
(1)WebElement searchBox = driver.findElement(By.xpath( "//a/div[text()='百度热搜']" ));
//或者
(2)WebElement SearchButton = driver.findElement(By.xpath("//a/div[contains(text(),'百度热搜')]"));
第一个表达式是查找包含“百度搜索”的链接页面元素,要精确匹配。第二个表达式则是搜索包含“百度”两个字的链接页面元素,实现了根据关键字内容匹配。
使用文字匹配模式进行定位,为定位复杂的页面元素提供过一种强大的定位模式,遇到定位问题的时候,可以优先考虑使用这个方法。
5.4.1代码设计

5.4.2参考代码
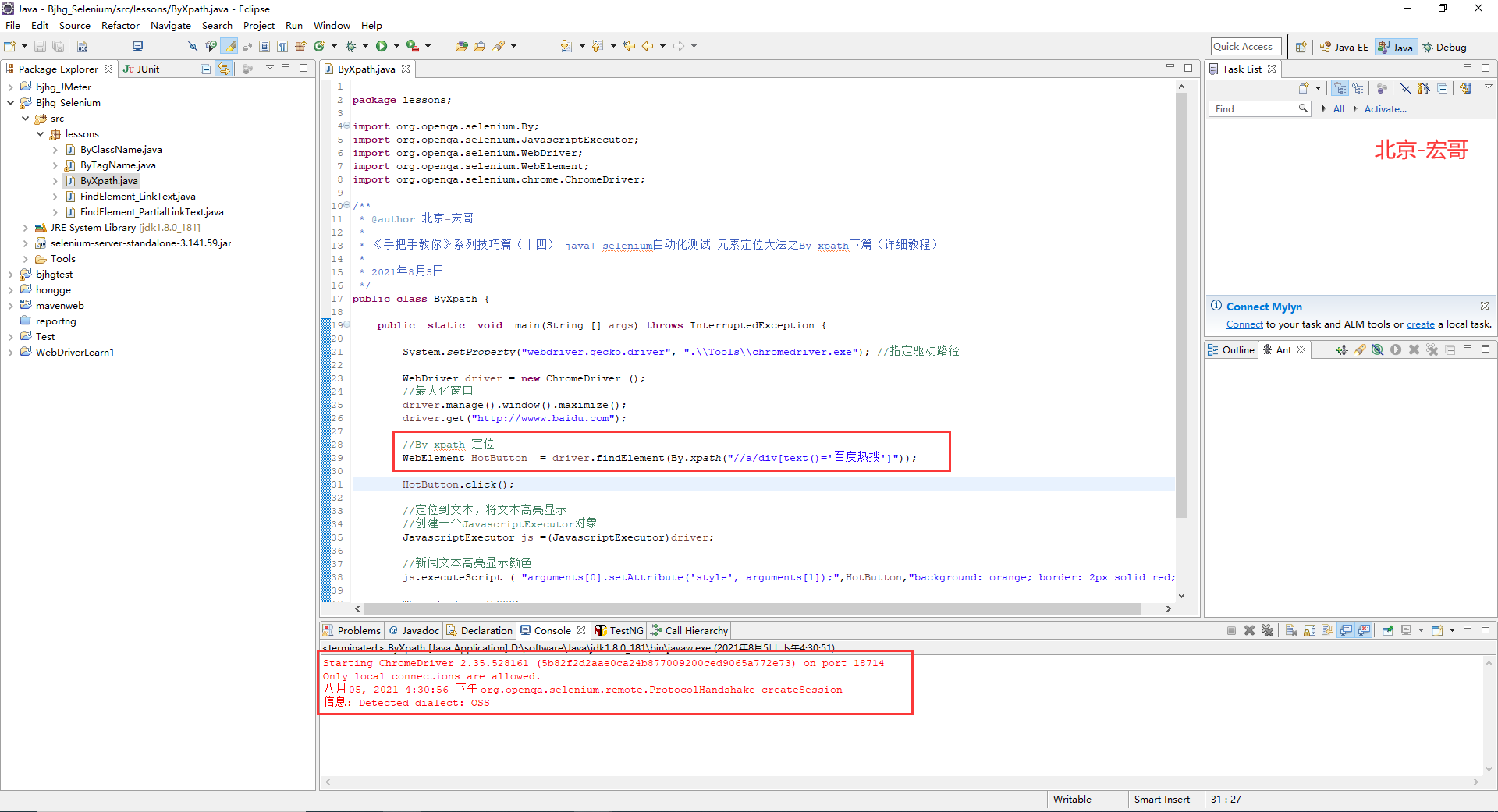
package lessons; import org.openqa.selenium.By; import org.openqa.selenium.JavascriptExecutor; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; /** * @author 北京-宏哥 * * 《手把手教你》系列技巧篇(十四)-java+ selenium自动化测试-元素定位大法之By xpath下篇(详细教程) * * 2021年8月5日 */ public class ByXpath { public static void main(String [] args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", ".\Tools\chromedriver.exe"); //指定驱动路径 WebDriver driver = new ChromeDriver (); //最大化窗口 driver.manage().window().maximize(); driver.get("http://wwww.baidu.com"); //By xpath 定位 WebElement HotButton = driver.findElement(By.xpath("//a/div[text()='百度热搜']")); HotButton.click(); //定位到文本,将文本高亮显示 //创建一个JavascriptExecutor对象 JavascriptExecutor js =(JavascriptExecutor)driver; //新闻文本高亮显示颜色 js.executeScript ( "arguments[0].setAttribute('style', arguments[1]);",HotButton,"background: orange; border: 2px solid red;"); Thread.sleep (5000); driver.quit(); } }
5.4.3运行代码
1.运行代码,右键Run AS->java Application,控制台输出,如下图所示:
2.运行代码后电脑端的浏览器的动作,如下小视频所示:
6.小结
Xpath的功能非常强大,不仅能够完成界面定位的任务,而且能保证稳定性,实际自动化测试中,能够识别界面元素是重要的,更重要的是要保证版本间的稳定性,减少脚本的维护工作。
如下规则请参考:
(1)特征越少越好
(2)特征越是界面可见的越好
(3)不能使用绝对路径
(4)避免使用索引号
(5)擅用 console 调试(后边宏哥会简单讲解一下)
(6)相对路径,属性值,文本内容,Axis 可以任意组合,当然属性值和文本内容的模糊匹配也支持和上述方式任意组合,Axis 可以嵌套使用。
通过 Xpath 的各种方式组合,能够解决 selenium 自动化测试中界面定位的全部问题,可以说:有了 Xpath,再也不用担心元素定位了。
好了,今天到这里关于xpath定位的常见方法基本上都介绍和分享讲解过了。下一篇宏哥讲解最后一种元素定位方法。
7.拓展
7.1. 函数
1.count:统计
'count(//li[@data])' #节点统计
2.concat:字符串连接
'concat(//li[@data="one"]/text(),//li[@data="three"]/text())'
3.local-name:解析节点名称
'local-name(//*[@id="testid"])' #local-name解析节点名称,标签名称
4.contains(string1,string2):如果 string1 包含 string2,则返回 true,否则返回 false
'//h3[contains(text(),"H3")]/a/text()')[0] #使用字符内容来辅助定位
5.not:布尔值(否)
'count(//li[not(@data)])' #不包含data属性的li标签统计
6.string-length:返回指定字符串的长度
#string-length函数+local-name函数定位节点名长度小于2的元素
'//*[string-length(local-name())<2]/text()')[0]
7.组合拳2
#contains函数+local-name函数定位节点名包含di的元素
'//div[@id="testid"]/following::div[contains(local-name(),"di")]'
8.or:多条件匹配
'//li[@data="one" or @code="84"]/text()' #or匹配多个条件
#也可使用|
'//li[@data="one"]/text() | //li[@code="84"]/text()' #|匹配多个条件
9.组合拳3:floor + div除法 + ceiling
#position定位+last+div除法,选取中间两个
'//div[@id="go"]/ul/li[position()=floor(last() div 2+0.5) or position()=ceiling(last() div 2+0.5)]/text()'
10.组合拳4隔行定位:position+mod取余
#position+取余运算隔行定位
'//div[@id="go"]/ul/li[position()=((position() mod 2)=0)]/text()')
7. 2数值比较
1.<:小于 、 >:大于
#所有li的code属性小于200的节点
'//li[@code<200]/text()'
2.div:对某两个节点的属性值做除法
'//div[@id="testid"]/ul/li[3]/@code div //div[@id="testid"]/ul/li[1]/@code'
3.组合拳4:根据节点下的某一节点数量定位
#选取所有ul下li节点数大于5的ul节点
'//ul[count(li)>5]/li/text()'

