改写原因:在这个模块中的 get_benchmark_returns() 方法回去谷歌财经下载对应SPY(类似于上证指数)的数据,但是Google上下载的数据在最后写入Io操作的时候会报一个恶心的编码的错误,很烦人,时好时坏的那种,就是图下这种报错。
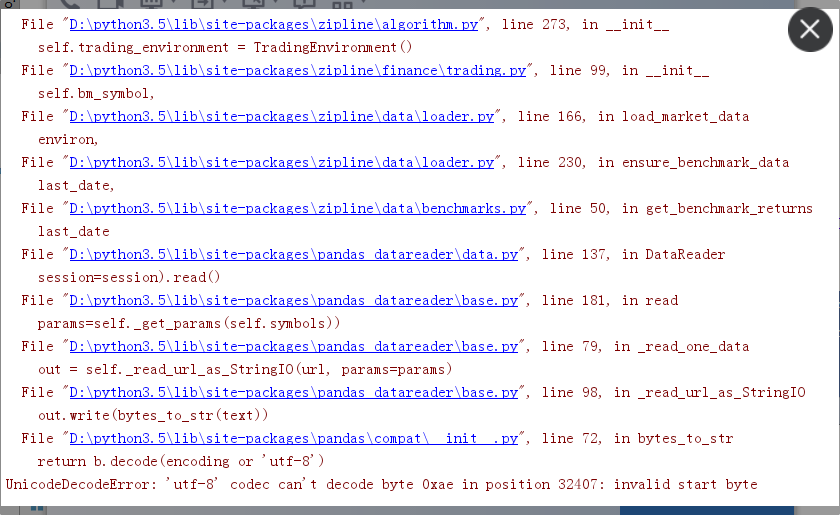
改写方式:
1.首先去雅虎财经下载SPY.csv文件,然后把这个文件放到你对应的目录下
2.具体代码如下
#
# Copyright 2013 Quantopian, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
import pandas as pd
import pytz
from datetime import datetime
import pandas_datareader.data as pd_reader
def get_benchmark_returns(symbol, first_date, last_date):
"""
Get a Series of benchmark returns from Google associated with `symbol`.
Default is `SPY`.
Parameters
----------
symbol : str
Benchmark symbol for which we're getting the returns.
first_date : pd.Timestamp
First date for which we want to get data.
last_date : pd.Timestamp
Last date for which we want to get data.
The furthest date that Google goes back to is 1993-02-01. It has missing
data for 2008-12-15, 2009-08-11, and 2012-02-02, so we add data for the
dates for which Google is missing data.
We're also limited to 4000 days worth of data per request. If we make a
request for data that extends past 4000 trading days, we'll still only
receive 4000 days of data.
first_date is **not** included because we need the close from day N - 1 to
compute the returns for day N.
"""
# 源码
# data = pd_reader.DataReader(
# symbol,
# 'google',
# first_date,
# last_date
# )
#
# data = data['Close']
#
# data[pd.Timestamp('2008-12-15')] = np.nan
# data[pd.Timestamp('2009-08-11')] = np.nan
# data[pd.Timestamp('2012-02-02')] = np.nan
#
# data = data.fillna(method='ffill')
# return data.sort_index().tz_localize('UTC').pct_change(1).iloc[1:]
# 自己写的代码
# parse = lambda x: pytz.utc.localize(datetime.strptime(x, '%Y-%m-%d'))
# data = pd.read_csv("SPY.csv", parse_dates=['Date'], index_col=0, date_parser=parse)
# data = data['Close']
# data = data.fillna(method='ffill')
# return data.sort_index().pct_change(1).iloc[0:]
总结:
1.这次报错后,我习惯性的找到最底层也就是最后两行错误,但是只能知道是编码的错误,但是解决不了。所以以后碰到类似的第三方包的错误,不要急着从最底层开始改,应该适当的想想,我在最开始出错的地方可不可以成功的避免掉,这也是一种思路。
2.Google财经的SPY数据不全,所以他在这个方法中定义了三列是因为这三天的数据他没有。