一、 什么是人体姿态估计?
人体姿态估计(Human Pose Estimation)是计算机视觉领域中的一个重要研究方向,被广泛应用于人体活动分析、人机交互以及视频监视等方面。人体姿态估计是指通过计算机算法在图像或视频中定位人体关键点(如肩、肘、腕、髋膝、膝、踝等)。本文主要介绍近几年深度学习兴起后的人体姿态估计方法发展历程。

二、人体姿态估计有什么用?
(1)利用人体姿态进行摔倒检测或用于增强安保和监控;
(2)用于健身、体育和舞蹈等教学;
(3)训练机器人,让机器人“学会”移动自己的关节;
(4)电影特效制作或交互游戏中追踪人体的运动。通过追踪人体姿态的变化,实现虚拟人物与现实人物动作的融合与同步。
三、人体姿态估计算法评估指标
(1)OKS(Object Keypoint Similarity)
OKS是COCO姿态估计挑战赛提出的评估指标,COCO Leaderboard 显示Challenge18最高mAP最高为0.764。基于对象关键点相似度的mAP:
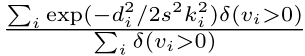
其中,di表示预测的关键点与ground truth之间的欧式距离;vi是ground truth的可见性标志;s是目标尺度,等于该人在ground truth中的面积的平方根;ki控制衰减的每个关键点常量。
(2)PCK(Probability of Correct Keypoint)
MPII数据集的评估指标采用的是PCKh@0.5,目前MPII数据集PCKh最高为92.5。预测的关节点与其对应的真实关节点之间的归一化距离小于设定阈值,则认为关节点被正确预测,PCK即通过这种方法正确预测的关节点比例。
PCK@0.2表示以躯干直径作为参考,如果归一化后的距离大于阈值0.2,则认为预测正确。
PCKh@0.5表示以头部长度作为参考,如果归一化后的距离大于阈值0.5,则认为预测正确。
(3)PCP(Percentage of Correct Parts)
如果两个关节点的位置和真实肢体关键的距离达到至多一半时的真实肢体长度,则认为关节点被正确预测,PCP即通过这种方法正确预测的关节点比例。
四、人体姿态估计算法发展历程
2013年,Toshev等人将DeepPose引入人体姿态估计领域,人体姿态估计的研究开始从传统方法转向深度学习,下面将按时间顺序总结6篇个人认为具有标志性的工作。
(1)DeepPose(2014,Google)
Alexander Toshev和Christian Szegedy提出的DeepPose最早将CNN(卷积神经网络)应用于人体关节点检测。DeepPose将人体姿态估计转换为关节点回归问题,并提出了将CNN应用于人体关节点回归的方法:使用整幅图像输入到7层CNN来做关节点回归,更进一步,使用级联的CNN检测器来增加关节点定位的精确度。

DeepPose在LSP数据集上的PCP@0.5平均精度达到61%,是当时的state-of-art方法。
(2)Convolutional Pose Machines(2016,卡内基梅隆大学)
Convolutional Pose Machines(CPM)的主要贡献在于:
a) 用Heatmap来表示关节点的位置及位置约束关系,并且将Heatmap和Feature Map同时作为数据在网络中传递,同时在多个尺度处理输入的特征,充分考虑各个关节点之间的空间位置关系。
b) 多个阶段(Stage)有监督训练,避免过深网络难以优化的问题。
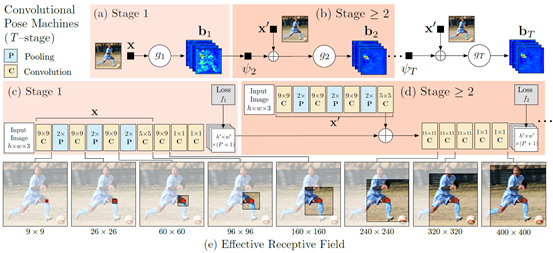
OpenPose是GitHub上最受欢迎的人体姿态估计项目(14.8K Stars, 4.2K Folks),其人体关键点检测正是主要基于Convolutional Pose Machines。
(3)Stacked Hourglass Networks(2016,密西根大学)
Stacked Hourglass Networks(简称Hourglass)堆叠bottom-up、top-down过程。bottom-up过程通过卷积和池化将图片从高分辨率降到低分辨率,top-down过程通过upsampling将图片从低分辨率升到高分辨率,该过程结合多个分辨率的特征,使网络能够捕获并整合图像所有尺度的信息。
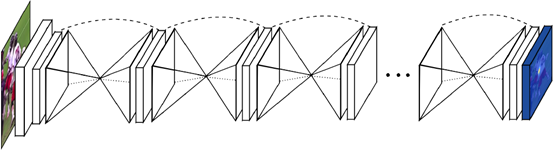
Hourglass在MPII数据集上的PCPh@0.5平均精度达到90.9%,是当时的state-of-art方法。
(4)Cascaded Pyramid Network(2018,Face++)
Cascaded Pyramid Network(简称CPN)采用Top-down自上而下的检测策略,即首先检出人体框,然后在人体框检测人体关节点。网络级联GolbalNet和RefineNet两个模块,并使用了类似于FPN的金字塔网络结构。GolbalNet负责所有关键点的检测,对眼睛,胳膊等部位的关键点预测效果较好,但对遮挡、看不见、复杂背景的关键点预测误差较大,RefineNet则是对误差较大预测的结果进行修正,提升整体预测性能。
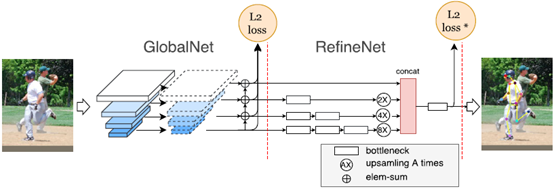
CPN在COCO数据集上取得2017 Keypoint Benchmark冠军。
(5)Simple Baselines (2018,微软亚洲研究院)
Simple Baselines for Human Pose Estimation and Tracking(简称Simple Baselines),该工作试图回答“既然好的模型都比较复杂,那么一个简单模型的效果怎样?”这个问题。Simple Baselines网络结构非常简单,仅由一个ResNet作为Backbone提取特征,加上3个反卷积层提升Feature Map分辨率,再接一个1X1的卷积层直接得到具有关节点位置信息的Heatmap。

该方法在COCO数据集上mAP达到了73.7%。
(6)High-Resolution Network(2019, 微软亚洲研究院)
Deep High-Resolution Representation Learning for Human Pose Estimation(简称HRNet)是Simple Baselines的后续工作。Simple Baselines的分析表明输入尺寸大小、各层次分辨率特征图是否参与、网络特征提取能力强弱是影响人体姿态估计效果的关键因素。HRNet通过跨越多分辨率并行子网络的信息交换来实现多尺度融合,高分辨率表示在整个过程中都得到保持,并逐步将高分辨率特征加入到低分辨率的子网,连接并行的多分辨率子网以形成更多的阶段。

HRNet模型在COCO test-dev数据集上OKS mAP达到77%,在MPII测试数据上PCKh@0.5达到了92.3%。最近HRNetV2表明HRNet应用于分类、目标检测、语义分割等任务均能取得很好的效果。