深度学习中Dropout原理解析:https://blog.csdn.net/program_developer/article/details/80737724
一、拟合
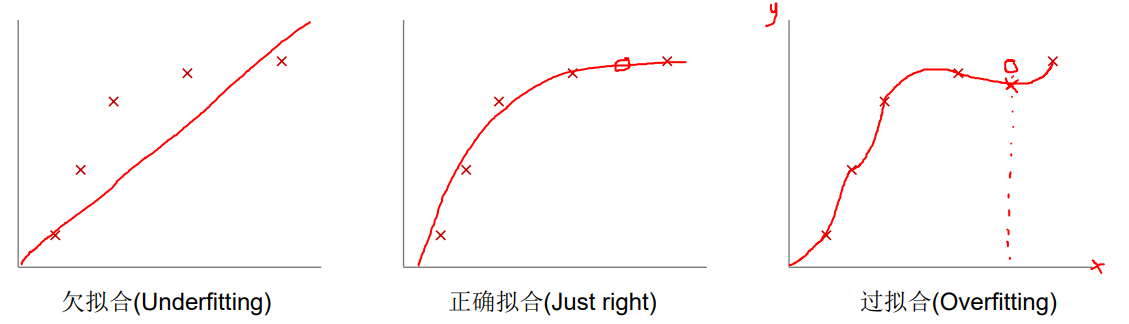
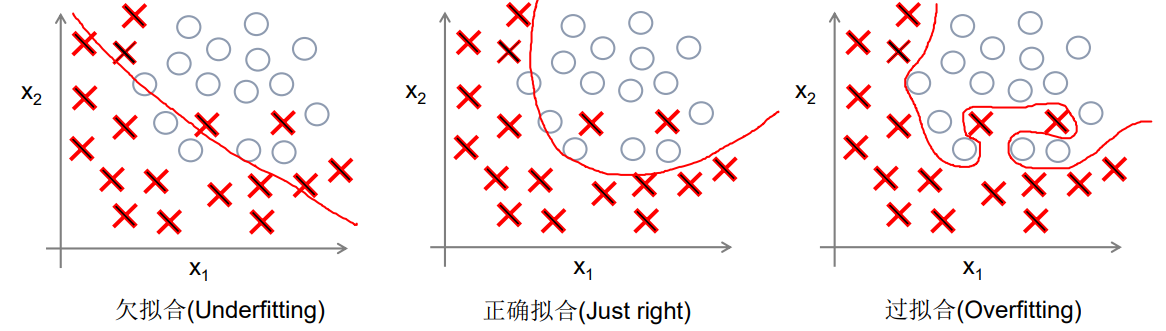
在机器学习的模型中,如果模型的参数太多,模型太复杂,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
二、Dropout解决过拟合
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
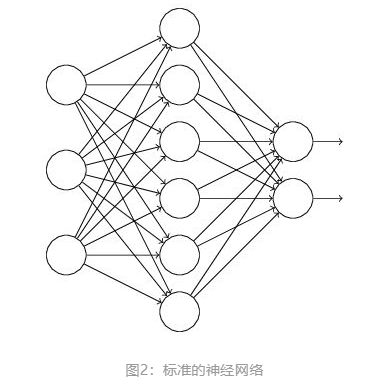
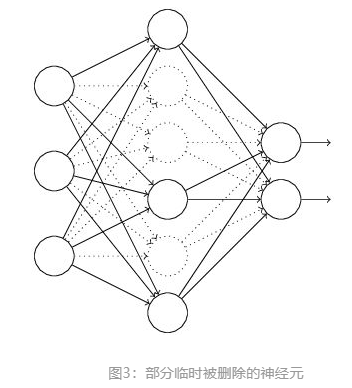
假设我们要训练这样一个神经网络,如图2所示:
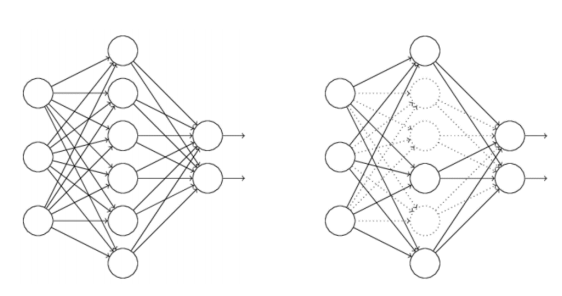
使用dropout之后:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)
(2)然后把输入通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b)(没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。
三、上一小节程序dropout更改
1 import tensorflow as tf
2 from tensorflow.examples.tutorials.mnist import input_data
3
4 #载入数据集
5 mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
6
7 #每个批次的大小
8 batch_size = 100
9 #计算一共有多少个批次
10 n_batch = mnist.train.num_examples // batch_size
11
12 #定义placeholder
13 x = tf.placeholder(tf.float32,[None,784])
14 y = tf.placeholder(tf.float32,[None,10])
15 keep_prob = tf.placeholder(tf.float32)
16
17 #创建一个简单的神经网络
18
19 W1 = tf.Variable(tf.truncated_normal([784,2000],stddev=0.1))
20 b1 = tf.Variable(tf.zeros([2000])+0.1)
21 L1 = tf.nn.tanh(tf.matmul(x,W1)+b1)
22 L1_drop = tf.nn.dropout(L1,keep_prob) #若keep_prob设置为1,则神经元都工作;设置为0.5,则一半的神经元工作
23
24 W2 = tf.Variable(tf.truncated_normal([2000,1000],stddev=0.1))
25 b2 = tf.Variable(tf.zeros([1000])+0.1)
26 L2 = tf.nn.tanh(tf.matmul(L1_drop,W2)+b2)
27 L2_drop = tf.nn.dropout(L2,keep_prob)
28
29 W3 = tf.Variable(tf.truncated_normal([1000,10],stddev=0.1))
30 b3 = tf.Variable(tf.zeros([10])+0.1)
31
32 prediction = tf.nn.softmax(tf.matmul(L2_drop,W3)+b3)
33
34 #交叉熵
35 loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
36
37 #使用梯度下降法
38 train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
39
40 #初始化变量
41 init = tf.global_variables_initializer()
42
43 #结果存放在一个布尔型列表中
44 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一维张量中最大值所在的位置
45 #求准确率
46 accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
47
48 with tf.Session() as sess:
49 sess.run(init)
50 for epoch in range(21):
51 for batch in range(n_batch):
52 batch_xs,batch_ys = mnist.train.next_batch(batch_size)
53 #sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:1.0})
54 sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7})
55 #测试时,keep_prob:1.0,即所有的神经元都工作
56 test_acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0})
57 train_acc = sess.run(accuracy,feed_dict={x:mnist.train.images,y:mnist.train.labels,keep_prob:1.0})
58 print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) +",Training Accuracy " + str(train_acc))
1 keep_prob:0.7
2 Iter 0,Testing Accuracy 0.9254,Training Accuracy 0.917909
3 Iter 1,Testing Accuracy 0.9346,Training Accuracy 0.933145
4 Iter 2,Testing Accuracy 0.9389,Training Accuracy 0.94
5 Iter 3,Testing Accuracy 0.9455,Training Accuracy 0.946
6 Iter 4,Testing Accuracy 0.9495,Training Accuracy 0.951345
7 Iter 5,Testing Accuracy 0.9505,Training Accuracy 0.954164
8 Iter 6,Testing Accuracy 0.9515,Training Accuracy 0.9564
9 Iter 7,Testing Accuracy 0.9539,Training Accuracy 0.959836
10 Iter 8,Testing Accuracy 0.957,Training Accuracy 0.961673
11 Iter 9,Testing Accuracy 0.9583,Training Accuracy 0.963255
12 Iter 10,Testing Accuracy 0.9602,Training Accuracy 0.965273
13 Iter 11,Testing Accuracy 0.9609,Training Accuracy 0.966709
14 Iter 12,Testing Accuracy 0.9611,Training Accuracy 0.968618
15 Iter 13,Testing Accuracy 0.964,Training Accuracy 0.969436
16 Iter 14,Testing Accuracy 0.965,Training Accuracy 0.971055
17 Iter 15,Testing Accuracy 0.9651,Training Accuracy 0.972164
18 Iter 16,Testing Accuracy 0.9653,Training Accuracy 0.972709
19 Iter 17,Testing Accuracy 0.966,Training Accuracy 0.973473
20 Iter 18,Testing Accuracy 0.9674,Training Accuracy 0.974327
21 Iter 19,Testing Accuracy 0.968,Training Accuracy 0.975364
22 Iter 20,Testing Accuracy 0.9676,Training Accuracy 0.976036
1 keep_prob:1.0
2 Iter 0,Testing Accuracy 0.8477,Training Accuracy 0.8526
3 Iter 1,Testing Accuracy 0.9531,Training Accuracy 0.962818
4 Iter 2,Testing Accuracy 0.9603,Training Accuracy 0.971764
5 Iter 3,Testing Accuracy 0.9641,Training Accuracy 0.976945
6 Iter 4,Testing Accuracy 0.9668,Training Accuracy 0.981564
7 Iter 5,Testing Accuracy 0.9689,Training Accuracy 0.9842
8 Iter 6,Testing Accuracy 0.969,Training Accuracy 0.986291
9 Iter 7,Testing Accuracy 0.9704,Training Accuracy 0.987564
10 Iter 8,Testing Accuracy 0.971,Training Accuracy 0.988618
11 Iter 9,Testing Accuracy 0.9718,Training Accuracy 0.989382
12 Iter 10,Testing Accuracy 0.9727,Training Accuracy 0.990109
13 Iter 11,Testing Accuracy 0.9719,Training Accuracy 0.9908
14 Iter 12,Testing Accuracy 0.9728,Training Accuracy 0.991145
15 Iter 13,Testing Accuracy 0.9732,Training Accuracy 0.991618
16 Iter 14,Testing Accuracy 0.9736,Training Accuracy 0.992055
17 Iter 15,Testing Accuracy 0.9732,Training Accuracy 0.992273
18 Iter 16,Testing Accuracy 0.9736,Training Accuracy 0.992491
19 Iter 17,Testing Accuracy 0.9737,Training Accuracy 0.992709
20 Iter 18,Testing Accuracy 0.9742,Training Accuracy 0.992964
21 Iter 19,Testing Accuracy 0.9741,Training Accuracy 0.993109
22 Iter 20,Testing Accuracy 0.975,Training Accuracy 0.993236
程序中的prediction加了tf.nn.softmax,既然tf.nn.softmax_cross_entropy_with_logits中自动计算softmax,则prediction应更改为prediction=tf.matmul(L2_drop,W3)+b3。
参考的源程序中隐藏层还要多一层,但是跑程序我会很久,所以我把它删了,还把隐藏层的神经元个数改成了1000。
总结:
未使用dropout时,用训练集做测试,准确率相当高(因为你就是用它训练的)。
但用测试集做测试时,准确率降低。过拟合现象。
应用dropout后,二者的准确率相差不大,但模型收敛的速度变慢了。
2019-05-31 16:28:23