内容概要
1、for循环原理
2、set集合
3、深浅拷贝
主要内容:
一、for循环原理
先看以下示例:
li = [11, 22, 33, 44] for e in li: li.remove(e) print(li) # 结果: [22, 44]
分析原因: for的运行过程,会有一个指针来记录当前循环的元素是哪一个,一开始这个指针指向第0个,然后获取到0个与那素,紧接着删除第0个。这个时候,原来的第一个元素会自动的往前补一个,变成第0个,然而指针会向后移动一次,指向现在的第一个,所以原来的第一个巧妙的躲过了!(本质上来说,for循环只是进行 索每次增加一的操作)
# 看看for的其他操作 li = [11, 22, 33, 44] for i in range(0, len(li)): del li[i] print(li) # 结果: 报错! 原因:i = 0,1,2 当i=2是此时列表里只有两个数,索引最大才是1 #试试 pop() for el in li: li.pop(el) print(li) # 结果还是[11,22] 始终每次删除指针和位置缩进会导致错位的发生 # 以下两种才是正解: for i in range(0, len(li): li.pop() # 让每一次删除的位置变化都记录下来 print(li) # 或则用以下方法: del_li = [] for e in li : dei_li.append(e) for e in del_li: li.remove(e) # 来一个隔山打牛 print(li)
补充知识点:
dic中的元素在迭代的过程中是不允许进行删除的
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦⽼板'} # 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
del dic[k] # dictionary changed size during iteration, 在循环迭 代的时候不不允许进⾏行行删除操作
print(dic)
#怎么办??? 我们可以把要删除的元素记录下来,保存在一个列表中,然后再循环list,进行删除
dic = {'k1': 'alex', 'k2': 'wusir', 's1': '⾦老板'}
dic_del_list = [] # 删除key中带有'k'的元素
for k in dic:
if 'k' in k:
dic_del_list.append(k)
for el in dic_del_list:
del dic[el]
print(dic)
类型转换:
元组 ---> 列表 list(tuple)
列表 ---> 元组 tuple(list)
集合 ---> 列表 set(list)
转换成False的数据:0,'',None,[],{},(),set()
print(bool(set()))
print(bool({}))
dic = {"apple":"苹果", "banana":"香蕉"} # 返回新字典. 和原来的没关系
ret = dic.fromkeys("orange", "橘子") # 直接用字典去访问fromkeys不会对原来的字典产生影响
ret_1 = dict.fromkeys("abc",["哈哈","呵呵", "吼吼"]) # fromkeys直接使用类名进行访问,且默认生成一个新的字典
print(ret)
print(dic) # 对原来的字典dic没有影响 ,而 dict是个类名.fromkeys会生成一个另外的字典
print(ret_1)
结果:{'o': '橘子', 'r': '橘子', 'a': '橘子', 'n': '橘子', 'g': '橘子', 'e': '橘子'} {'a': ['哈哈', '呵呵', '吼吼'], 'b': ['哈哈', '呵呵', '吼吼'], 'c': ['哈哈', '呵呵', '吼吼']}
a = ["哈哈","呵呵", "吼吼"]
ret = dict.fromkeys("abc", a) # fromkeys直接使用类名进行访问
a.append("嘻嘻")
print(ret) # {'a': ['哈哈', '呵呵', '吼吼', '嘻嘻'], 'b': ['哈哈', '呵呵', '吼吼', '嘻嘻'], 'c': ['哈哈', '呵呵', '吼吼', '嘻嘻']}
二 、set集合
set集合是python的⼀一个基本数据类型. ⼀一般不是很常⽤用. set中的元素是不重复的(去重).⽆无序的(没有固定的索引).⾥里里 ⾯面的元素必须是可hash的(int, str, tuple,bool), 我们可以这样来记. set就是dict类型的数据但 是不保存value, 只保存key. set也⽤用{}表示
数据类型的总结:
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
| 不可变 | 数字,字符串,元组 |
按访问顺序区分
| 直接访问 | 数字 |
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) |
字典 |
集合的定义: s = set() # 这就创建了一个空集合
1、集合的去重:
s = {'王立’ ,'王立','小珠'}
print(s) # 一定要区分集合和字典,字典是有键值对,而集合没有键值对!
# 利用去重的特性我们可以讲一个含有重复数据的列表去重: set(list)
# 注意: set集合中的元素必须是可hash的(也就是不可变元素),否则会报错!但是集合本身是可hash的 !
set = {'1', 'wangli', True, [1, 2, 3]} # 报错
set_1 = {'2', 'xiaozhu', (1, 2, [2, 3, 4]) #同样会报错
2、集合的增删改查:
2.1、增加:
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.add("郑裕玲")
print(s)
s.add("郑裕玲") # 重复的内容不不会被添加到set集合中
print(s) # {'李若彤', '麻', '张曼⽟', '藤', '花', '王祖贤', '刘嘉玲', '关之琳'}
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更更新
print(s) # {'李若彤', '麻', '张曼⽟', '藤', '花', '王祖贤', '刘嘉玲', '关之琳'}
s.update(["张曼玉", "李若彤","李若彤"]) # 在列表里的也是迭代添加进去
print(s) # {'李若彤', '麻', '张曼⽟', '藤', '花', '王祖贤', '刘嘉玲', '关之琳'}
2.2、删除:
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
item = s.pop() # 随机弹出一个.
print(s)
print(item)
s.remove("关之琳") # 直接删除元素
# s.remove("马⻁疼") # 不存在这个元素. 删除会报错
print(s)
s.clear() # 清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和 dict区分的.
print(s) # set()
2.3、修改:
# set集合中的数据没有索引. 也没有办法去定位⼀一个元素. 所以没有办法进⾏行行直接修改. # 我们可以采⽤用先删除后添加的⽅方式来完成修改操作 s = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟玉", "李李若彤"} # 把刘嘉玲改成赵本⼭山 s.remove("刘嘉玲") s.add("赵本⼭山") print(s)
2.4、查找:依旧遍历(没有索引)
# set是⼀一个可迭代对象. 所以可以进⾏行行for循环 for el in s: print(el)
2.5、常用操作:
s1 = {"刘能", "赵四", "⽪⻓山"}
s2 = {"刘科长", "冯乡长", "⽪长山"}
# 交集
# 两个集合中的共有元素
print(s1 & s2)
# {'⽪长⼭'} print(s1.intersection(s2)) # {'⽪⻓山'}
# 并集
print(s1 | s2) # {'刘科长', '冯乡长', '赵四', '⽪⻓山', '刘能'} print(s1.union(s2)) # {'刘科⻓', '冯乡长', '赵四', '⽪长山', '刘能'}
# 差集
print(s1 - s2) # {'赵四', '刘能'} 得到第一个中单独存在的 print(s1.difference(s2)) # {'赵四', '刘能'}
# 反交集
print(s1 ^ s2) # 两个集合中单独存在的数据 {'冯乡长', '刘能', '刘科长', '赵四'}
print(s1.symmetric_difference(s2)) # {'冯乡长', '刘能', '刘科长', '赵四'}
s1 = {"刘能", "赵四"}
s2 = {"刘能", "赵四", "⽪长山"}
# 子集
print(s1 < s2) # set1是set2的⼦集吗? True
print(s1.issubset(s2))
# 超集
print(s1 > s2) # set1是set2的超集吗? False
print(s1.issuperset(s2)
set集合本⾝身是可以发生改变的. 是不可hash的. 我们可以使⽤用frozenset来保存数据. frozenset是不可变的. 也就是⼀个可哈希的数据类型 .
s = frozenset(["赵本山", "刘能", "皮⻓山", "长跪"])
dic = {s:'123'} # 可以正常使⽤用了了
print(dic) # {frozenset({'刘能', '赵本山', '皮⻓山', '长跪'}): '123'} 使其可以作键
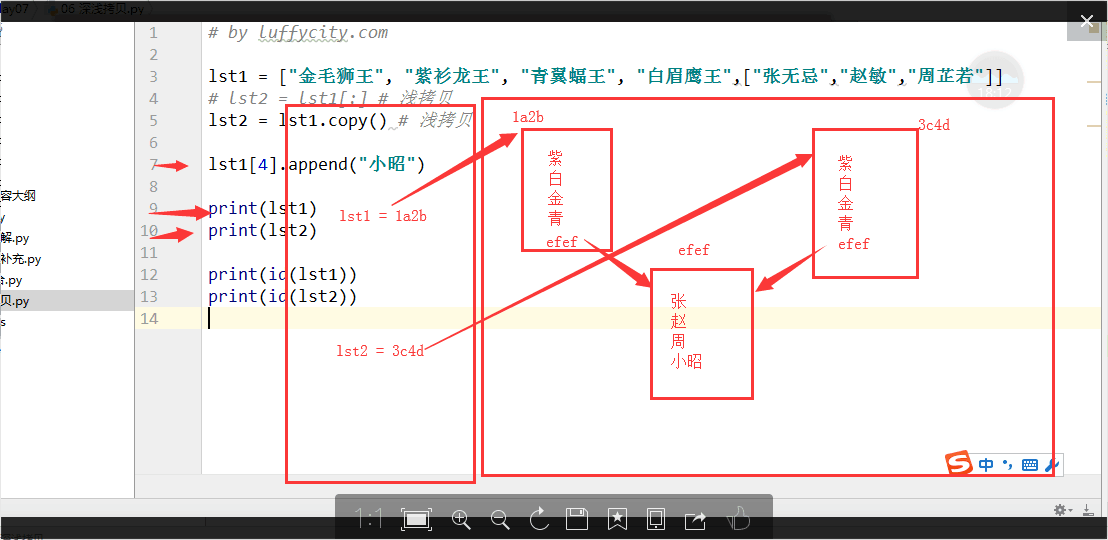
三、深浅拷贝:lst1 = ["何炅", "杜海涛","周渝民"]
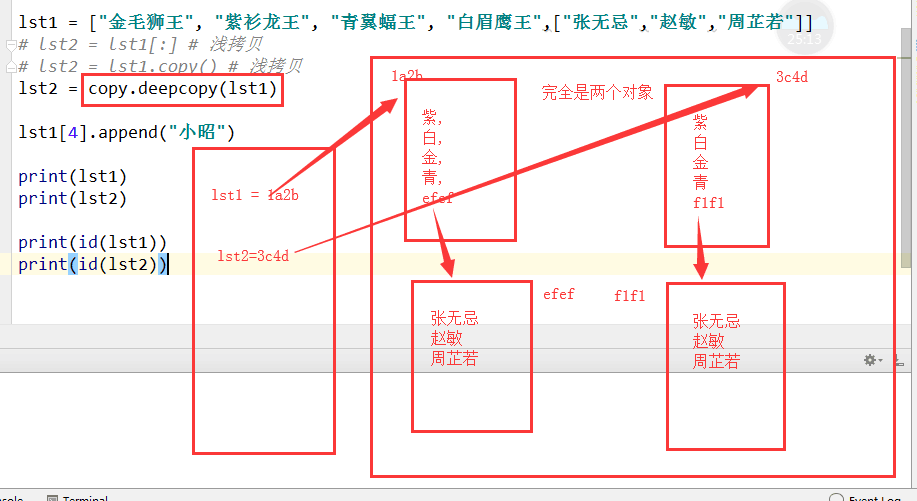
lst2 = lst1.copy() lst1.append("李嘉诚") print(lst1) print(lst2) print(id(lst1), id(lst2)) lst1 = ["何炅", "杜海涛","周渝民", ["麻花藤", "马芸", "周笔畅"]] lst2 = lst1.copy() lst1[3].append("无敌是多磨寂寞") print(lst1) print(lst2) print(id(lst1[3]), id(lst2[3])) ''' 运行结果: ['何炅', '杜海涛', '周渝民', '李嘉诚'] ['何炅', '杜海涛', '周渝民'] 2679402030856 2679401042568 ['何炅', '杜海涛', '周渝民', ['麻花藤', '⻢马芸', '周笔畅', '无敌是多磨寂寞']] ['何炅', '杜海涛', '周渝民', ['麻花藤', '⻢马芸', '周笔畅', '无敌是多磨寂寞']] 2679401060744 2679401060744 ''' 浅拷贝:数据半共享(复制其数据独立内存存放,但是只拷贝成功第一层) 但是第一层虽然拷贝了,但是可以直接修改,在第一层中如果存在嵌套地址,那么修改嵌套里面的数据,大家都会改: lst1 = ["何炅", "杜海涛","周渝民", ["麻花藤", "马芸",[2,3],"周笔畅"]] lst2 = lst1.copy() lst1[3].append("无敌是多磨寂寞") lst1[3][2].append('hahah') print(lst1) print(lst2) #['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', [2, 3, 'hahah'], '周笔畅', '无敌是多磨寂寞']] ['何炅', '杜海涛', '周渝民', ['麻花藤', '马芸', [2, 3, 'hahah'], '周笔畅', '无敌是多磨寂寞']] 深拷贝:数据完全不共享(复制其数据完完全全放独立的一个内存,完全拷贝,数据不共享)深拷贝就是完完全全复制了一份,且数据不会互相影响,因为内存不共享。 import copy l1 = [1, 2, 3, [11, 22, 33]] # l2 = copy.copy(l1) 浅拷贝 l2 = copy.deepcopy(l1) print(l1,'>>>',l2) l2[3][0] = 1111 print(l1,">>>",l2)
补充个面试题:
a = [1, 2]
a[1] = a
print(a) # 结果: [1, [...]]
代码块的缓存机制:
Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,
在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则
他们在内存中只存在一个,即:id相同。
优点:能够提高一些字符串,整数处理人物在时间和空间上的性能;需要值相同的字符串,整数的时候,直接从‘池’里拿来用,避免频繁的创建和销毁,提升效率,节约内存。
代码块的缓存机制的适用范围: int(float),str,bool。
int(float):任何数字在同一代码块下都会复用。
bool:True和False在字典中会以1,0方式存在,并且复用。
str:几乎所有的字符串都会符合缓存机制,具体规定如下(了解即可!)
1,非乘法得到的字符串都满足代码块的缓存机制: s1 = '太白@!#*ewq' s2 = '太白@!#*ewq' print(s1 is s2) # True 2、乘数得到的结果总长度小于20,当乘数是1时是都可以得 s1 = 'old_' * 5 s2 = 'old_' * 5 print(s1 is s2) # True
小数据池:
小数据池,也称为小整数缓存机制,或者称为驻留机制等等,博主认为,只要你在网上查到的这些名字其实说的都是一个意思,叫什么因人而异。
那么到底什么是小数据池?他有什么作用呢?
大前提:小数据池也是只针对 int(float),str,bool。
小数据池是针对不同代码块之间的缓存机制!!!
官方对于整数,字符串的小数据池是这么说的:
Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
其实,无论是缓存还是字符串驻留池,都是python做的一个优化,就是将~5-256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中
那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中之创建一个。
优点:能够提高一些字符串,整数处理人物在时间和空间上的性能;需要值相同的字符串,整数的时候,直接从‘池’里拿来用,避免频繁的创建和销毁,提升效率,节约内存。
int:那么大家都知道对于整数来说,小数据池的范围是-5~256 ,如果多个变量都是指向同一个(在这个范围内的)数字,他们在内存中指向的都是一个内存地址。

str:
1、字符串的长度为0和1,默认都采用驻留机制。
2、字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认。


1 1.⽂件a.txt内容:每⼀⾏内容分别为商品名字,价钱,个数。 2 通过代码,将其构建成这种数据类型:[{'name':'apple','price':10,'amount':3}, 3 {'name':'tesla','price':1000000,'amount':1}......] 并计算出总价钱。 4 5 li=[] 6 with open('a.txt',encoding='utf8',mode='r') as f: 7 for i in f: 8 i = i.split() 9 dic =dict((('name',i[0]),('price', i[1]),('amount' ,i[2]))) # 妙处 10 li.append(dic) 11 sum = 0 12 print(li) 13 for i in li: 14 sum += int(i.get('price')) * int(i.get('amount')) 15 print(sum) 16 17 2.有如下⽂件:将⽂件中所有的alex都替换成⼤写的SB(⽂件的改的操作)。 18 19 import os 20 with open('b.txt',encoding='utf8',mode='r') as f , 21 open('b.bak',encoding='utf8',mode='w') as f2: 22 for i in f: 23 i = i.replace('alex','sb') 24 f2.write(i) 25 26 os.remove('b.txt') 27 os.rename('b.bak','b.txt') 28 29 3、⽂件a2.txt内容(升级题)通过代码, 30 name:apple price:10 amount:3 year:2012 31 name:tesla price:100000 amount:1 year:2013 32 将其构建成这种数据类型[{'name':'apple','price':10,'amount':3,year:2012}, 33 {'name':'tesla','price':1000000,'amount':1}......] 并计算出总价钱。 34 35 li = [] 36 sum = 0 37 with open('a2.txt',encoding='utf8',mode='r') as f: 38 for i in f: 39 dic = {} 40 a = i.split() 41 for v in a: 42 t = v.split(':') 43 for c in t: 44 if t[1].isdigit(): 45 dic[t[0]] = int(t[1]) 46 else: dic[t[0]] = t[1] 47 48 sum += dic['price']*dic['amount'] 49 li.append(dic) 50 print(li) 51 print(sum) 52 53 4、念数字给出一个字典. 在字典中标识出每个数字的发音. 包括相关符号. 然后由用户输入一个数字.让程序读出相对应的发音(不需要语音输出. 单纯的打印即可) 54 55 dic = {'-':'负','0':'零','1':'一','2':'二','3':'三','4':'四','5':'五','6':'六','7':'七','8':'八','9':'九','.':'点',} 56 li = ['十','百','千'] 57 while 1: 58 usr = input(' 请输入(q退出,万位内):').strip() 59 i,c=3,2 60 if usr.startswith('-'): 61 print('负',end='') 62 for a in usr[1:]: 63 print(dic[a],end='') 64 if len(usr)-i>=0: 65 print(li[len(usr)-i],end='') 66 i+=1 67 elif '.' in usr: 68 index = usr.find('.') 69 for a in usr[:index]: 70 print(dic[a],end='') 71 if len(usr[:index])-c>=0: 72 print(li[len(usr[:index])-c],end='') 73 c+=1 74 for i in usr[index:]: 75 print(dic[i],end='') 76 elif usr.lower() == 'q': 77 break 78 else: 79 for a in usr: 80 print(dic[a],end='') 81 if len(usr)-c>=0: 82 print(li[len(usr)-c],end='') 83 c+=1
1、在python中只要是用引号引起来的就是字符串 2、注意 (77)表示77 , (77,)表示元组,同理[77] 3、在py2中,raw_input()与py3中的input类似,都是接受字符串类型。但是在py2中input(),是你输入什么类型,它接受的就是什么类型。 4、 ASCII :不支持中文 UTF-8:英文 1 中文3 GBK :英文1 中文2 Unicode :英文 2 中文4 5、列表 1、增加:append(), insert(), extend() 迭代添加、 2、删除:pop() 、remove() 、clear()、del 切片 3、改 : li[] = '' 注意索引修改时,如果有步长,则要一一对应 4、查: 索引取值,或则 for循环 列表的其他操作: 5、 li.sort(reverse =True) # 排序升序,降序) ###陷阱### lis = [1,2,3] new_list =lis.reverse() print(new_lis) # None 注意是在原来的lis上修改,且返回值是None 6、li.cout() #计数 7、li.index() #获取元素下标 6、字典 1、增: dic['key']='' #索引增 dic.setdefault('key','value') #有则不变、无则添加 2、删: dic.pop('key') #按键删除,有返回值,dic.popitem() #随机删除 dic.clear() # 清空列表 del dic[] 3、改: dic['key'] = '' #重新修改 dic.update(dic2) #有责修改,无则添加 4、查: dic.get() dic['key'] for循环 dic.setdefault('key') 字典的其他函数: 5、dic=dict(('key','value')) # 工厂化字典 6、 dic.fromkeys() #####坑#### d = dict.fromkeys([1,2,3],10) # 当值是一个不可变类型时 print(d) # {1: 10, 2: 10, 3: 10} d[1] = 20 print(d) # {1: 20, 2: 10, 3: 10} d = dict.fromkeys([1,2,3],[]) print(d) # {1: [], 2: [], 3: []} d[1].append(44) print(d) #{1: [44], 2: [44], 3: [44]} 基本数据类型补充: li = [1,2,3] for i in li: li.append(i) # 这是一个无限循环的列表 print(li)