感觉又是效率不高的一天,上午主要验证两个bug,其中一个是因为sqlserver2000中我们数据库定义的varchar(60)只能存入30个汉字造成的,果然还是他们经常测试的经验丰富一下子就知道是数据库中字段存入过少造成的;也很惭愧自己当时在做这个功能是居然没考虑到这个临界条件,可能是我对之前的同时太过信任了吧。然后是和另外一个同事讨论了组内的问题,产品太多而竞争力不足,组织架构有点混乱。下午主要是两个分公司的项目支持,然后是看些SSH方面的知识;晚上江南体育中心游泳,大概3.5KM。回顾下今天看到的几个好的知识点:
来数据库的操作包括:增(create,insert),删(delete,drop),改(alter,update),查(select),这里对于安全管理,还要控制(grant,revoke)操作,它们几个囊括了SQL的9种基本语句。当然要想实现真正的对其操作管理,还需要T-SQL程序设计基础为中间工具,利用控制流程将我们需要用的函数,定义好的变量,和需要的数据类型,还要我们要用的SQL语句,串联起来,使之共同起作用达到控制操作的目的。http://aiguoniis.iteye.com/blog/1632430
如:物品表(wuPin) :id,name,types,units (自增,物品名称,物品类型,管理单位) 
案件表(anJian) :id,name,types,units (自增,案件名称,案件类型,管理单位)
查询条件:根据"管理单位"统计其下有多少贵重物品、危险物品、刑事案件、治安案件。最后要的结果如下:
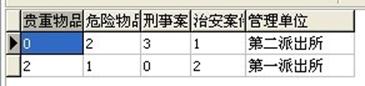
参考方法:SELECT sum(DECODE(a.types,'贵重物品',1,0)) AS 贵重物品,
sum(DECODE(a.types,'危险物品',1,0)) AS 危险物品,
sum(DECODE(a.types,'刑事案件',1,0)) AS 刑事案件,
sum(DECODE(a.types,'治安案件',1,0)) AS 治安案件,
a.units AS 管理单位
FROM (SELECT * FROM anJian UNION ALL SELECT * FROM wupin) a
GROUP BY units ;
或SELECT sum(if(a.types='贵重物品',1,0)) AS 贵重物品,
sum(if(a.types='危险物品',1,0)) AS 危险物品,
sum(if(a.types='刑事案件',1,0)) AS 刑事案件,
sum(if(a.types='治安案件',1,0)) AS 治安案件,
a.units AS 管理单位
FROM (SELECT * FROM anJian UNION ALL SELECT * FROM wupin) a
GROUP BY units
一个应用商店网站,想把'用户管理'和'应用商店'放在两个不同的项目中。1.请问怎么实现登录后 '用户管理'应用能检测到已经登录的用户, '应用商店'也能检测?并能够获取用户信息。
2.怎么实现注销后'用户管理'和'应用商店'能同时响应,求具体策略。
登录后,肯定有个登录成功的标识。现在是采用分布的部署,那么这两个项目应该向同一个地方获取登录标识。
比如说:登录成功,生成一个随机串,并把该串以及登录账号放到分布式缓存中、或者是数据库中。当用户点击"用户管理",把这个随机串附加到url上,用户管理接收到请求,根据附加的随机串,向数据库或分布式缓存中获取该串对应的账号。注销的时候,把数据清除掉。如果是部署在不同的机器上,有域名的话,可采用cookie。
IOC:inverse of Control:控制反转。意思是程序中对象之间的关系,不用代码控制,而完全是由容器来控制。在运行阶段,容器会根据配置信息直接把他们的关系注入到组件中。同样,这也是依赖注入的含义。依赖注入和控制反转其实是一个概念。只不过强调的不同而已,依赖注入强调关系的注入是由容器在运行时完成,而控制反转强调关系是由容器控制。其实本质是一样的。
spring中的依赖注入DI(dependence injection)共有三种方式:第一种是接口注入(Interface Injection)第二种是get set注入(set/get Injection)第三种是构造器注入(Constructor Injection)
三种注入方式的区别:
1.接口注入:组件需要依赖特定接口的实现,其中的加载接口实现和接口实现的具体对象都是由容器来完成。这样,接口必须依赖容器,这样的组件具有侵入性,降低了重用性。其中如J2EE开发中常用的Context.lookup(ServletContext.getXXX),都是接口注入的表现形式。(这种注入方式不是常用的)
2.getter/setter方式注入:对于需要注入的东西比较明确。符合java的设计规则。更适合java开发人员,使用起来更加自然,更加方便。
3.构造器方式注入:在类加载的时候,就已经注入依赖的组件。但是若是参数多的话,使用起来不方便。
但是后两种注入方式是spring常用的,而第一种接口注入方式不常用。
使用Hibernate进行访问持久层,每次都要进行八个步骤:1. 获得Configuration对象
2. 创建SessionFactory
3. 创建Session
4. 打开事务
5. 进行持久化操作。比如上面的添加用户操作
6. 提交事务
7. 发生异常,回滚事务
8. 关闭事务
若使用Spring对Hibernate进行管理,又是怎么样的呢?
首先,Spring对Hibernate提供了HibernateTemple类。这个模版类对session进行封装。并且Spring会默认为自动提交事务。所在在dao层直接写入this.save(Object)即可。
若使用Spring管理Hibernate,则默认的是自动提交事务。但是在此,需要注意的是:若使用Spring在配置文件中配置数据源而不使用hibernate.cfg.xml,则可以成功插入数据库,因为HibernateTemple默认提供自动提交事务。在Spring的配置文件配置数据源如下:使用此数据源需要的jar如下:commons-dbcp.jar,commons-pool.jar,msbase.jar,mssqlserver.jar, msutil.jar,sqljdbc4.jar;
- <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
- <property name="driverClassName" value="com.microsoft.jdbc.sqlserver.SQLServerDriver"></property>
- <property name="url" value="jdbc:sqlserver://192.168.24.176:1433;database=test"></property>
- <property name="username" value="sa"></property>
- <property name="password" value="123"></property>
- </bean>
- <bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
- <property name="dataSource" ref="dataSource"></property>
- <!-- hibernate属性配置 -->
- <property name="hibernateProperties">
- <props>
- <prop key="hibernate.dialect">org.hibernate.dialect.SQLServerDialect</prop>
- <prop key="hibernate.hbm2ddl.auto">update</prop>
- </props>
- </property>
- lt;!-- 如果采用传统的hbm.xml的方式,可以采用如下方式来简化注册hbm.xml的步骤,并且class为LocalSessionFactoryBean -->
- <property name="mappingLocations">
- <list>
- <value>classpath:User.hbm.xml</value>
- </list>
- </property>
- </bean>
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.microsoft.jdbc.sqlserver.SQLServerDriver"></property>
<property name="url" value="jdbc:sqlserver://192.168.24.176:1433;database=test"></property>
<property name="username" value="sa"></property>
<property name="password" value="123"></property>
</bean>
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="dataSource"></property>
<!-- hibernate属性配置 -->
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">org.hibernate.dialect.SQLServerDialect</prop>
<prop key="hibernate.hbm2ddl.auto">update</prop>
</props>
</property>
<!-- 如果采用传统的hbm.xml的方式,可以采用如下方式来简化注册hbm.xml的步骤,并且class为LocalSessionFactoryBean -->
<property name="mappingLocations">
<list>
<value>classpath:User.hbm.xml</value>
</list>
</property>
</bean>
若Spring中不是直接配置数据源,而是使用hibernate.cfg.xml,则是无法若直接this.save(Object),则无法插入数据库中,但是可以保存中缓存中。因为所有的操作都是在事务中执行的,而hibernate.cfg.xml数据源则默认是不是自动提交的。解决的办法如下:可以在hibernate.cfg.xml中填写:
<property name="hibernate.connection.autocommit">true</property>
以下Spring使用hibernate.cfg.xml数据源
- <bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
- <property name="configLocation">
- <value>classpath:hibernate.cfg.xml</value>
- </property>
- <property name="mappingLocations">
- <list>
- <value>classpath:User.hbm.xml</value>
- </list>
- </property>
- </bean>
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="configLocation">
<value>classpath:hibernate.cfg.xml</value>
</property>
<property name="mappingLocations">
<list>
<value>classpath:User.hbm.xml</value>
</list>
</property>
</bean>
以上,介绍了Spring来管理Hibernate的好处在于,不用手动创建SessionFactory,Session,不用手动开启提交关闭事务,这一切完全都是由Spring来管理。并且Spring还提供了HibernateTemple的工具,使一切操作简单方便。
dao层在Spring配置文件中配置如下:
- <<span style="font-size: 12px;">bean id="userDao" class="com.UserDao.UserDaoImpl">
- <property name="sessionFactory" ref="sessionFactory"></property>
- </bean></span>
<bean id="userDao" class="com.UserDao.UserDaoImpl">
<property name="sessionFactory" ref="sessionFactory"></property>
</bean>
则在dao层的代码如下:
- package com.UserDao;
- import org.springframework.orm.hibernate3.HibernateTemplate;
- import com.user.User;
- public class UserDaoImpl extends HibernateTemplate implements UserDao {
- @Override
- public void insert(User user) {
- this.save(user);
- }
- }
开始写程序的主要的目的是为了实现功能,至于如何设计不管。也就是过程不重要,结果重要。所以当时的设计思路就是jsp直接调用后台。
结构图如下:

这种情况:把页面和业务逻辑代码都写到一块,写在jsp文件中,也就是在文件表头有一大部分java代码。
但是这种设计模式,随着业务发生的改变,jsp文件需要大批量的改动。缺点是耦合度太强。
紧接着,为了减少jsp与后台业务逻辑的关联度,逐渐地把jsp文件中的大部分java代码提取出来,放到一个类中,放到类就是Servlet,结构图如下:

这种情况:jsp的职责减轻,只用来显示界面。而接受界面的参数转化的操作则放到Servlet中。这就是典型的MVC。
但是完全实现MVC,则增加了编写的复杂度。比如:开始我们遇到转向问题,Servlet转到jsp中,我们都已经写死了,比如程序中:
request.getRequestDispatcher("/flowcard/flow_card_maint.jsp").forward(request, response);
若是修改jsp文件名称时,还需要修改Servlet。并且表单上的获取的数据都是字符串,我们必须根据需要将字符串手动转化。
而这些问题,使用struts框架一扫而光,至于表单数据类型的转化,错误的处理,表单的转向,struts做了很好的封装。
struts框架很好地实现了MVC模式,封装了很多东西,不需要我们程序员手动封装操作。因此,struts为了帮助减少我们用mvc设计开发的时间。我们在设计时需要什么呢?
第一:页面;用来展示给客户的载体。
第二:数据:页面展示需要的内容来源。
第三:处理数据的场合:如何处理页面所需的数据呢?
其实这三点就是我们所说的MVC。页面--V;数据--M;处理数据的场合--C