索引的出现是为了提高查询效率,实现索引的方式(索引模型)有很多种。
每种数据结构都有其自身的优势和劣势,但它们存在的⽬的都是在不同的应⽤场景,尽可能高效增删改查。MySQL之所以用B+树作为索引,并不能说明B+树就是最好的数据结构,只能说是目前最合适的数据结构。
为什么不用哈希表、有序数组和搜索树这三种索引模型?
(1)哈希表中对象的存储位置是随机的,好处是插入新值时速度会很快,只需要往后追加。但缺点是,因为不是有序的,所以哈希索引做区间查询的速度是很慢的。哈希表这种结构适用于只有等值查询的场景,比如Memcached及其他一些NoSQL引擎。
(2)有序数组在等值查询和范围查询场景中的性能就都非常优秀,查询的时候用二分法就可以快速得到,这个时间复杂度是O(log(N))。但是,在需要插入数据的时候就麻烦了,你往中间插入一个记录就必须得挪动后面所有的记录,成本太高。所以,有序数组索引只适用于静态存储引擎,比如你要保存的是2021年某个城市的所有人口信息,这类不会再修改的数据。
(3)二叉搜索树的特点是:每个节点的左儿子小于父节点,父节点又小于右儿子。查询的时间复杂度是O(log(N))。当然为了维持O(log(N))的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是O(log(N))。二叉树是搜索效率最高的,但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上。为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。那么,我们就不应该使用二叉树,而是要使用“N叉”树。
B 树
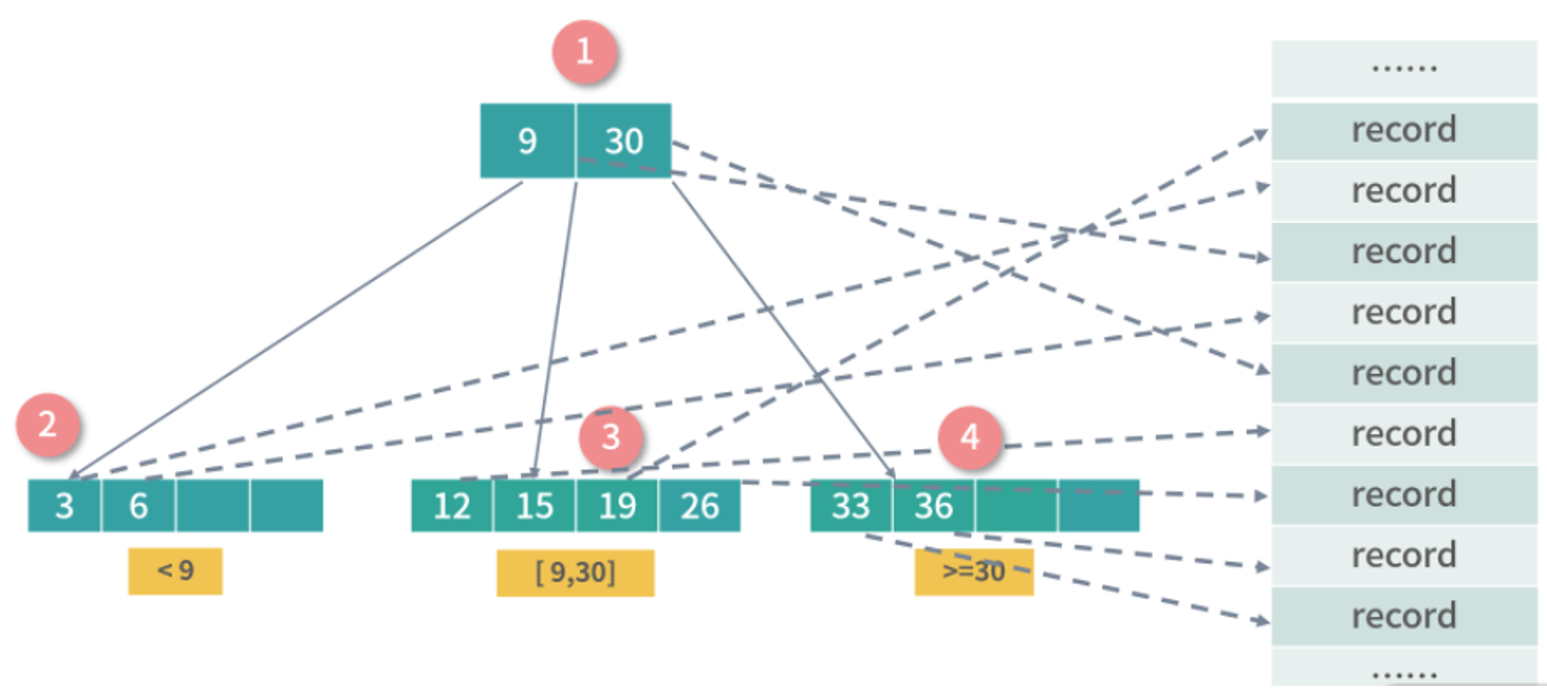
B-Tree 是一种递归的搜索结构,与二叉搜索树非常类似。不同的是,B 树中的父节点中的数据会对子树进行区段分割。比如上图中节点 1 有 3 个子节点,并用数字 9,30 对子树的区间进行了划分。
上图中的 B 树是一个 3-4 B 树,3 指的是每个非叶子节点允许最大 3 个索引,4 指的是每个节点最多允许 4 个子节点,4 也指每个叶子节点可以存 4 个索引。上面只是一个例子,在实际的操作中,子节点有几十个、甚至上百个索引也很常见,因为我们希望树变矮,好减少磁盘操作。B 树的每个节点是一个索引条目(例如:一个 <订单 ID,序号> 的组合),如果是行数据库可以索引到一条存储在磁盘上的记录。
B+ 树
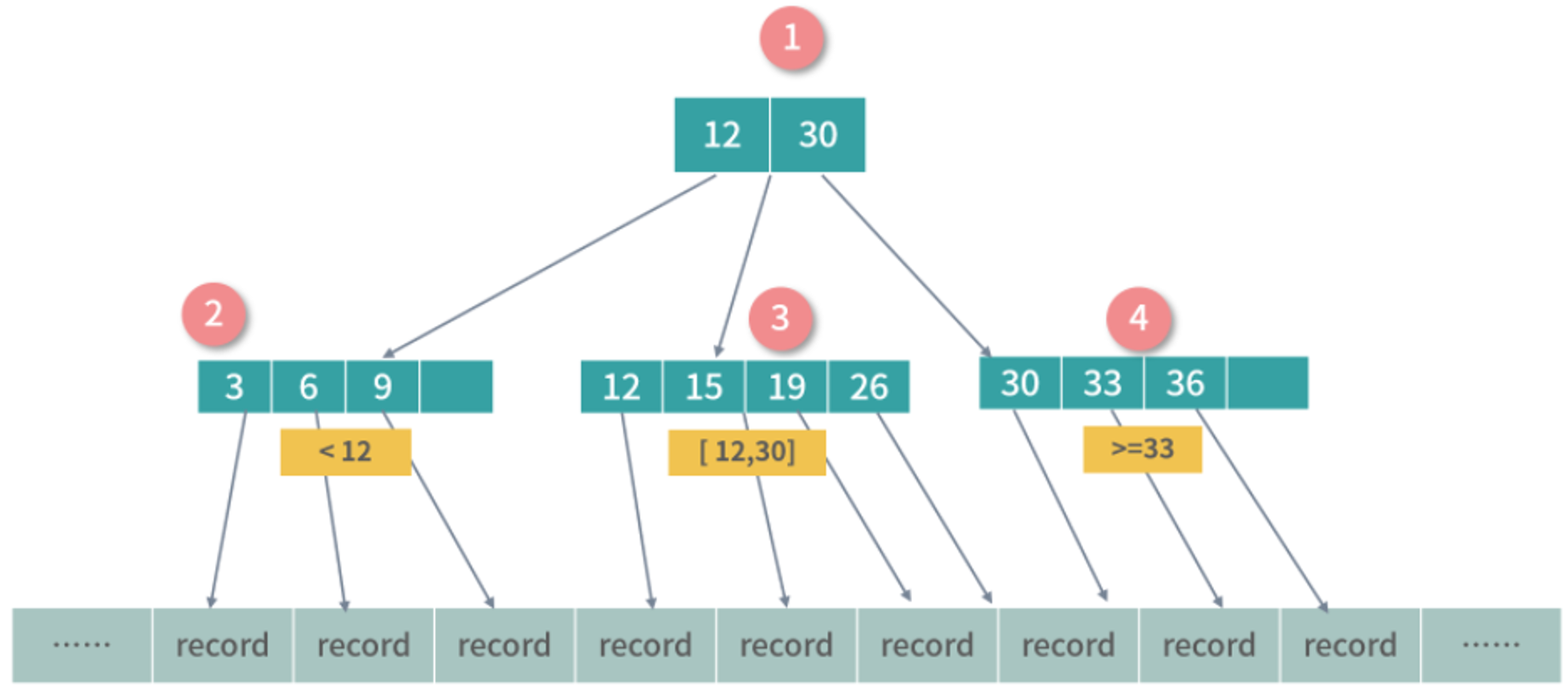
为了达到最高的效率,实战中我们往往使用的是一种继承于 B 树设计的结构,称为 B+ 树。B+ 树只有叶子节点才映射数据,下图中是对 B 树设计的一种改进,节点 1 为冗余节点,它不存储数据,只划定子树数据的范围。你可以看到节点 1 的索引 Key:12 和 30,在节点 3 和 4 中也有一份。
B+树与B树的区别?
简洁回答
(1)B树所有节点都可以映射数据,B+ 树只有叶子节点可以映射数据。
(2)B+ 树用一条链表串联所有的叶子节点。
详细回答
B+ 树继承于 B 树,都限定了节点中数据数目和子节点的数目。B 树所有节点都可以映射数据,B+ 树只有叶子节点可以映射数据。单独看这部分设计,看不出 B+ 树的优势。为了只有叶子节点可以映射数据,B+ 树创造了很多冗余的索引(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,而且可以自动平衡,因此 B+ 树的所有叶子节点总是在一个层级上。所以 B+ 树可以用一条链表串联所有的叶子节点,也就是索引数据,这让 B+ 树的范围查找和聚合运算更快。
插入和删除效率
B+ 树有大量的冗余节点,比如删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点。这样删除非常快。B 树则不同,B 树没有冗余节点,删除节点的时候非常复杂。比如删除根节点中的数据,可能涉及复杂的树的变形。
B+ 树的插入也是一样,有冗余节点,插入可能存在节点的拆分(如果节点饱和),但是最多只涉及树的一条路径。而且 B+ 树会自动平衡,不需要更多复杂的算法,类似红黑树的旋转操作等。
因此,B+ 树的插入和删除效率更高。
链表的作用
B 树和 B+ 树搜索原理基本一致。先从根节点查找,然后对比目标数据的范围,最后递归的进入子节点查找。你可能会注意到,B+ 树所有叶子节点间还有一个链表进行连接。这种设计对范围查找非常有帮助,比如说我们想知道 1 月 20 日和 1 月 22 日之间的订单,这个时候可以先查找到 1 月 20 日所在的叶子节点,然后利用链表向右遍历,直到找到 1 月22 日的节点。这样我们就进一步节省搜索需要的时间。
知识扩展
行存储和列存储
数据库的存储方式—行存储和列存储,索引就是建立在行存储、列存储的基础上。相关知识请查阅
—— https://www.cnblogs.com/liaowenhui/p/14774074.html
Select like %a 为什么会索引失效?
使用通配符开头, %表示全匹配,索引在查询的时候无法定位,使用通配符结尾的时候,在B+Tree的叶子节点中是可以筛选出部分数据的.