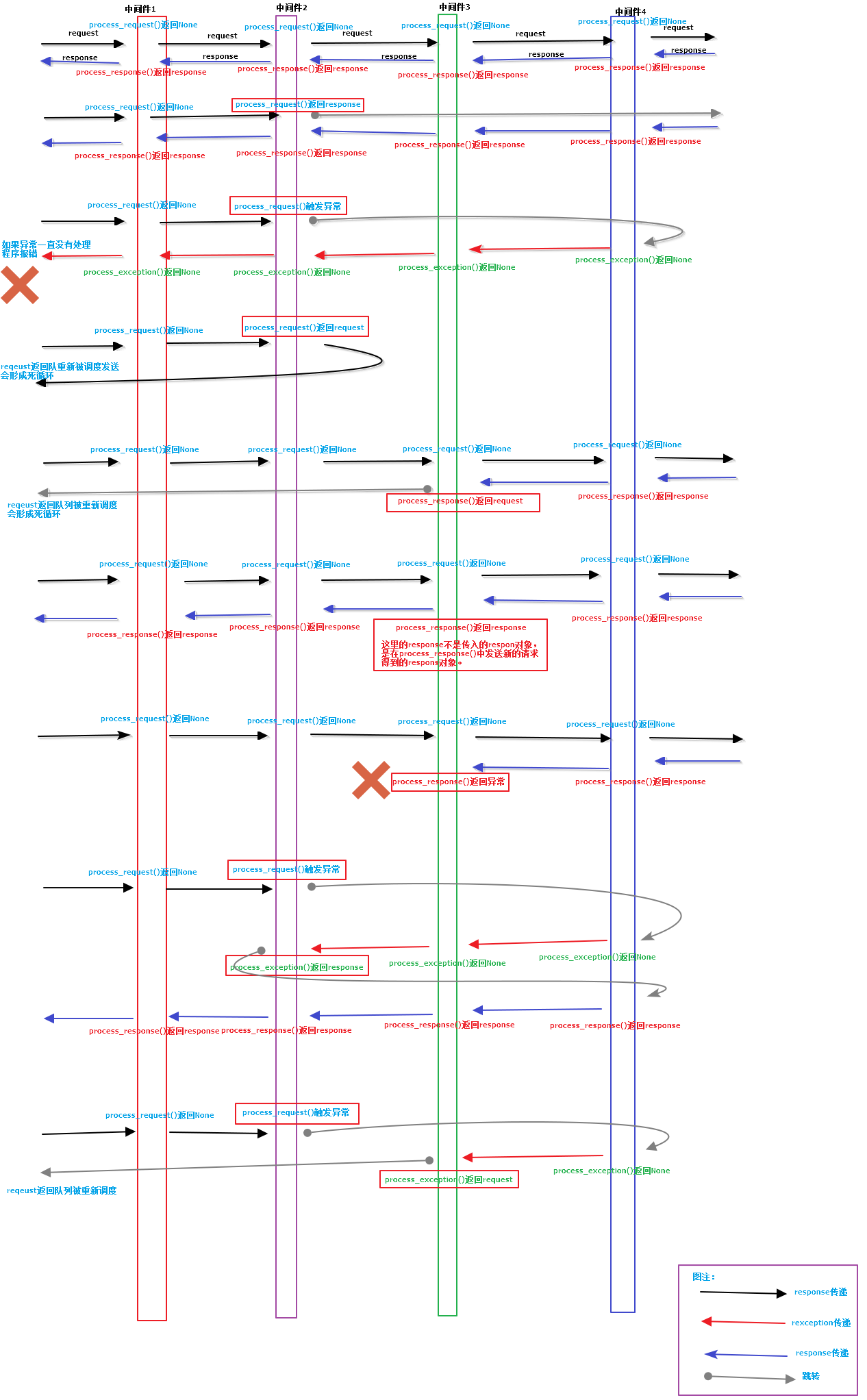
scrapy-下载中间件
每个下载中间件组件是定义了以下一个或多个方法的Python类
■ process_request(request,spider)
■ process_response(request,response,spider)
■ process_exception(request,exception,spider)
下面分别介绍这三种中间件。
1.Process_request(request,spider)
方法说明:当每个request通过下载中间件时,该方法被调用,返回值必须为None、Response对象、Request对象中的一个或Raise IgnoreRequest异常。
参数:
request(Request对象):处理的request。
spider(Spider对象):该request对应的spider。
返回值:
如果返回None,Scrapy将继续处理该request,执行其他的中间件中的响应方法,直到合适的下载器处理函数被调用,该request被执行(其respose被下载)。
如果返回Reponse对象,scrapy不会调用其他的process_request(),process_exception()方法,或相应的下载方法,将返回response。已安装的中间件的process_response()方法则会在每个response返回时被调用。
如果返回Request对象,Scrapy则停止调用process_request() 方法并重新调度返回的request。当新返回的request被执行后,相应的中间件链将会根据下载的response被调用。
如果返回的是Raise IgnoreRequest 异常,则安装的下载中间件的process_exception()方法会被调用。如果没有任何一个方法处理该异常,则request的errback方法会被调用。如果没有代码处理抛出的异常,则该异常被忽略且不记录。
2.process_response(request,response,spider)
方法说明:该方法主要用来处理产生的response,返回值必须是Response对象、Request对象中的一个或Raise IgnoreRequest异常。
参数:
request(Request对象):response对应的request。
response(Response对象) :处理的response。
spider(Spider对象):response对应的spider。
返回值:
如果返回Response对象,可以与传入的response相同,也可以是新的对象,该response会被链中的其他中间件的process_response()方法处理。
如果返回Request对象,则中间件链停止,返回的request会被重新调度下载。处理类似于process_request()返回request时所做的那样。
如果爬出IgnoreReqeust异常,则调用reqeust的errback方法。如果没有代理处理抛出的异常,则该异常被忽略且不记录。
3.process_exception(request,exception,spider)
方法说明:当下载器或process_reqeust()抛出异常,比如IgnoreRequest异常时,Scrapy调用process_exception()。process_exception()应返回None,Response对象或者Request对象其中之一。
参数:
request(Request对象):产生异常的request。
exception(Exception对象):抛出的异常。
spider(Spier对象):Request对应的spider。
返回值:
如果返回None,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的process_exception()方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
如果返回Response对象,则已安装的中间件链的process_response()被调用。Scrapy将不会调用任何其他中间件的process_exception()方法。
如果返回Reqeust对象,则返回的reqeust将会被重新调用下载,这将停止中间件process_exception()方法执行,类似 于返回Response对象的处理。
下面使用图说明scrapy的下载中间件的机制: