CNN的权值正交性和特征正交性,在一定程度上是和特征表达的差异性存在一定联系的。
下面两篇论文,一篇是在训练中对权值添加正交正则提高训练稳定性,一篇是对特征添加正交性的损失抑制过拟合。
第一篇:Orthonormality Regularization
Xie D, Xiong J, Pu S. All You Need is Beyond a Good Init: Exploring Better Solution for Training Extremely Deep Convolutional Neural Networks with Orthonormality and Modulation[J]. 2017.
contributions
作者针对较深较宽网络训练困难(梯度弥散和爆炸),信号在网络传输不够稳定,提出了两点:
1.强调Conv+BN+ReLU这种module在训练中的必要性
2.提出一种权值的(Orthonormality Regularization)正交正则
另附BN层作用
BN能保证输入和输出的分布一致,从而避免出现梯度弥散和梯度爆炸的情况。
使用公式说明:

当w的N次方过小或者过大时,会出现对应的梯度弥散和梯度爆炸。
而经过BN处理后,会生成均值为0,方差为1的高斯分布(假设输入是高斯分布),从而解决了w的尺度所带来的问题。
Orthonormality Regularization
y = WTx,如果||y|| = ||x||,则我们称这种线性变化是保范的,等价条件是W属于正交矩阵,如下式推导:
![]()
即可计算出正交正则,用于替代SGD中的L2 正则:
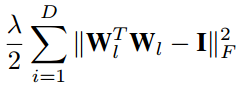
experiments
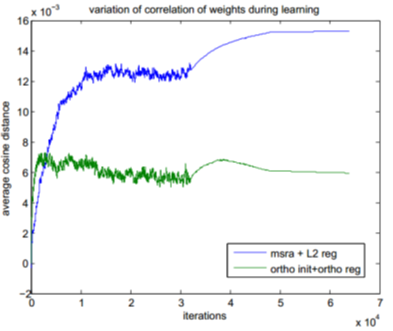
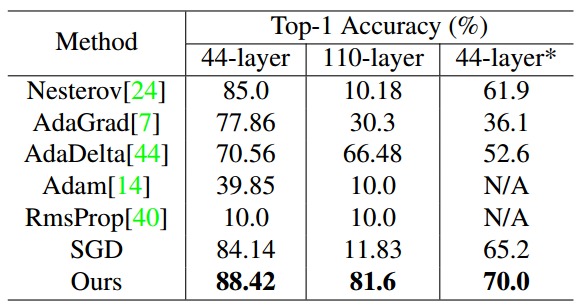
采用44层的残差网络在CIFAR-10数据集上进行训练和测试。两组实验进行对比:
1. 正交初始化+正交正则
2. msra初始化+L2正则
权值非相关性变化过程:
计算网络中各同层卷积核之间的相似度的平均值,作为网络的权值相关系数

最终性能结果:
第二篇:DeCov Loss
Cogswell M, Ahmed F, Girshick R, et al. Reducing Overfitting in Deep Networks by Decorrelating Representations[J]. Computer Science, 2015.
a conference paper at ICLR 2016
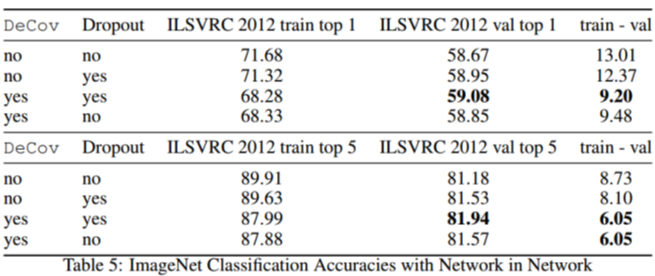
作者发现特征相关性较大时,特征差异小,模型泛化较差。而常用的增强泛化的方法是,提高样本多样性和dropout。
contributions
提出DeCov Loss增强特征的非相关性,提高模型泛化性能
特征相关性和泛化性能关系的讨论
特征相关性,使用特征的协方差矩阵C的Frobenius范数作为指标。 用以下指标描述第i个和第j个激活值的相关性。值越大,相关性越大。
![]()
泛化性能,使用训练准确率和验证准确率的差值作为指标,差值越小说明泛化越好。
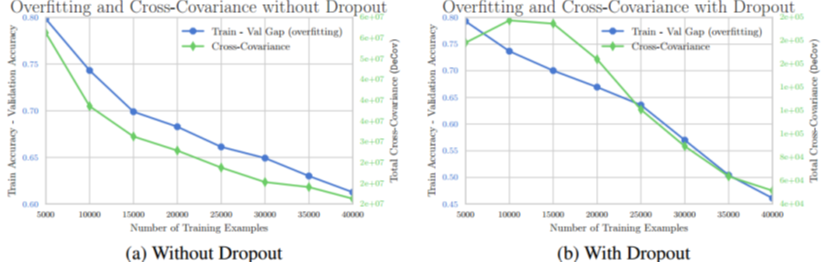
Decov Loss
矩阵的C的Frobenius范数:
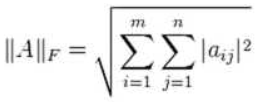
协方差:
反应两组随机变量的相关性,相关系数如下,其中 ,等于0即为完全非相关,等于1为完全相关。
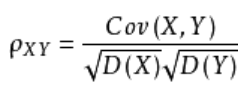
当特征完全非相关的理想情况下,协方差矩阵C是一个对角阵。便有了以下的loss:
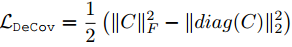
对应的梯度计算是:
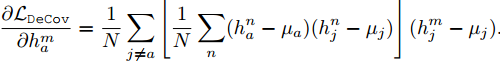
experiments
使用NIN网络,DeCov作用于avg pool层,DeCov Loss和dropout搭配使用泛化性能更好