一、缺失数据NaN
1 from pandas import Series,DataFrame 2 import numpy as np 3 import pandas as pd 4 string_data = Series(['musickness','choke',np.nan,'love'])
string_data Out[3]: 0 musickness 1 choke 2 NaN 3 love dtype: object
#Series自带isnull方法 string_data.isnull() Out[5]: 0 False 1 False 2 True 3 False dtype: bool
#None也会被当做NA处理 string_data[0] = None string_data.isnull() Out[6]: 0 True 1 False 2 True 3 False dtype: bool
二、滤除缺失数据:dropna
#滤除缺失数据 from numpy import nan as NA data = Series([1,NA,3.5,NA,7]) data.dropna() Out[8]: 0 1.0 2 3.5 4 7.0 dtype: float64
方式二:
data.notnull() Out[9]: 0 True 1 False 2 True 3 False 4 True dtype: bool data[data.notnull()] Out[10]: 0 1.0 2 3.5 4 7.0 dtype: float64
DataFrame情况:
data = DataFrame([[1.,6.5,3.],[1,NA,NA], [NA,NA,NA],[NA,6.5,3.]])
#dropna()默认丢弃任何含有缺失值的行 cleaned = data.dropna() cleaned
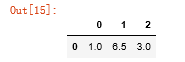
#传入how='all'将只丢弃全为NA的行 data.dropna(how='all')
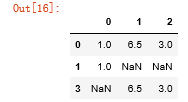
data[4] = NA
data
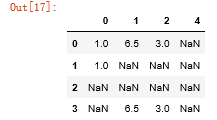
#丢弃列:加axis=1 data.dropna(axis=1,how='all')

df = DataFrame(np.random.randn(7,3)) df.iloc[:4,1] = NA df.iloc[:2,2] = NA df
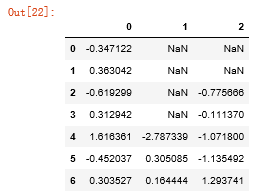
#参数thresh留下部分观测数据 df.dropna(thresh=3)
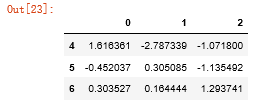
参数thresh(n):如果该行的值(非NA的)大于等于n,就保留下来。
三、填充缺失数据:fillna
df.fillna(0)

#通过一个字典调用fillna,实现对不同的列填充不同的值 df.fillna({1:0.5,2:-1})
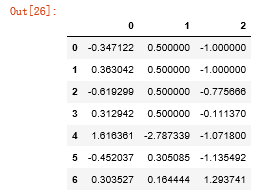
#inplace:修改调用者对象而不产生副本 _ = df.fillna(0,inplace=True) df

inplace参数:
修改一个对象时:
inplace=True:不创建新的对象,直接对原始对象进行修改;
inplace=False:对数据进行修改,创建并返回新的对象承载其修改结果。
from pandas import Series,DataFrame data = DataFrame({'state':['Ohio','Nevada'], 'year':[2019,2020], 'pop':[1.5,2.9]}) data

false_data = data.drop(['year'],axis=1,inplace=False) false_data

data

true_data = data.drop(['year'],axis=1,inplace=True) print(true_data) print(data)
None
state pop
0 Ohio 1.5
1 Nevada 2.9
method:
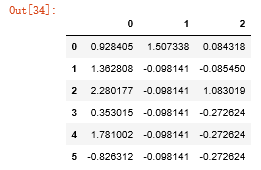
df = DataFrame(np.random.randn(6,3)) df.iloc[2:,1] = NA; df.iloc[4:,2] = NA; df

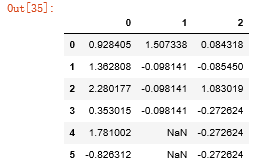
df.fillna(method='ffill')
#limit:可以连续填充的最大数量 df.fillna(method='ffill',limit=2)
#填充平均值 data = Series([1.,NA,3.5,NA,7]) data.fillna(data.mean())
0 1.000000
1 3.833333
2 3.500000
3 3.833333
4 7.000000
dtype: float64