基于上篇的Scala基础语法,本篇讲解Scala的面向对象编程和函数式编程。
一、面向对象编程
1、类
最简单的类的定义形式:
class Counter{ private var value = 0 def increment(): Unit ={ value += 1 } def current(): Unit ={ value } } // 可以使用 new 关键字生成对象 new Counter // 或 new Counter()
Unit后面的等号和大括号后面,包含了该方法要执行的具体操作语句
如果大括号里面只有一行语句,那么也可以直接去掉大括号,写成下面的形式:
class Counter { private var value = 0 // 直接去掉大括号 def increment(): Unit = value += 1 // 或者去掉冒号、返回值类型和等号,只保留大括号 def current() { value } }
创建对象并调用方法:
val myCounter = new Counter myCounter.increment() // 或者省略括号 myCounter.increment
从上面代码可以看出,Scala在调用无参方法时,是可以省略方法名后面的圆括号的。
那么如何在类外部修改类里的私有变量value 的值呢?我们知道,在Java中是指定getter 和 setter 方法的。Scala中对其的实现方式与Java中有些许不同。不再叫做getXxx() 和 setXxx(),而是分别叫做value 和 value_,代码如下:
class Counter { private var priValue = 0 def value = priValue // 定义一个方法, 方法的名称就是我们原来想要的字段的名称 // 设置参数的方法, 参数名 : 数据类型 def value_= (newValue: Int) { // 是 value_= , 下划线和等号之间不能有空格 priValue = newValue } def increment(step: Int): Unit = value += step def current() { value } } object myCounter{ def main(args: Array[String]): Unit = { val myCounter = new Counter println(myCounter.value) // 打印 value 的初始值 : 0 myCounter.value = 3 // 为 value 设置新值 println(myCounter.value) // 3 myCounter.increment(1) // 这里步长为 1, 每次 +1 println(myCounter.value) // 4 } }
主构造器 和 辅助构造器
Scala构造器包含1个主构造器和若干个(0个或多个)辅助构造器
辅助构造器的名称为this,每个辅助构造器都必须调用一个此前已经定义的辅助构造器或主构造器
Scala的每个类都有主构造器。但是,Scala的主构造器和Java有着明显的不同,Scala的主构造器是整个类体,需要在类名称后面罗列出构造器所需的所有参数,这些参数被编译成字段,字段的值就是创建对象时传入的参数的值。
class Counter(val name: String, val mode: Int) { def info(): Unit ={ printf("name: %s and mode: %d ", name, mode) } // 第一个辅助构造器 def this(name:String){ this(name,2) } // 第二个辅助构造器 def this(){ this("3",3) } } object myCounter{ def main(args: Array[String]): Unit = { val myCounter1 = new Counter("Time1",1) // 主构造器 val myCounter2 = new Counter("Time2") // 辅助构造器 myCounter2.info } }
2、对象
2.1 单例对象
和类定义很像,不同的是单例对象用 object 关键字定义。
2.2 伴生对象
在Java中,我们经常需要用到同时包含实例方法和静态方法的类,在Scala中可以通过伴生对象来实现。
当单例对象与某个类具有相同的名称时,它被称为这个类的“伴生对象”。
类和它的伴生对象必须存在于同一个文件中,而且可以相互访问私有成员(字段和方法)。
class Person { private val id = Person.newPersonID() // 调用了伴生对象的方法 private var name = "" def this(name:String){ this() this.name = name } def info(): Unit ={ printf("name: %s, id: %s", name, id) } } object Person{ private var lastID = 0 private def newPersonID() ={ lastID += 1 lastID // 返回值 } def main(args: Array[String]): Unit = { var person1 = new Person("张三") var person2 = new Person("李四") person1.info // name: 张三, id: 1 person2.info // name: 李四, id: 2 } }
从上面结果可以看出,伴生对象中定义的newPersonld()实际上就实现了Java中静态( static)方法的功能
Scala源代码编译后都会变成JVM字节码,实际上,在编译上面的源代码文件以后,在Scala里面的class和object在Java层面都会被合二为一,class里面的成员成了实例成员,object成员成了static成员。
apply方法 和 update 方法
3、继承
Scala中的继承与Java有着显著的不同:
(1)重写一个非抽象方法必须使用override修饰符。
(2)只有主构造器可以调用超类的主构造器。
(3)在子类中重写超类的抽象方法时,不需要便用override关键字。
(4)可以重写超类中的字段。
Scala和Java一样,不允许类从多个超类继承。下面我们创建一个抽象类。
abstract class Car { // 是抽象类, 不能直接被实例化 var carBrand: String // 字段没有初始化值,就是一个抽象字段 def info() // 抽象方法,不需要使用abstract关键字 def greeting(){println("Welcome to my car.")} }
关于上面的定义,说明几点:
(1)定义一个抽象类,需要使用关键字abstract。
(2)定义一个抽象类的抽象方法,不需要关键字 abstract ,只要把方法体空着,不写方法体就可以。
(3)抽象类中定义的字段,只要没有给出初始化值,就表示是一个抽象字段,但是,抽象字段必须要声明类型,比如: val carBrand: String,就把carBrand声明为字符串类型,这个时候,不能省略类型,否则编译会报错
抽象类不能直接被实例化,所以,下面我们定义扩展类,用来扩展抽象类Car类,或者说继承自Car类。
abstract class Car { // 是抽象类, 不能直接被实例化 var carBrand: String // 字段没有初始化值,就是一个抽象字段 def info() // 抽象方法,不需要使用abstract关键字 def greeting(){println("Welcome to my car.")} } class MyCar extends Car { override var carBrand: String = "mine" // 重写超类字段,需要使用 override 关键字 def info(): Unit = println("MyCar!") // 重写超类的抽象方法,加不加 override 都可以 override def greeting(): Unit = println("myCar greeting") // 重写非抽象方法,必须加 override }
4、特质
4.1 概述
- Java中提供了接口,允许一个类实现任意数量的接口
- 在Scala中没有接口的概念,而是提供了“特质(trait)”,它不仅实现了接口的功能,还具备了很多其他的特性
- Scala的特质,是代码重用的基本单元,可以同时拥有抽象方法和具体方法
- Scala中,一个类只能继承自一个超类,却可以实现多个特质,从而重用特质中的方法和字段,实现了多重继承
特质的定义和类的定义非常相似,有区别的是,特质定义使用关键字trait。
trait carId{ var id: Int def currentId(): Int //定义了一个抽象方法 }
上面定义了一个特质,里面包含一个抽象字段id和抽象方法currentld。注意,抽象方法不需要使用abstract关键字,特质中没有方法体的方法,默认就是抽象方法。
特质定义好以后,就可以使用extends或with关键字把特质混入类中,并且,特质中的方法既可以抽象,也可以具体。
trait CarId { var id: Int def currentId(): Int // 定义了一个抽象方法 } trait CarGreeting{ def greeting(msg: String){println(msg)} // 非抽象方法 } class BYDCarId extends CarId with CarGreeting { // 继承自多个特质时用 with override var id: Int = 10000 override def currentId(): Int = { id += 1; id } }
5、模式匹配
5.1 简单匹配
模式匹配最常用于 match 语句中。
object Match { def main(args: Array[String]): Unit = { val colorNum = 4 val colorStr = colorNum match { case 1 => "red" case 2 => "green" case 3 => "yellow" case unexpected => unexpected + "is Not Allowed" // unexpected 为自定义的变量 } println(colorStr) }
5.2 类型模式
对表达式的类型进行匹配
for (elem <- List(9, 12.3, "Spark", "Hadoop", 'Hello)) { var str = elem match { case i: Int => i + " is an int value" case d: Double => d + " is a double value" case "Spark" => "Spark is not found" case s: String => s + " is a string value" case _ => "This is an expected value" } println(str) }
5.3 "守卫(Guard)" 语句
可以在模式匹配中添加一些必要的处理逻辑。
for (elem <- List(1,2,3,4)){ elem match { case _ if (elem % 2 == 0) => println(elem + " is even") case _ => println(elem + " is odd") } }
5.4 for表达式中的模式

5.5 case类的匹配
case类是一种特殊的类,它们经过优化以被用于模式匹配。
case class Car(brand: String, price: Int) object Car{ def main(args: Array[String]): Unit = { val myBYDCar = new Car("BYD", 89000) val myBMWCar = new Car("BMW", 120000) val myBenzCar = new Car("Benz", 150000) for (car <- List(myBYDCar, myBMWCar, myBenzCar)) { car match { case Car("BYD", 89000) => println("Hello BYD!") case Car("BMW", 120000) => println("Hello BMW!") case Car("Benz", 150000) => println("Hello Benz!") } } } }
5.6 Option类型
在得到函数返回值的时候,总是不可避免的会遇到空值,Scala 的 Option 类型就是使得空值 None 和其他值一样,他们都被封装在 Option 中。
Option 类型提供了 Some 类和 None对象,即有值,不为空时(假设这个值为 a),则返回 Some(a),否则返回 None 对象。例子如下:
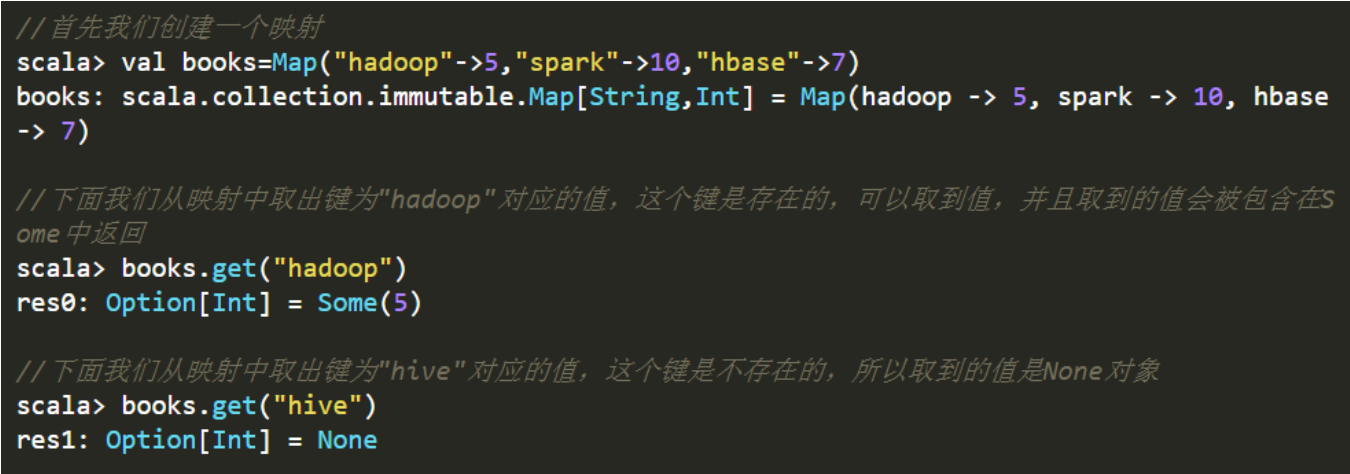
Option类型还提供了getOrElse方法,这个方法 在这个Option是Some的实例 时返回对应的值,而在 是None的实例时 返回传入的参数。例如:
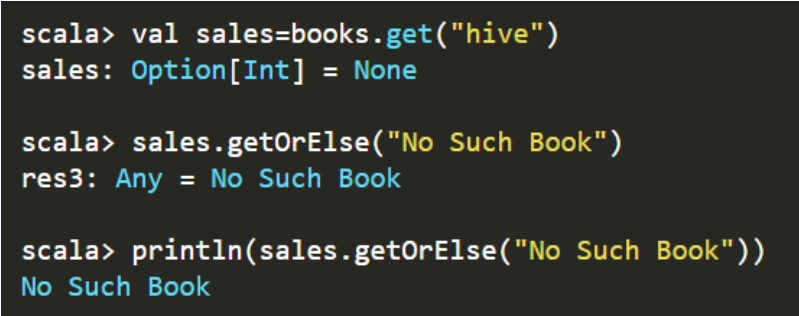
可以看出,当我们采用getOrElse方法时,如果我们取的"hive"没有对应的值,我们就可以显示我们指定的“No Such Book”,而不是显示None。
在Scala中,使用Option的情形是非常频繁的。在Scala里,经常会用到Option[T]类型,其中的T可以是Sting或Int或其他各种数据类型。
Option[T]实际上就是一个容器,我们可以把它看做是一个集合,只不过这个集合中要么只包含一个元素(被包装在Some中返回),要么就不存在元素(返回None) 。
既然是一个集合,我们当然可以对它使用map、foreach或者filter等方法。比如:
scala> books.get( "hive" ).foreach(println)
可以发现,上述代码执行后,屏幕上什么都没有显示,因为,foreach遍历遇到None的时候,什么也不做,自然不会执行printIn操作。
二、函数式编程基础
函数定义
定义函数最通用的方法是作为某个类或者对象的成员,这种函数被称为方法,其定义的基本语法为 “ def 方法名 ( 参数列表 ) : 结果类型 = { 方法体 } ”
函数字面量
字面量包括整数字面量、浮点数字面量、布尔型字面量、字符字面量、字符串字面量、符号字面量、函数字面量和元组字面量。
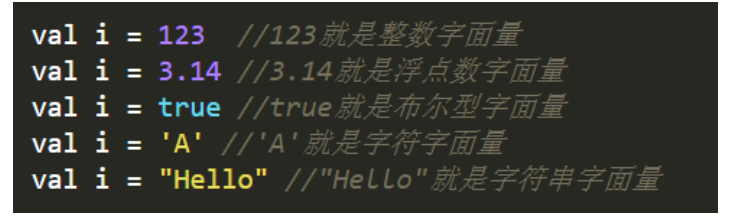
所以说,什么是函数的字面量呢?
函数字面量可以体现函数式编程的核心理念。
在函数式编程中,函数是“头等公民”,可以像任何其他数据类型一样被传递和操作,也就是说,函数的使用方式和其他数据类型的使用方式完全一致了。
这时,我们就可以像定义变量那样去定义一个函数,由此导致的结果是,函数也会和其他变量一样,开始有“值”。
就像变量的“类型”和“值”是分开的两个概念一样,函数式编程中,函数的“类型”和“值”也成为两个分开的概念,函数的“值”,就是“函数字面量”。
函数的类型 和 值
给出一个函数定义如下:
def counter(value: Int): Int = { value += 1}
上面这个函数的 ”类型“ 为 (Int) => Int 。注意:需要使用符号 =>
实际上,只有多个参数时(不同参数之间用逗号隔开),圆括号才是必须的,当参数只有一个时,圆括号可以省略,如 Int => Int。这就得到了函数的类型
下面看看如何得到函数的“值”。
实际上,我们只要把函数定义中的类型声明部分去除,剩下的就是函数的“值”,如下:
(value) => {value += 1} //只有一条语句时,大括号可以省略
注意:上面就是函数的“值”,需要注意的是,采用“=>”而不是“=",这是Scala的语法要求。
现在,我们再按照大家比较熟悉的定义变量的方式,采用Scala语法来定义一个函数。
声明一个变量时,我们采用的形式是:
val num: Int = 5 //当然,Int类型声明也可以省略,因为Scala具有自动推断类型的功能
照葫芦画瓢,我们也可以按照上面类似的形式来定义Scala中的函数:
val counter: Int => Int = { (value) => value += 1 }
从上面可以看出,在Scala中,函数已经是“头等公民”,单独剥离出来了“值”的概念,一个函数“值”就是函数字面量。这样,我们只要在某个需要声明函数的地方声明一个函数类型,在调用的时候传一个对应的函数字面量即可,和使用普通变量一模一样。
匿名函数、Lamda表达式与闭包
我们不需要给每个函数命名,这时就可以使用匿名函数,如:(num: Int) => num* 2
上面这种匿名函数的定义形式,我们经常称为“Lamda表达式”。“Lamda表达式”的形式如下:
(参数) =〉表达式//如果参数只有一个,参数的圆括号可以省略
我们可以直接把匿名函数存放到变量中,下面是在Scala解释器中的执行过程:

实际上,Scala具有类型推断机制,可以自动推断变量类型,比如下面两条语句都是可以的:
val number: Int = 5 val number =5//省略Int类型声明
所以,上面的定义中,我们可以myNumFunc的类型声明,也就是去掉“Int=>lnt”',在Scala解释器中的执行过程如下:
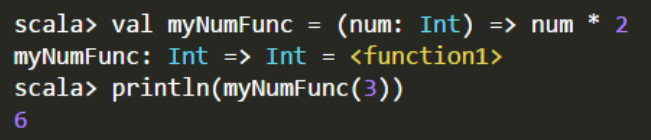
如果这时,我们再省略 num 的 Int 类型,则会报错,因为全部省略后,scala 也无法判断类型。
下面我们尝试省略 num 的 Int 类型,但是给出函数 myNumFunc 的类型声明,在Scala解释器中的执行过程如下:

则不会报错。
闭包是一个函数,一种比较特殊的函数,它和普通的函数有很大区别

占位符语法
为了让函数字面量更加简洁,我们可以使用下划线作为一个或多个参数的占位符,只要每个参数在函数字面量内仅出现一次。

从上面运行结果可以看出,下面两个函数字面量是等价的。
x => x>0
_ > 0
有时你把下划线当作参数的占位符时,编译器有可能没有足够的信息推断缺失的参数类型。例如,假设你只是写_+_,则会报错。
这种情况下,可以运用冒号指定类型,如下:
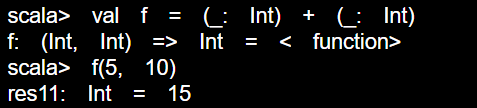
请留心 _+_ 将扩展成带两个参数的函数字面量。这也是仅当每个参数在函数字面量中最多出现一次的情况下你才能运用这种短格式的原由。多个下划线指代多个参数,而不是单个参数的重复运用。第一个下划线代表第一个参数,第二个下划线代表第二个,第三个......,如此类推。
总结以上,需要的深入理解与勤加练习,加油!