IO流
IO流概述
IO流用来处理设备之间的数据传输。Java对数据的操作是通过流的方式。Java用于操作流的对象都在IO包中。
流按照流向分为两种:输入流和输出流。
输入流和输出流相对于内存设备而言。将外设中的数据读取到内存中:输入。将内存的数写入到外设中:输出。
流按照操作数据分为两种:字节流和字符流。
字节流读取文字字节数据后,不直接操作而是先查指定的编码表,获取对应的文字。再对这个文字进行操作。简单说:字节流+编码表。
字节流的抽象基类:InputStream,OutputStream。
字符流的抽象基类:Reader,Writer。
由这四个类派生出来的子类名称都是以其父类名作为子类名的后缀。如:InputStream的子类FileInputStream。如:Reader的子类FileReader。
第一节 字符流
字符流最常见的体现形式是文件。
在硬盘上创建一个文件,并写入数据的具体流程如下:
1.创建一个FileWriter对象。该对象一被初始化就必须明确要被操作的文件,该文件会被创建到指定目录下,如果该目录下已经有同名文件,将被覆盖 FileWriter fw=new FileWriter("demo.txt");文件的数据的续写是通过构造函数 FileWriter(Strings,boolean append),在创建对象时,传递一个true参数,代表不覆盖已有的文件。并在已有文件的末尾处进行数据续写。
2.调用write方法,将字符串写入到流中。 fw.write();
3.刷新流对象中的缓冲中的数据,将数据刷到目的地 fw.flush();
4.关闭流资源,但是关闭之前会刷新一次内部的缓冲中的数据,将数据刷到目的地中。和flush的区别,flush刷新后,流可以继续使用,close刷新后 将会将流关闭。 fw.close();close方法只能用一次, 流关闭以后不能再调用write方法,否则会抛出异常。
代码示例:
1 import java.io.*; 2 class FileWriterDemo 3 { 4 public static void main(String[] args) 5 { 6 FileWriter fw=null; 7 try 8 { 9 fw=new FileWriter("demo.txt");//创建文件 10 fw.write("www.itheima.com");//写入数据 11 } 12 catch (IOException e) 13 { 14 e.printStackTrace(); 15 } 16 finally 17 { 18 try 19 { 20 if(fw!=null) 21 fw.close();//将写入流的数据刷到指定文件内,并关闭流资源 22 } 23 catch (IOException e)//对关闭流资源也需要捕获异常。 24 { 25 throw new RuntimeException(); 26 } 27 } 28 } 29 }
文件写入的结果如下图:
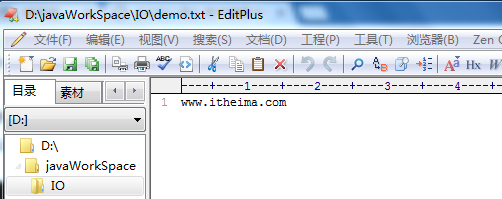
上面代码中有一个重要的IO流的异常处理方式:为防止代码异常导致流无法关闭,因此需要在finally中对流进行关闭。
说完了写入的字符流,接下来就是读取的字符流了。
读取一个文文件,将读取到的字符打印到控制台。(使用FileReader)
1 import java.io.*; 2 class FileReaderDemo 3 { 4 public static void main(String[] args) 5 { 6 //FileReader的两种读取方式 7 8 System.out.println("方式一:"); 9 fun01(); 10 System.out.println(); 11 System.out.println("方式二:"); 12 fun02(); 13 14 } 15 //第一种方式:单个字符读取 16 static void fun01() 17 { 18 FileReader fr=null; 19 try 20 { 21 fr=new FileReader("demo.txt");//创建文件 22 for(int ch=0;(ch=fr.read())!=-1;) 23 { 24 System.out.print((char)ch);//逐个字符的读取数据 25 } 26 } 27 catch (IOException e) 28 { 29 e.printStackTrace(); 30 } 31 finally 32 { 33 try 34 { 35 if(fr!=null) 36 fr.close();//关闭流资源 37 } 38 catch (IOException e)//对关闭流资源也需要捕获异常。 39 { 40 throw new RuntimeException(); 41 } 42 } 43 } 44 //第二种方式:字符数组读取 45 static void fun02() 46 { 47 FileReader fr=null; 48 try 49 { 50 fr=new FileReader("demo.txt");//读取文件位置和文件名 51 char[] cs=new char[1024]; 52 for(int len=0;(len=fr.read(cs))!=-1;) 53 { 54 System.out.print(new String(cs,0,len));//逐个字符的读取数据 55 } 56 } 57 catch (IOException e) 58 { 59 e.printStackTrace(); 60 } 61 finally 62 { 63 try 64 { 65 if(fr!=null) 66 fr.close();//关闭流资源 67 } 68 catch (IOException e)//对关闭流资源也需要捕获异常。 69 { 70 throw new RuntimeException(); 71 } 72 } 73 } 74 }
输出结果为:
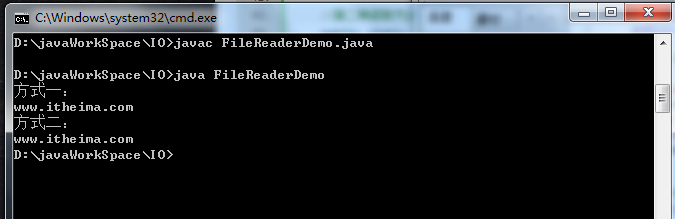
两种方式都能够读取文件,但是第二种方式利用字符数组的效率要高一些。
下面通过一个文件拷贝的小例子来综合练习一下文件字符流的读取和写入。
1 static void fileCopy() 2 { 3 FileReader fr=null; 4 FileWriter fw=null; 5 try 6 { 7 fr=new FileReader("demo.txt");//读取文件位置和文件名 8 fw=new FileWriter("demo_copy.txt");//创建拷贝的文件 9 char[] cs=new char[1024]; 10 for(int len=0;(len=fr.read(cs))!=-1;) 11 { 12 fw.write(cs,0,len);//写入拷贝的文件 13 } 14 System.out.println("写入成功!"); 15 } 16 catch (IOException e) 17 { 18 e.printStackTrace(); 19 } 20 finally 21 { 22 if(fr!=null) 23 { 24 try 25 { 26 27 fr.close();//关闭流资源 28 } 29 catch (IOException e)//对关闭流资源也需要捕获异常。 30 { 31 throw new RuntimeException("关闭读取流异常"); 32 } 33 } 34 if(fw!=null) 35 { 36 try 37 { 38 fw.close();//关闭流资源 39 } 40 catch (IOException e)//对关闭流资源也需要捕获异常。 41 { 42 throw new RuntimeException("关闭写入流异常"); 43 } 44 } 45 }
结果如下:

字符流的缓冲区:BufferedReader和BufferedWriter
字符流缓冲区的出现是为了提高字符流的读取效率。作用:在流的基础上对流的功能进行了增强。对应的类:BufferedReader和BufferedWriter
BUfferWriter步骤:
1.创建一个字符写入流对象 FileWriter fw=new FileWriter("a.txt");
2.将需要被提高效率的流对象作为参数传递给缓冲区的构造函数 bufferedWriter bufw=new BufferedWriter(fw); bufw.write("asdasdas"); bufw.newLine();//换行符,跨平台的
3.将缓冲区刷新 bufw.flush;
4.关闭缓冲区,就是在关闭缓冲区中的流对象 bufw.close();
字符流缓冲区:
写入换行使用BufferedWriter类中的newLine()方法。
读取一行数据使用BufferedReader类中的readLine()方法。
bufr.read():这个read方法是从缓冲区中读取字符数据,所以覆盖了父类中的read方法。
bufr.readLine():另外开辟了一个缓冲区,存储的是原缓冲区一行的数据,不包含换行符。
原理:使用了读取缓冲区的read方法,将读取到的字符进行缓冲并判断换行标记,将标记前的缓冲数据变成字符串返回。
下面通过字符流的缓冲区对象来实现文件的拷贝
1 static void bufferedCopyDemo() 2 { 3 BufferedReader br=null; 4 BufferedWriter bw=null; 5 try 6 { 7 br=new BufferedReader(new FileReader("demo.txt"));//读取文件位置和文件名 8 bw=new BufferedWriter(new FileWriter("demo_copy.txt"));//创建拷贝的文件 9 //char[] cs=new char[1024]; 10 for(String line=null;(line=br.readLine())!=null;) 11 { 12 bw.write(line);//写入拷贝的文件 13 bw.newLine(); 14 bw.flush(); 15 } 16 System.out.println("写入成功!"); 17 } 18 catch (IOException e) 19 { 20 e.printStackTrace(); 21 } 22 finally 23 { 24 if(br!=null) 25 { 26 try 27 { 28 29 br.close();//关闭流资源 30 } 31 catch (IOException e)//对关闭流资源也需要捕获异常。 32 { 33 throw new RuntimeException("关闭读取流异常"); 34 } 35 } 36 if(bw!=null) 37 { 38 try 39 { 40 bw.close();//关闭流资源 41 } 42 catch (IOException e)//对关闭流资源也需要捕获异常。 43 { 44 throw new RuntimeException("关闭写入流异常"); 45 } 46 } 47 } 48 }
输出结果为:
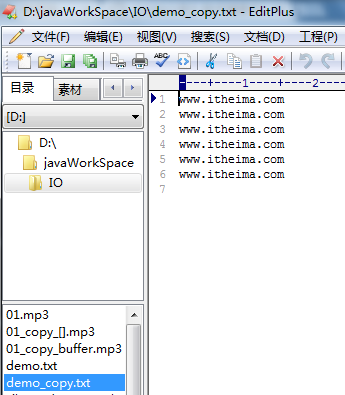
由上面的结果可以看出来多行文本拷贝成功。
LineNumberReader
在BufferedReader中有个直接的子类LineNumberReader,跟踪行号的缓冲字符输入流。其中有特有的方法获取和设置行号。此类定义了方法 setLineNumber(int) 和 getLineNumber(),它们可分别用于设置和获取当前行号。
1 //将读取流对象传入 2 LineNumberReader lnr=new LineNumberReader(new FileReader("LineNumberReaderDemo.java")); 3 lnr.setLineNumber(100);//设置开始行号 4 5 for (String line=null;(line=lnr.readLine())!=null ; ) 6 { 7 System.out.println(lnr.getLineNumber()+":"+line);//打印每行行号和字符 8 }
装饰类设计模式
当想要对已有的类进行功能增强时,可以定义类,将已有的对象传入,基于已经有的功能, 并提供加强功能,那么自定义的该类称为装饰类。
装饰类通常会通过构造方法接收被装饰的对象,并基于被装饰的对象的功能,提供更强的功能。
首先有一个继承体系:
Writer
|--TextWriter:用于操作文本
|--MediaWriter:用于操作媒体
如果想要对操作的动作进行效率的提高,按照面向对象,可以通过继承的方式对具体的对象进行功能的扩展,那么就需要加入缓冲技术。
Writer
|--TextWriter:用于操作文本
|--BufferTextWriter:加入了缓冲技术的操作文本的对象
|--MediaWriter:用于操作媒体
|--BufferMediaWriter:加入了缓冲技术的操作媒体的对象
以上方式并不理想,如果这个体系需要再进行功能扩展,又多了更多流对象。这样就会发现只为提高功能,导致继承体系越来越臃肿,不够灵活。
既然加入的都是同一种技术--缓冲。前一种是让缓冲和自己的流对象相结合。可不可以将缓冲进行单独的封装,哪个对象需要缓冲就将哪个对象和缓冲关联。
Writer
|--TextWriter:用于操作文本
|--MediaWriter:用于操作媒体
|--BufferedWriter:用于提高效率
可见:装饰比继承灵活。特点:装饰类和被装饰类都必须所属同一个接口或者父类。
我们上面介绍的缓冲区字符流就是装饰类设计模式的体现,为了更好的理解装饰类,我们自己实现一下缓冲区字符流。
缓冲区中无非就是封装了一个数组,并对外提供了更多的方法对数组进行访问,其实这些方法最终操作的都是数组的角标。其实就是从源中获取一批数据到缓冲区中,再从缓冲区中不断地取出一个一个数据。在此次取完后,再从源中继续取一批数据进缓冲区,当源中的数据取完时,用-1作为结束标记。
1 import java.io.*; 2 class MyBufferedReader //extends Reader 3 { 4 private int pos;//标示字符位置的指针 5 private int count;//字符总数的计数器 6 private Reader r;//要增强的字符流 7 private char[] buf=new char[1024]; 8 public MyBufferedReader(Reader r) 9 { 10 this.r=r; 11 } 12 13 //从缓冲区中一次读取一个字符 14 public int myRead() throws IOException 15 { 16 17 if(count==0) 18 { 19 count=r.read(buf); 20 pos=0;//重新读取之后脚标归原位。 21 } 22 if(count<0)//文件末尾返回-1; 23 return -1; 24 char result=buf[pos]; 25 pos++; 26 count--; 27 return result; 28 } 29 public String myReadLine() throws IOException 30 { 31 StringBuilder sb=new StringBuilder(); 32 for(int ch=0;(ch=r.read())!=-1;) 33 { 34 if(ch==' ') 35 continue; 36 if(ch==' ') 37 return sb.toString(); 38 sb.append((char)ch); 39 } 40 if(sb.length()!=0) 41 return sb.toString(); 42 return null; 43 } 44 public void myClose()throws IOException 45 { 46 r.close(); 47 } 48 } 49 class MyBufferedReaderDemo 50 { 51 public static void main(String[] args) throws Exception 52 { 53 MyBufferedReader mbr=new MyBufferedReader(new FileReader("demo.txt")); 54 for(String line=null;(line=mbr.myReadLine())!=null;) 55 { 56 System.out.println(line); 57 } 58 mbr.myClose(); 59 } 60 }
运行结果为:

第二节 字节流
1、概述
基本操作与字符流类相同。但它不仅可以操作字符,还可以操作其他媒体文件。
字符流使用的是字符数组char[],字节流使用的是字节数组byte[]。
字节流: InputStream 读 Outputstream 写
字节流对象可直接对媒体文件的数据写入到文件中,而可以不用再进行刷流动作。FileOutputStream、FileInputStream的flush方法内容为空,没有任何实现,调用没有意义。
下面通过一个拷贝MP3文件来练习一下字节流的用法:
1 import java.io.*; 2 class CopyMp3 3 { 4 public static void main(String[] args) throws IOException 5 { 6 copy_Char(); 7 copy_Array(); 8 copy_Available(); 9 } 10 //通过读取单个字节的方式实现拷贝 11 static void copy_Char()throws IOException 12 { 13 FileInputStream fis=new FileInputStream("01.mp3"); 14 FileOutputStream fos=new FileOutputStream("01_Char.mp3"); 15 for(int ch=0;(ch=fis.read())!=-1;) 16 { 17 fos.write(ch); 18 } 19 fis.close(); 20 fos.close(); 21 } 22 23 static void copy_Array()throws IOException 24 { 25 FileInputStream fis=new FileInputStream("01.mp3"); 26 FileOutputStream fos=new FileOutputStream("01_Array.mp3"); 27 byte[] bs=new byte[1024]; 28 for(int len=0;(len=fis.read(bs))!=-1;) 29 { 30 fos.write(bs,0,len); 31 } 32 fis.close(); 33 fos.close(); 34 } 35 36 static void copy_Available()throws IOException 37 { 38 FileInputStream fis=new FileInputStream("01.mp3"); 39 FileOutputStream fos=new FileOutputStream("01_Available.mp3"); 40 byte[] bs=new byte[fis.available()];//利用available方法来指定读取方式中传入数组的长度,当文件过大时,此数组长度所占内存空间就会溢出。所以,此方法慎用,当文件不大时,可以使用。 41 len=fis.read(bs); 42 fos.write(bs); 43 fis.close(); 44 fos.close(); 45 } 46 }
上面的代码中,对异常处理进行了简单的处理直接抛出,在日常写代码的时候需要做完整的异常检查捕获。
2、字节流缓冲区
同样是提高了字节流的读写效率。
读写特点:
read():会将字节byte型值提升为int型值
write():会将int型强转为byte型,即保留二进制数的最后八位。
字节流的读一个字节的read方法为什么返回值类型不是byte,而是int。因为有可能会读到连续8个二进制1的情况,8个二进制1对应的十进制是-1.那么就会数据还没有读完,就结束的情况。因为我们判断读取结束是通过结尾标记-1来确定的。
byte类型的-1提升为int类型时还是-1。原因:因为在bit8个1前面补的全是1导致的。如果在bit8个1前面补0,即可以保留原字节数据不变,又可以避免-1的出现。这时将byte型数据&0xff即255即可。
接下来用字节缓冲区改写一下上面的拷贝MP3的练习
1 static void copy_Array()throws IOException 2 { 3 FileInputStream fis=new FileInputStream("01.mp3"); 4 FileOutputStream fos=new FileOutputStream("01_Array.mp3"); 5 byte[] bs=new byte[1024]; 6 for(int len=0;(len=fis.read(bs))!=-1;) 7 { 8 fos.write(bs,0,len); 9 } 10 fis.close(); 11 fos.close(); 12 }
拷贝的效率明显提高。
标准输入输出流
键盘本身就是一个标准的输入设备。对于java而言,对于这种输入设备都有对应的对象。
System.in:对应的标准输入设备,键盘。
Ssytem.out:对应的是标准的输出设备,控制台。
System.in的类型是InputStream.
System.out的类型是PrintStream是OutputStream的子类FilterOutputStream的子类。
通过System类的setIn,setOut方法可以对默认设备进行改变。
转换流
转换流的由来:字符流与字节流之间的桥梁,方便了字符流与字节流之间的操作。
字节流中的数据都是字符时,转成字符流操作更高效。使用字节流读取一个中文字符需要读取两次,因为一个中文字符由两个字节组成,而使用字符流只需读取一次。
InputStreamReader:字节到字符的桥梁,解码。
OutputStreamWriter:字符到字节的桥梁,编码。
下面用转换流实现将一个文本文件的内容转换成为大写,保存到文件中。
1 import java.io.*; 2 class CastStream 3 { 4 public static void main(String[] args) throws Exception 5 { 6 BufferedReader br=new BufferedReader( 7 new InputStreamReader(new FileInputStream("demo.txt"))); 8 BufferedWriter bw=new BufferedWriter( 9 new OutputStreamWriter(new FileOutputStream("demo_streamCopy.txt"))); 10 for(String line=null;(line=br.readLine())!=null;) 11 { 12 bw.write(line.toUpperCase()); 13 bw.newLine(); 14 bw.flush(); 15 } 16 br.close(); 17 bw.close(); 18 } 19 }
结果为:
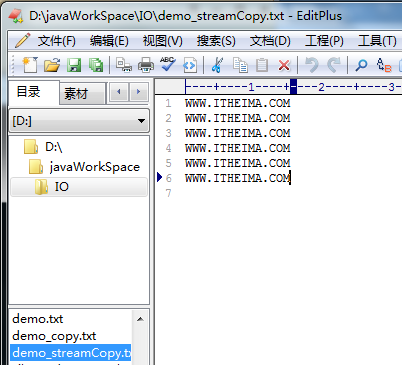
文本中的内容被转换成为了大写。
流的操作规律
之所以要弄清楚这个规律,是因为流对象太多,开发时不知道用哪个对象合适。想要知道对象的开发时用到哪些对象,只要通过四个明确即可。
1、明确源和目的
源:InputStream Reader
目的:OutputStream Writer
2、明确数据是否是纯文本数据
源:是纯文本:Reader 否:InputStream
目的:是纯文本:Writer 否:OutputStream
3、明确具体的设备
源设备:硬盘:File 键盘:System.in 内存:数组 网络:Socket流
目的设备:硬盘:File 控制台:System.out 内存:数组 网络:Socket流
4、是否需要其他额外功能(提高效率)
是,就加上buffer
我们通过一个小例子来巩固一下流对象的使用:
需求1:复制一个文本文件
1、明确源和目的。
源:InputStream Reader
目的:OutputStream Writer
2、是否是纯文本?
是!
源:Reader
目的:Writer
3、明确具体设备。
源:
硬盘:File
目的:
硬盘:File
FileReader fr = new FileReader("a.txt");
FileWriter fw = new FileWriter("b.txt");
4、需要额外功能吗?
需要,高效
BufferedReader bufr = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bufw = new BufferedWriter(new FileWriter("b.txt"));
任何Java识别的字符数据使用的都是Unicode码表,但是FileWriter写入本地文件使用的是本地编码,也就是GBK码表。而OutputStreamWriter可使用指定的编码将要写入流中的字符编码成字节。可以按照指定的字符编码规则写入文件,这是转换流的一个重要应用。
utf-8一个中文占三个字节。
GBK 一个中文占两个字节。
总结来说,转换流的使用场合:
1、源或者目的对应的设备是字节流,但是操作的却是文本数据,可以使用转换作为桥梁,提高对文本操作的便捷。
2、一旦操作文本涉及到具体的指定编码表时,必须使用转换流。
补充知识点:
日常的日志信息和系统信息
使用printStream();将任何数据类型进行原样打印。
输出到控制台:
System.SetOut(new PrintStream("sysinfo.txt"))
e.printStackTrace(System.out);
上面这两句就相当于 e.printStackTrace(new PrintStream("sysinfo.txt"));//将日志文件打印到文件中
获取系统信息:
Properties prop =System.getProperties();
prop.list(System.out);//打印到控制台
prop.list(new PrintStream("sysinfo.txt"));//打印到文件中
最后我们总结一下学习的这么多流对象的继承关系,详细情况如下图所示:


第三节 File类
1、概述
File类用来将文件或者文件夹封装成对象,方便对文件与文件夹的属性信息进行操作。
File对象可以作为参数传递给流的构造函数。流只能操作数据,不能操作文件。
创建File对象,
1.File f=new File("c:\abca.txt");//将a.txt封装成FIle对象,可以将已有的和未出现的文件或者文件夹封装成对象。
2.File f=new File("c:\abc","a.txt"); 第一个参数代表的是目录,第二个参数代表的是目录下的文件。
3.File d=new File("c\abc"); 将路径封装成对象
File f=new File(d,"a.txt"); 调用路径对象
目录分隔符:\,这是在windows下的分隔符,在别的操作系统中就不是了, File.separator表示目录分隔符,可以跨平台使用。相当于路径中的“”(双斜杠\在windows中表示表示转义后的分隔符。在 UNIX 系统上,此字段的值为 '/';
2、File类的常见方法
1.创建
boolean createNewFile():在指定位置创建文件,如果该文件已经存在,则不创建,返回false 和写入流不一样,写入流创建文件会覆盖已经存在的文件。
案例 :
File f=new File("a.txt");
f.createNewFile();
创建一级目录 File dir=new File("abc");
dir.mkdir();
创建多级目录 dir.mkdirs();
2.删除
boolean f.delete(); 删除失败,返回false,可能不能删除
void deleteOnExit();在程序退出时,删除指定文件。必须删除。不会失败
3.判断 :在判断文件对象是都是文件或者目的时候,必须要先判断该文件对象封装的内容是否存在。
File f=new File("a.txt");
f.canExecute();是否能执行。
f.exits();返回boolean 文件是否存在
是否是目录 f.isDirectory();
是否是文件 f.isFile();
是否是隐藏的 f.isHidden();
是否是绝对路径 f.isAbsolute();
4.获取信息。
getName() //获取名称
getpath() //获取路径
getAbsolutePath() //获取绝对路径
getParent() //获取绝对路径下的父路径,如果获取的是相对路径返回null,如果相对路径中由上一级目录,该目录就是结果。
lastModified()//获取最后一次修改时间 length();//获取体积大小
5.其他
renameTo();改名,重命名,如果修改路径的话,同时路径也会修改 f1.renameTo(f2);
listRoots();返回 File 数组,列出可用的文件系统根(盘符)
list():返回当前目录下所有文件,包括子目录
listFiles();返回当前路径下的文件对象。(不包括子目录)
list方法可以指定筛选器,用来选取符合特定条件的内容。
1 import java.io.*; 2 class MyFilter implements FilenameFilter 3 { 4 private String content; 5 MyFilter(String content) 6 { 7 this.content=content; 8 } 9 public boolean accept(File dir,String name) 10 { 11 return name.endsWith(content); 12 } 13 } 14 class FileListDemo 15 { 16 public static void main(String[] args) 17 { 18 File dir=new File("D:\javaWorkSpace\IO"); 19 String[] names=dir.list(new MyFilter(".java")); 20 for(String name:names) 21 { 22 System.out.println(name); 23 } 24 25 } 26 }
结果为:
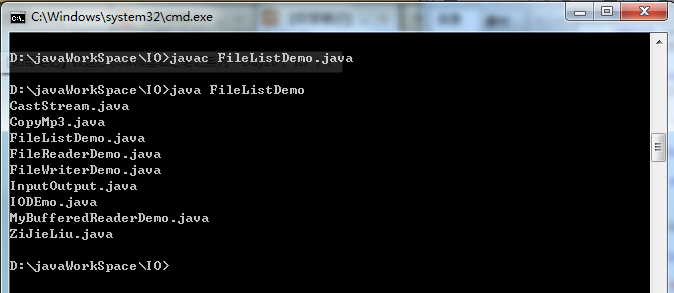
如上图,指定目录下所有的以java结尾的文件名都打印出来了。
listFile方法也可以指定文件名筛选器。如我们获取C盘下所有隐藏文件,代码如下:
1 class FilterByHidden implements FilenameFilter 2 { 3 public boolean accept(File dir,String name) 4 { 5 return dir.isHidden(); 6 } 7 } 8 class FileListDemo 9 { 10 public static void main(String[] args) 11 { 12 File f=new File("c:\"); 13 File[] files=f.listFiles(new FilterByHidden()); 14 for(File file:files) 15 { 16 System.out.println(file); 17 } 18 19 } 20 }
结果为:

3、递归
递归是指函数自身直接或者间接的调用到了自身。
一个功能在被重复使用,并每次使用时,参与运算的结果和上一次调用有关。这时可以用递归来解决问题。
1、递归一定明确条件。否则递归不会结束,会陷入无限循环。
2、注意一下递归的次数。尽量避免内存溢出。因为每次调用自身的时候都会先执行下一次调用自己的方法,所以会不断在栈内存中开辟新空间,次数过多,会导致内存溢出。
下面通过几个简单练习理解一下递归:
1 class Digui 2 { 3 public static void main(String[] args) 4 { 5 toBin(60); 6 7 System.out.println(sum(100)); 8 } 9 //1、整数转换成为二进制 10 static void toBin(int num) 11 { 12 if(num>0)//明确递归条件 13 { 14 toBin(num/2); 15 System.out.print(num%2);//明确打印顺序 16 } 17 } 18 //2、利用递归求1-100的和 19 static int sum(int num) 20 { 21 if(num==1)//明确递归结束的条件, 22 return 1; 23 return (num+sum(--num));//递归调用 24 } 25 }
结果为:

接下来我们应用递归完成复杂一点的功能,实现文件目录的递归删除。必须从里面往外删,需要进行深度遍历。
1 import java.io.*; 2 class Digui 3 { 4 public static void main(String[] args) 5 { 6 diGuiDelete(new File("D:\javaWorkSpace\deleteTest")); 7 } 8 static void diGuiDelete(File f) 9 { 10 File[] files=f.listFiles(); 11 for(File file:files) 12 { 13 if(file.isDirectory()) 14 { 15 diGuiDelete(file); 16 } 17 else 18 { 19 System.out.println(file+": 删除"+file.delete()); 20 } 21 } 22 System.out.println(f+": 删除"+f.delete()); 23 } 24 }

最后一行可以看出递归删除最后删除文件夹完成。
第四节 Properties类
Properties类是hashtable的子类,具备map集合的特点,里面存储的键值对都是字符串。当文件流和键值对相结合就用此集合。
Properties是集合中和IO技术相结合的集合容器。
对象的特点:可以用于键值对形式的配置文件,可以操作键盘的数据。Properties的方法如下:
prop.setProperty("张三","30");//添加,修改
prop.getProperty("键");//获取
一般Properties可以用来操作配置文件:
1 import java.io.*; 2 import java.util.*; 3 class MyProperties 4 { 5 public static void main(String[] args) throws Exception 6 { 7 Properties prop =new Properties(); 8 FileInputStream fis=new FileInputStream("a.txt"); 9 //将流中的数据加载进集合 10 prop.load(fis); 11 prop.list(System.out); 12 13 prop.setProperty("hao123","hao123"); 14 FileOutputStream fos=new FileOutputStream("b.txt"); 15 prop.store(fos,""); 16 17 fis.close(); 18 fos.close(); 19 } 20 }
结果为:


hao123=hao123也已经写入了b.txt的配置文件了。
5、IO包中的其他流
1、打印流
PrintWriter与PrintStream:可以直接操作输入流和文件。PrintStream为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。与其他输出流不同,PrintStream永远不会抛出IOException。PrintStream打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用PrintWriter类。
字节打印流:PrintStream
构造方法中可接收的参数类型:
1、File对象。File
2、字符串路径:String
3、字符输出流:OutputStream
字符打印流:PrintWriter
构造方法中可接受的参数类型
1、File对象:File
2、字符串路径:String
3、字节输出流:OutputStream
4、字符输出流:Writer
PrintWriter 构造函数的第二个参数设置为 true ,表示自动刷新
接下来就用打印流来做个小练习,用打印流将用户在控制台的输入,转换为大写然后输入到指定文件中
1 import java.io.*; 2 import java.util.*; 3 class MyPrintStream 4 { 5 public static void main(String[] args) throws Exception 6 { 7 inToFile(); 8 } 9 static void inToFile() throws Exception 10 { 11 File f=new File("in.txt"); 12 if(!f.exists()) 13 { 14 f.createNewFile(); 15 } 16 BufferedReader br=new BufferedReader( 17 new InputStreamReader(System.in)); 18 PrintWriter pw=new PrintWriter(f); 19 for(String line=null;(line=br.readLine())!=null;) 20 { 21 if(line.equals("over")) 22 break; 23 pw.println(line.toUpperCase()); 24 } 25 br.close(); 26 pw.close(); 27 } 28 }
结果为:


2、合并流(序列流)
SeaquenceInputStream 对多个流进行合并。
构造函数有:
SequenceInputStream(Enumeration<? extends InputStream> e)
对于没有实现枚举的集合,可以通过Collections的静态方法,enumeration来获的,public static <T> Enumeration<T> enumeration(Collection<T> c)
SequenceInputStream(InputStream s1, InputStream s2)
这种构造函数只适合两个输入流的情况。
下面用一个小例子来说明合并流的用法:
1 import java.io.*; 2 import java.util.*; 3 class MySequenceInputStream 4 { 5 public static void main(String[] args) throws Exception 6 { 7 sisDemo(); 8 } 9 static void sisDemo()throws Exception 10 { 11 ArrayList<FileInputStream> al=new ArrayList<FileInputStream>(); 12 for(int i=1;i<4;i++) 13 { 14 al.add(new FileInputStream(i+".txt")); 15 } 16 Enumeration<FileInputStream> en=Collections.enumeration(al);//通过集合工具集获取枚举对象 17 SequenceInputStream sis=new SequenceInputStream(en); 18 FileOutputStream fos=new FileOutputStream("4.txt");//创建结果的输出流对象 19 byte[] buf=new byte[1024]; 20 for(int len=0;(len=sis.read(buf))!=-1;)//通过合并流读取。 21 { 22 fos.write(buf,0,len); 23 } 24 fos.close(); 25 sis.close(); 26 } 27 }
结果为:
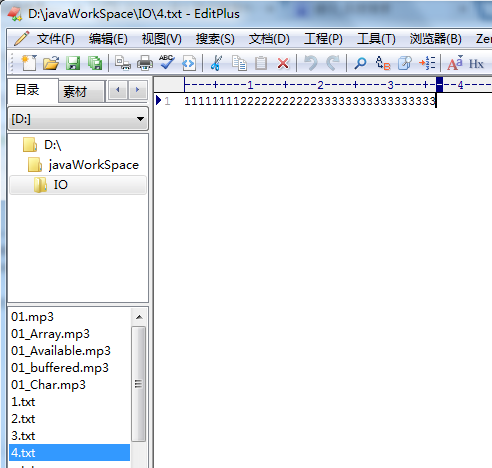
3、ObjectInputStream与ObjectOutputStream对象序列化流
Java中ObjectInputStream 与 ObjectOutputStream这两个包装类可用于输入流中读取对象类数据和将对象类型的数据写入到底层输入流 。ObjectInputStream 与 ObjectOutputStream 类所读写的对象必须实现了 Serializable 接口。需要注意的是:对象中的 transient 和 static 类型的成员变量不会被读取和写入 。
类通过实现java.io.Serializable接口以启用序列化功能,Serializable只是一个标记接口。
SerialVersionUID用于给被序列化的类加入ID号,用于判断类和对象是否是同一个版本。为序列化类添加序列号属性。此时,类中属性修饰符修改,也不会出现任何异常。