一
isdigit()
True: Unicode数字,byte数字(单字节),全角数字(双字节),罗马数字
False: 汉字数字
Error: 无
isdecimal()
True: Unicode数字,,全角数字(双字节)
False: 罗马数字,汉字数字
Error: byte数字(单字节)
isnumeric()
True: Unicode数字,全角数字(双字节),罗马数字,汉字数字
False: 无
Error: byte数字(单字节)

二、and、or
python 中的and从左到右计算表达式,若所有值均为真,则返回最后一个值,若存在假,返回第一个假值。
or也是从左到右计算表达式,返回第一个为真的值。
三、优先级
幂运算>正负号>算术操作符>比较操作符>逻辑运算符
-3**2=-9 3**-2=0.1111111111 幂运算的优先级:与单目操作符(一般为负号)结合时,比右侧的优先级低,比左侧的优先级高。
四、递归深度

五、汉诺塔

六、哈希/字典/映射/散列

dict为内置函数,使用时必须用括号将内容括起来,这是最外面的一层括号;由于dict函数内只支持一个参数,所以将f I s h c 这些元素都用括号包起来模拟成一个参数,实际上这些元素都是分开的,这层括号是中间层的,内层的括号只是用来将每个元素隔开。

dict.setdefault()在使用时如果键为引号引起的数字,则在显示中没有引号,如果为字母或符号,则会有引号标注。如果括号内的键字典中已存在,则会显示出该键所对应的值。
七、集合

八、内嵌函数和闭包
global

nonlocal

九、Os



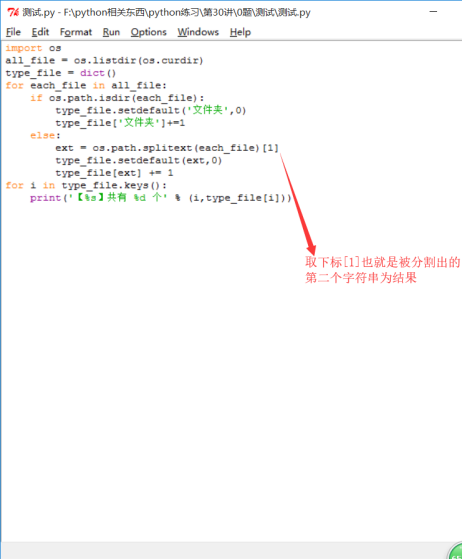
os.walk(top)遍历top目录下所有子目录并返回一个三元组('路径',[路径包含目录],[路径包含文件])
>>> test = os.walk(r'D:Python34 est')
>>> test
<generator object walk at 0x02365DA0>
>>> temp = list(test)
>>> for each in temp:
each
('D:\Python34\test', ['002', '0035', 'test下的第二个文件'], ['intorfloat - 副本 - 副本.py', 'intorfloat-1.py', 'intorfloat.py', 'log_in-box.py', 'log_in重命名.py'])
('D:\Python34\test\002', [], ['guess.py', '流程图.png', '流程图.vsd'])
('D:\Python34\test\0035', [], ['case01.py'])
('D:\Python34\test\test下的第二个文件', ['下一级文件夹'], [])
('D:\Python34\test\test下的第二个文件\下一级文件夹', [], [])
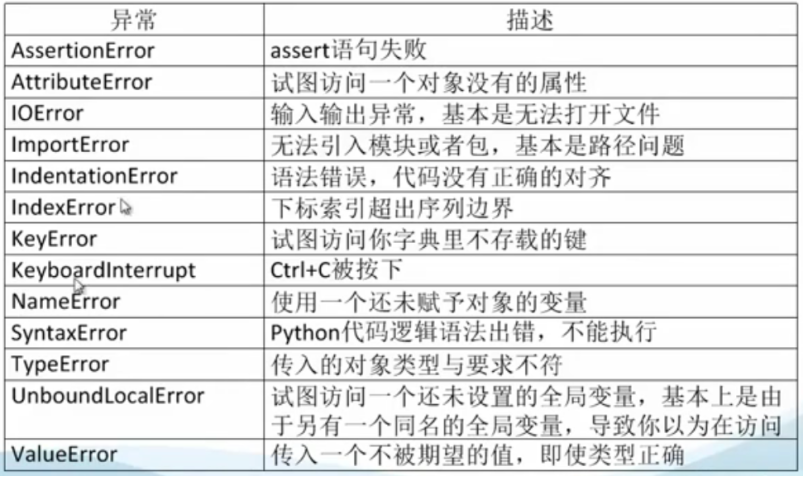
十、异常
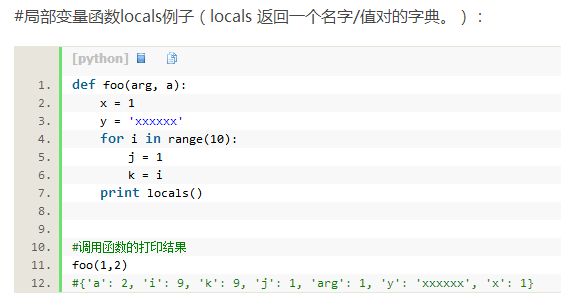
十一、locals 和globals
Python两个内置函数——locals 和globals
这两个函数主要提供,基于字典的访问局部和全局变量的方式。
在理解这两个函数时,首先来理解一下python中的名字空间概念。Python使用叫做名字空间的
东西来记录变量的轨迹。名字空间只是一个字典,它的键字就是变量名,字典的值就是那些变
量的值。实际上,名字空间可以象Python的字典一样进行访问
每个函数都有着自已的名字空间,叫做局部名字空间,它记录了函数的变量,包括函数的参数
和局部定义的变量。每个模块拥有它自已的名字空间,叫做全局名字空间,它记录了模块的变
量,包括函数、类、其它导入的模块、模块级的变量和常量。还有就是内置名字空间,任何模
块均可访问它,它存放着内置的函数和异常。
当一行代码要使用变量 x 的值时,Python会到所有可用的名字空间去查找变量,按照如下顺序:
1.局部名字空间 - 特指当前函数或类的方法。如果函数定义了一个局部变量 x,Python将使用
这个变量,然后停止搜索。
2.全局名字空间 - 特指当前的模块。如果模块定义了一个名为 x 的变量,函数或类,Python
将使用这个变量然后停止搜索。
3.内置名字空间 - 对每个模块都是全局的。作为最后的尝试,Python将假设 x 是内置函数或变量。
如果Python在这些名字空间找不到 x,它将放弃查找并引发一个 NameError 的异常,同时传递
There is no variable named 'x' 这样一条信息。
十二、运算符
防止又忘记了


十三
用dir(classname)查看类中有哪些东西
用dir(instance)查看实例中有哪些东西
用__dict__查看有哪些属性
用id()查看哪些属性一样
我通过一系列测试得出结论:
类中的所有东西都“复制”实例中了包括类函数,静态函数,类变量,其实能通过实例调用相同名字的类变量
instance__class__.value
另外self是用来进行绑定用的,这点可以通过直接打印函数名能够看到哪个类的对象被绑定
另外还有继承,也可以用上述方法研究看看这些父类子类中到底有哪些东西:其实父类中所有的东西也都复制到子类中了,正是有了显示绑定才能方便的用子类实例调用父类的方法:应为子类实例绑定了父类函数
说到底,都是python的设计哲学比较好,能够用一些方法清楚的看到所有的东西,比起java来说迷迷糊糊的只能看资料了解哪些类中有什么东西,继承时,创建实例时发生了什么改变。
十四、Python类中的一些内置函数用法
1.issubclass(class,classinfo)判断一个类是否是另一个类或类组成的元组的其中一个类的子类的方法
>>> class A:
pass
>>> class B(A):
pass
>>> issubclass(B,A)
True
>>> issubclass(B,object)
True
>>> issubclass(B,B)
True
2.isinstance(object,class)判断是否是一类的实例化对象
>>> class A:
pass
>>> class B(A):
pass
>>> a = A()
>>> b = B()
>>> isinstance(a,A)
True
>>> isinstance(a,B)
False
>>> isinstance(b,B)
True
>>> isinstance(b,A)
True
3.hasattr(object,name)测试一个对象是否有指定的属性

4.getattr(object,name[,default])返回一个对象内某个成员的值
>>> class C:
def __init__(self,size):
self.size = size
>>> c1 = C(3)
>>> getattr(c1,'size')
3
>>> getattr(s1,'size','属性不存在!')
'属性不存在!'
5.setattr(object,name,value)设置一个对象内某个变量的值
>>> class C:
def __init__(self,size):
self.size = size
>>> c1 = C(3)
>>> setattr(c1,'size',5)
>>> getattr(c1,'size')
5
6.delattr(object,name)删除一个对象的某个变量
>>> class C:
def __init__(self,size):
self.size = size
>>> c1 = C(3)
>>> delattr(c1,'size')
>>> getattr(c1,'size','对象%s内不存在%s变量'%('c1','size'))
'对象c1内不存在size变量
7.property(fget=None,fset=None,fdel=None,doc=None) 用属性设置属性,第一个参数为获取对象属性的方法名,第二个参数为设置对象属性的方法名,第三个参数为删除对象属性的方法名,可以将其赋值给一个对象属性,那么当其被对一个对象调用时则调用对象内定义的获取对象属性方法,当对其进行赋值时则调用设置对象属性的方法,当用del语句删除时则调用删除对象属性的方法,举例说明:
>>> class Case:
def __init__(self,size):
self.size = size
def getSize(self):
print('正在调用获得对象属性的方法!')
return self.size
def setSize(self,value):
print('正在调用设置对象属性的方法!')
self.size = value
def delSize(self):
print('正在调用删除对象属性的方法!')
del self.size
x = property(getSize,setSize,delSize)
>>> s1 = Case(3)
>>> s1.x
正在调用获得对象属性的方法!
3
>>> s1.x = 5
正在调用设置对象属性的方法!
>>> s1.x
正在调用获得对象属性的方法!
5
>>> del s1.x
正在调用删除对象属性的方法!
>>> getattr(s1,'size','属性不存在!')
' 属性不存在!'
十五、修饰符(装饰器)

|
终于算明白了这个修饰符的基础概念。 附:https://www.cnblogs.com/rollenholt/archive/2012/05/02/2479833.html |
十六、全局变量和局部变量
参考文献:https://www.cnblogs.com/z360519549/p/5172020.html
十七、__getattr()__()和__getattribute__()

十八、

改:
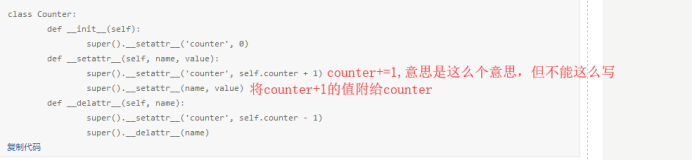
相关解释:

如果是square,第一次调用self.width = value会引发一次递归,然后进入后执行else的super().__setattr__(name,value),才成功将value送到self.width。
十九、编码
什么是编码?
事实上计算机只认识 0 和 1,然而我们却可以通过计算机来显示文本,这就是靠编码实现的。编码其实就是约定的一个协议,比如 ASCII 编码约定了大写字母 A 对应十进制数 65,那么在读取一个字符串的时候,看到 65,计算机就知道这是大写字母 A 的意思。
由于计算机是美国人发明的,所以这个 ASCII 编码设计时只采用 1 个字节存储(事实上只用了 7 位,1 个字节有 8 位),包含了大小写英文字母、数字和一些符号。但是计算机在全世界普及之后,ASCII 编码就成了一个瓶颈,因为 1 个字节是完全不足以容纳各国语言的。
大家都知道英文只用 26 个字母就可以组成不同的单词,而汉字光常用字就有好几千个,至少需要 2 个字节才足以存放,所以后来中国制订了 GB2312 编码,用于对汉字进行编码。
然后日本为自己的文字制订了 Shift_JIS 编码,韩国为自己的文字制订了 Euc-kr 编码,一时之间,各国都制订了自己的标准。不难想象,不同的标准放在一起,就难免出现冲突。这也正是为什么最初的计算机总是容易看到乱码的现象。
为了解决这个问题,Unicode 编码应运而生。Unicode 组织的想法最初也很简单:创建一个足够大的编码,将所有国家的编码都加进来,进行统一标准。
没错,这样问题就解决了。但新的问题也出现了:如果你写的文本只包含英文和数字,那么用 Unicode 编码就显得特别浪费存储空间(用 ASCII 编码只占用一半的存储空间)。所以本着能省一点是一点的精神,Unicode 还创造出了多种实现方式。
比如常用的 UTF-8 编码就是 Unicode 的一种实现方式,它是可变长编码。简单地说,就是当你的文本是 ASCII 编码的字符时,它用 1 个字节存放;而当你的文本是其它 Unicode 字符的情况,它将按一定算法转换,每个字符使用 1~3 个字节存放。这样便实现了有效节省空间的目的。
二十、爬虫
1.

2.(推荐)由于 GBK 是向下兼容 GB2312,因此你检测到是 GB2312,则直接用 GBK 来编码/解码
>>> if chardet.detect(response)['encoding'] == 'GB2312':
response.decode('GBK')
……
<ul><li># <a href="thread-64400-1-1.html" title="乔布斯最精彩演讲:这三个故事决定了我的一生" target="_blank">乔布斯最精彩演讲:这三个故事决定了我的一</a></li><li># <a href="thread-50608-1-1.html" title="42个锻炼大脑的方法,你想不聪明都不行!" target="_blank">42个锻炼大脑的方法,你想不聪明都不行!</a></li><li># <a href="thread-23917-1-1.html" title="屌丝看完,泪流满面(转)" target="_blank">屌丝看完,泪流满面(转)
3. GET:是指向服务器请求获得数据
POST:是指向指定服务器提交被处理的数据
4.


5. urllib.parse.urlencode()encode(‘utf-8’):把一个date(字典形式)编码成url形式,然后硬编码成utf-8形式
6. 修改heads:①Request生成之前:把User-Agent以字典的形式赋值给head,通过urllib.request.Request(url,date,head)传入。
②Request生成之后:req=urllib.request.Request(url,date)
req.add_header(‘User-Agent’,’User-Agent对应的值’)
这样传入
7. 代理ip:


8.

9.反向引用(链接https://www.cnblogs.com/-ShiL/archive/2012/04/06/Star201204061009.html)
捕获组匹配到什么,反向引用也只能匹配到什么。
10.前向肯定断言、前向否定断言、后向肯定断言、后向否定断言
解释:

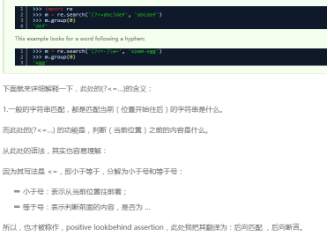
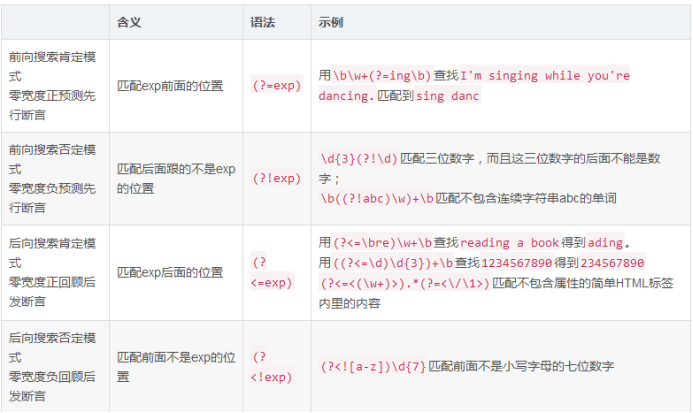
链接:https://blog.csdn.net/lilongsy/article/details/78505309
11.urllib.request.Request()是什么意思?
urllib.request.Request()不是一个函数,而是一个类,类具有自带的多种属性和多种可供操作的方法。以URL为参数将类实例化后,不需要自定义方法和属性,可直接使用类中的方法和属性,方便对URL进行操作
#可以将url先构造成一个Request对象,传进urlopen #Request存在的意义是便于在请求的时候传入一些信息,而urlopen则不
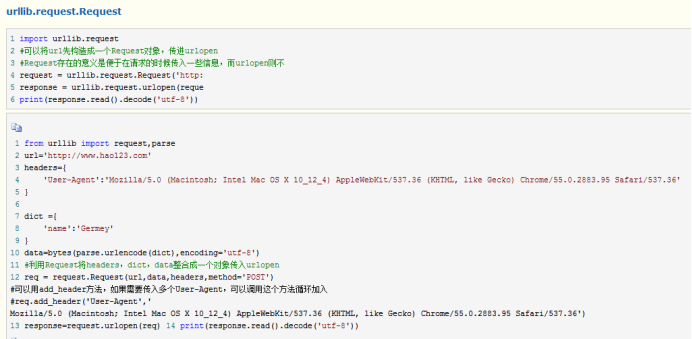
12.由于urlopen()对于一些HTTP的高级功能不支持,所以,如果我们要修改报头,则可以使用urllib.request.build_opener()方法。当然,也可以使用urllib.request.Request()实现浏览器的模拟。重点在前者,后者在后面的学习中才会用到。