开始之前,先出一道题:


1 #super函数探讨 2 class A(object): 3 def __init__(self): 4 print 'A.__init__' 5 6 class B(A): 7 def __init__(self): 8 super(B, self).__init__() 9 print 'B.__init__' 10 11 class C(A): 12 def __init__(self): 13 super(C, self).__init__() 14 print 'C.__init__' 15 16 class D(B, C): 17 def __init__(self): 18 super(D, self).__init__() 19 print 'D.__init__' 20 21 d = D()
上面的运行结果是什么?
是下面的结果吗?
A.__init__ B.__init__ D.__init__
正确答案:
A.__init__ C.__init__ B.__init__ D.__init__
有没有疑惑?super()函数不是调用指定类的父类的方法吗!打印了A.__init__下一句为什么是C.__init__呢?
根本原因是:
super 和父类没有实质性的关联
首先,我们知道新式类采用广度优先算法,我们来看一下上面的继承关系:
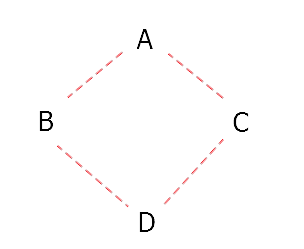
那么,Python是如何实现继承的,继承顺序又是由谁决定的呢? 对于你定义的每一个类而已,Python会计算出一个所谓的方法解析顺序(MRO Method Resolution Order)列表。类的继承顺序就是由这个MRO决定的。
MRO通过class.__mro__来查看,我们来打印一下上面例子中的MRO:
print D.__mro__
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <type 'object'>)
注意__mro__是类的属性,实例没有该属性
这个MRO列表就是一个简单的所有基类的线性顺序表。为了实现继承,Python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。 它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1)子类会先于父类被检查
2)多个父类会根据它们在列表中的顺序被检查
3)如果对下一个类存在两个合法的选择,选择第一个父类
好像还是没明白为什么例子中,打印了A.__init__下一句为什么是C.__init__呢?
我们使用一个函数来解释一下super的原理:
def super(cls, inst): mro = inst.__class__.mro() return mro[mro.index(cls) + 1]
其中,cls 代表类,inst 代表实例,上面的代码做了两件事:
1)获取 inst 的 MRO 列表
2)查找 cls 在当前 MRO 列表中的 index, 并返回它的下一个类,即 mro[index + 1]
当你使用 super(cls, inst) 时,Python 会在 inst 的 MRO 列表上搜索 cls 的下一个类。
是不是有一种豁然开朗的赶脚!让我们回到例子中,这里我画出了整个流程;
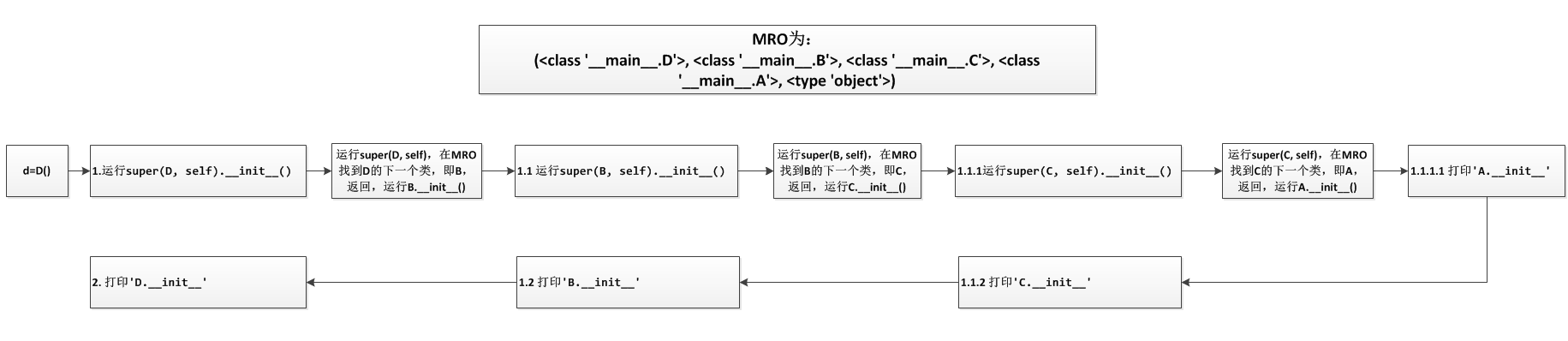
从上面的流程图就可以看出打印的顺序是对的!
了解了super的原理,那么也就可以理解下面这段有趣的代码了:
1)执行下面代码
1 class A(object): 2 def go(self): 3 print 'A go' 4 super(A, self).go() 5 6 a = A() 7 a.go()
会报错:
AttributeError: 'super' object has no attribute 'go'
2)执行下面代码:
1 class A(object): 2 def go(self): 3 print 'A go' 4 super(A, self).go() 5 6 class B(object): 7 def go(self): 8 print 'B go' 9 10 class C(A, B): 11 pass 12 13 c = C() 14 c.go()
不会报错,结果为:
A go
B go
充分说明了super 和父类没有实质性的关联
另外,我们想出了super以外,还有一种直接调用父类方法的方法,如下:
1 #super函数探讨 2 class A(object): 3 def __init__(self): 4 print 'A.__init__' 5 6 class B(A): 7 def __init__(self): 8 # super(B, self).__init__() 9 A.__init__(self) 10 print 'B.__init__' 11 12 class C(A): 13 def __init__(self): 14 # super(C, self).__init__() 15 A.__init__(self) 16 print 'C.__init__' 17 18 class D(B, C): 19 def __init__(self): 20 # super(D, self).__init__() 21 B.__init__(self) 22 C.__init__(self) 23 print 'D.__init__' 24 25 d = D()
为什么不用这种方法呢?我们运行一下,看一下,结果为:
A.__init__ B.__init__ A.__init__ C.__init__ D.__init__
很明显,A的构造函数运行了两次,这不是我们所希望的;所以还是用super吧!