函数:
聚合每个类别的总价;
val spark = SparkSession.builder() .appName("window") .master("local[6]") .getOrCreate() import spark.implicits._ val source = Seq( ("Thin", "Cell phone", 6000), ("Normal", "Tablet", 1500), ("Mini", "Tablet", 5500), ("Ultra thin", "Cell phone", 5000), ("Very thin", "Cell phone", 6000), ("Big", "Tablet", 2500), ("Bendable", "Cell phone", 3000), ("Foldable", "Cell phone", 3000), ("Pro", "Tablet", 4500), ("Pro2", "Tablet", 6500) ).toDF("product", "category", "revenue") // 需求一: 聚合每个类别的总价 // 1. 分组, 2. 对每一组的数据进行聚合 import org.apache.spark.sql.functions._ source.groupBy('category) .agg(sum('revenue)) .show()

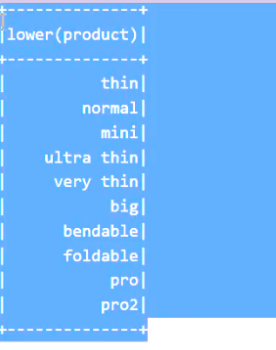
把名称变成小写:
val spark = SparkSession.builder() .appName("window") .master("local[6]") .getOrCreate() import spark.implicits._ val source = Seq( ("Thin", "Cell phone", 6000), ("Normal", "Tablet", 1500), ("Mini", "Tablet", 5500), ("Ultra thin", "Cell phone", 5000), ("Very thin", "Cell phone", 6000), ("Big", "Tablet", 2500), ("Bendable", "Cell phone", 3000), ("Foldable", "Cell phone", 3000), ("Pro", "Tablet", 4500), ("Pro2", "Tablet", 6500) ).toDF("product", "category", "revenue") // 需求一: 聚合每个类别的总价 // 1. 分组, 2. 对每一组的数据进行聚合 import org.apache.spark.sql.functions._ // source.groupBy('category) // .agg(sum('revenue)) // .show() // 需求二: 把名称变为小写 source.select(lower('product)) .show()
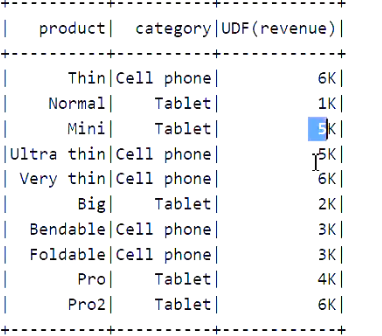
把价格变为字符串形式:
val spark = SparkSession.builder() .appName("window") .master("local[6]") .getOrCreate() import spark.implicits._ val source = Seq( ("Thin", "Cell phone", 6000), ("Normal", "Tablet", 1500), ("Mini", "Tablet", 5500), ("Ultra thin", "Cell phone", 5000), ("Very thin", "Cell phone", 6000), ("Big", "Tablet", 2500), ("Bendable", "Cell phone", 3000), ("Foldable", "Cell phone", 3000), ("Pro", "Tablet", 4500), ("Pro2", "Tablet", 6500) ).toDF("product", "category", "revenue") // 需求一: 聚合每个类别的总价 // 1. 分组, 2. 对每一组的数据进行聚合 import org.apache.spark.sql.functions._ // source.groupBy('category) // .agg(sum('revenue)) // .show() // 需求二: 把名称变为小写 // source.select(lower('product)) // .show() // 需求三: 把价格变为字符串形式 // 6000 6K val toStrUDF = udf(toStr _)//帮助我们作用在每一条元素
source.select('product, 'category, toStrUDF('revenue)) .show() }
定义窗口进行操作:(不同产品的前二)
val spark = SparkSession.builder() .appName("window") .master("local[6]") .getOrCreate() import spark.implicits._ val source = Seq( ("Thin", "Cell phone", 6000), ("Normal", "Tablet", 1500), ("Mini", "Tablet", 5500), ("Ultra thin", "Cell phone", 5000), ("Very thin", "Cell phone", 6000), ("Big", "Tablet", 2500), ("Bendable", "Cell phone", 3000), ("Foldable", "Cell phone", 3000), ("Pro", "Tablet", 4500), ("Pro2", "Tablet", 6500) ).toDF("product", "category", "revenue") // // 1. 定义窗口 val window = Window.partitionBy('category)//分组 .orderBy('revenue.desc)
//定义窗口之后就能用source了
// 2. 数据处理
import org.apache.spark.sql.functions._
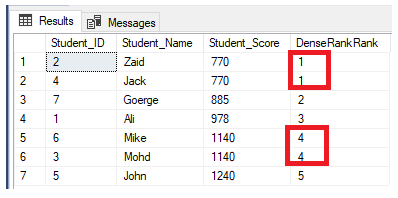
source.select('product, 'category, dense_rank() over window as "rank")
.where('rank <= 2)
.show()

方法二:
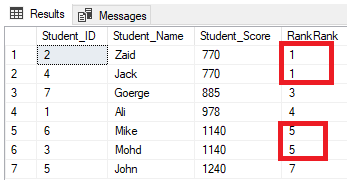
def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("window") .master("local[6]") .getOrCreate() import spark.implicits._ val source = Seq( ("Thin", "Cell phone", 6000), ("Normal", "Tablet", 1500), ("Mini", "Tablet", 5500), ("Ultra thin", "Cell phone", 5000), ("Very thin", "Cell phone", 6000), ("Big", "Tablet", 2500), ("Bendable", "Cell phone", 3000), ("Foldable", "Cell phone", 3000), ("Pro", "Tablet", 4500), ("Pro2", "Tablet", 6500) ).toDF("product", "category", "revenue") // // 1. 定义窗口 // val window = Window.partitionBy('category)//分组 // .orderBy('revenue.desc) // //定义窗口之后就能用source了 // // 2. 数据处理 // import org.apache.spark.sql.functions._ // source.select('product, 'category, dense_rank() over window as "rank") // .where('rank <= 2) // .show() source.createOrReplaceTempView("productRevenue") spark.sql("select product, category, revenue from " + "(select *, dense_rank() over (partition by category order by revenue desc) as rank from productRevenue) " + "where rank <= 2") .show() }

窗口函数的逻辑
- 从 逻辑 上来讲, 窗口函数执行步骤大致可以分为如下几步
-
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank-
根据
PARTITION BY category, 对数据进行分组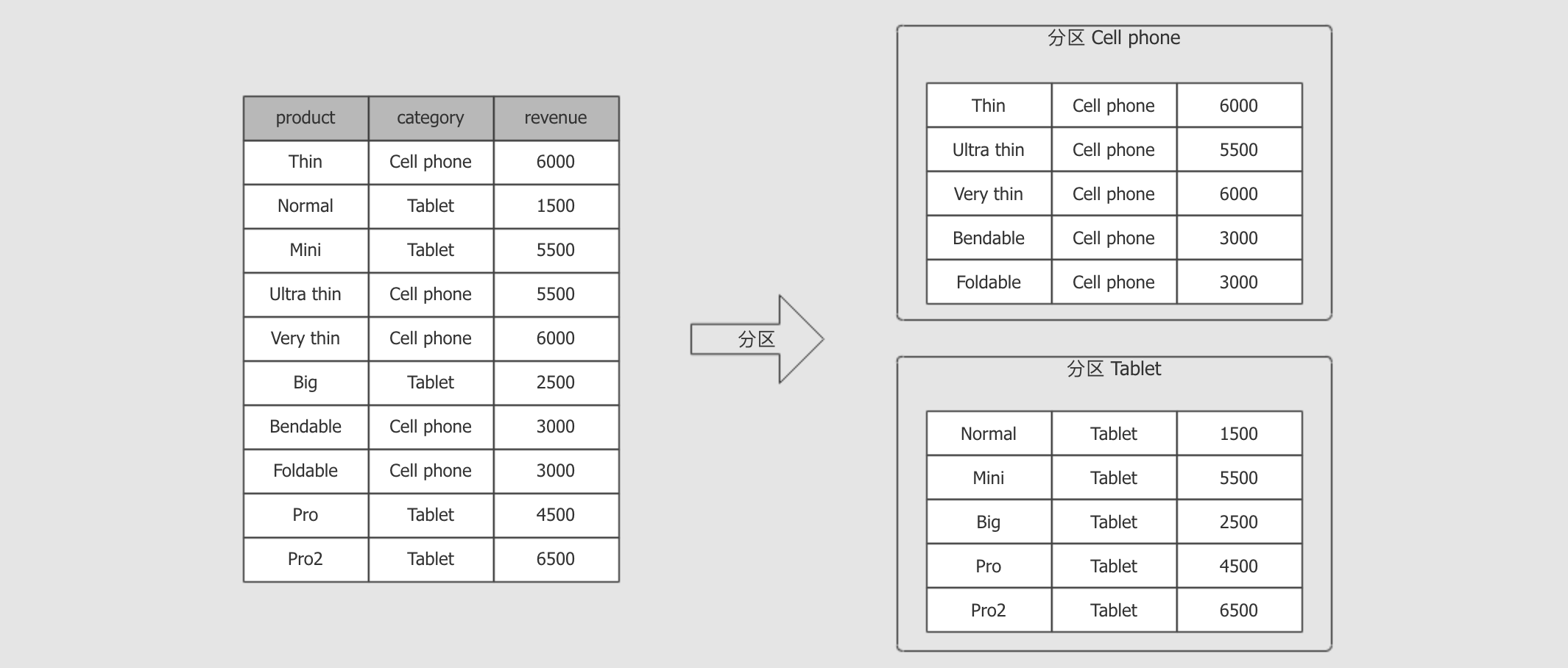
-
分组后, 根据
ORDER BY revenue DESC对每一组数据进行排序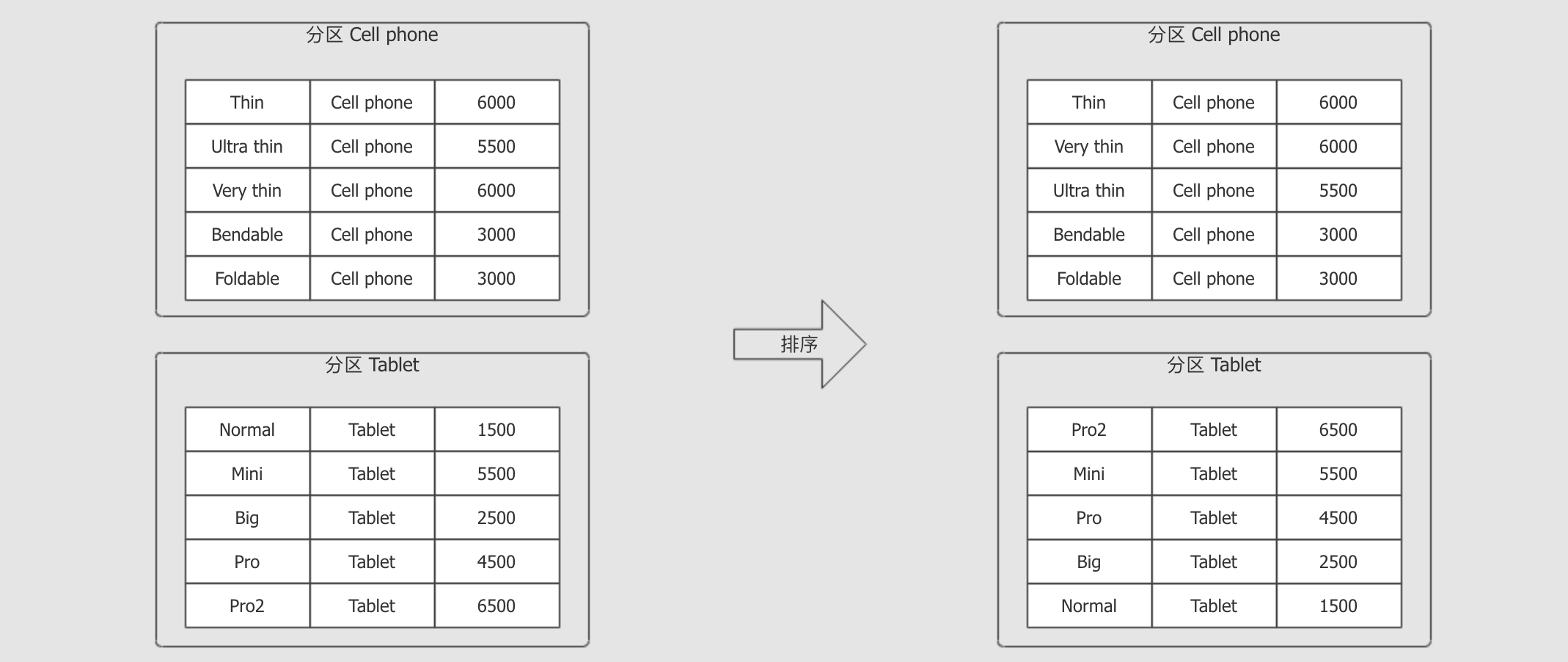
-
在 每一条数据 到达窗口函数时, 套入窗口内进行计算
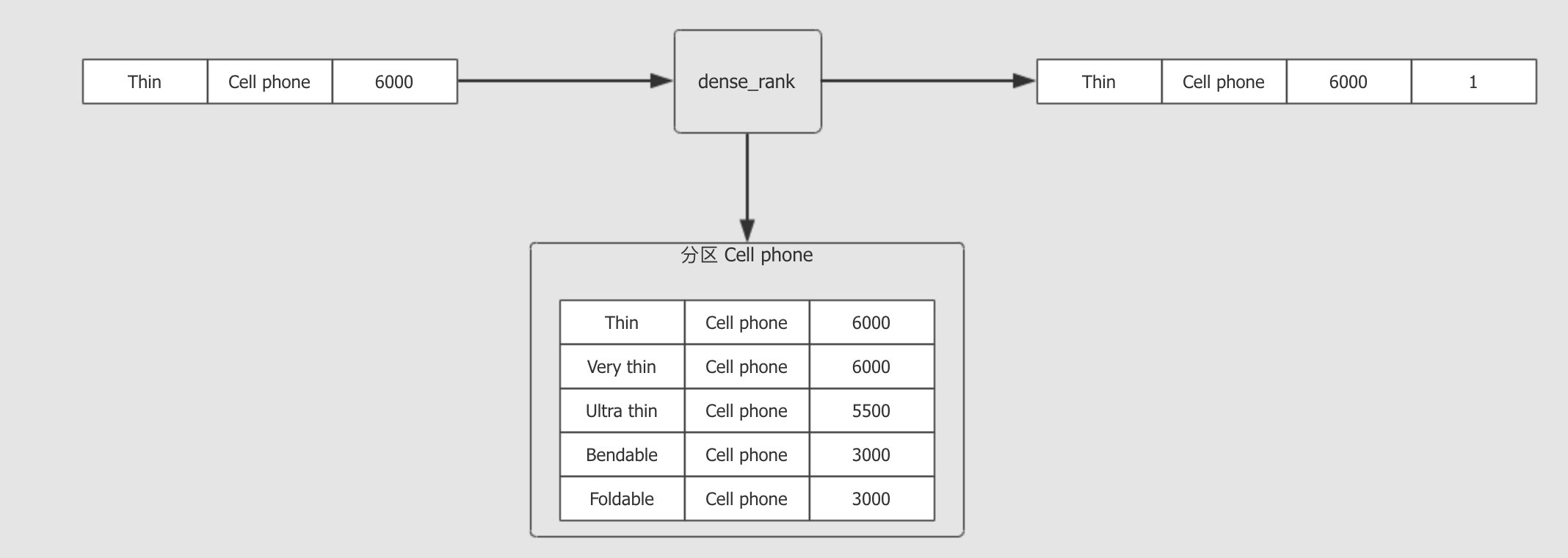
-
- 从语法的角度上讲, 窗口函数大致分为两个部分
-
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank-
函数部分
dense_rank() -
窗口定义部分
PARTITION BY category ORDER BY revenue DESC
-
|
窗口函数和 说白了, 窗口函数其实就是根据当前数据, 计算其在所在的组中的统计数据 |
窗口定义部分
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank-
Partition定义控制哪些行会被放在一起, 同时这个定义也类似于
Shuffle, 会将同一个分组的数据放在同一台机器中处理 -
Order定义在一个分组内进行排序, 因为很多操作, 如
rank, 需要进行排序 -
Frame定义- 释义
-
-
窗口函数会针对 每一个组中的每一条数据 进行统计聚合或者
rank, 一个组又称为一个Frame -
分组由两个字段控制,
Partition在整体上进行分组和分区 -
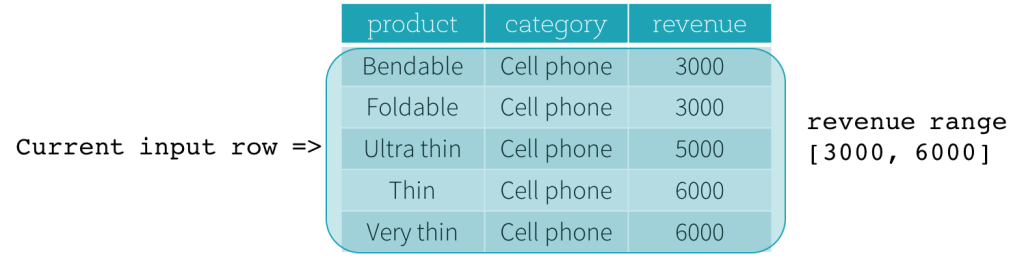
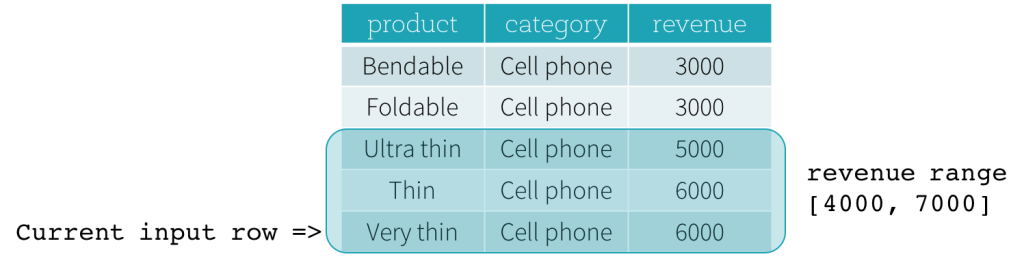
而通过
Frame可以通过 当前行 来更细粒度的分组控制举个栗子, 例如公司每月销售额的数据, 统计其同比增长率, 那就需要把这条数据和前面一条数据进行结合计算了
-
- 有哪些控制方式?
-
-
Row Frame通过
"行号"来表示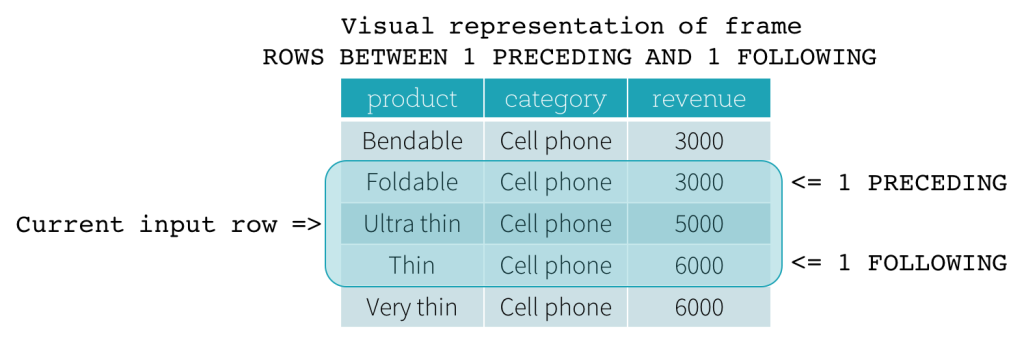
-
Range Frame通过某一个列的差值来表示

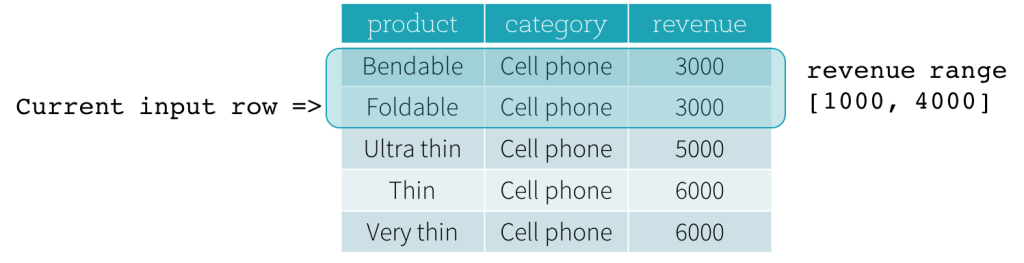

-
函数部分
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank如下是支持的窗口函数
| 类型 | 函数 | 解释 |
|---|---|---|
|
排名函数 |
|
 |
|
|
 |
|
|
|
 |
|
|
分析函数 |
|
获取这个组第一条数据 |
|
|
获取这个组最后一条数据 |
|
|
|
|
|
|
|
|
|
|
聚合函数 |
|
所有的 |
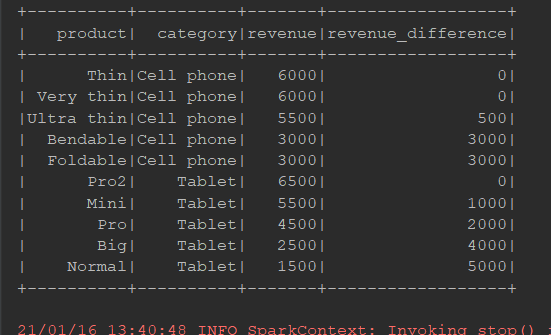
每个商品和他的最高价之间的差值:
package cn.itcast.spark.sql import org.apache.spark.sql import org.apache.spark.sql.SparkSession import org.apache.spark.sql.expressions.Window object WindowFun1 { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("window") .master("local[6]") .getOrCreate() import spark.implicits._ import org.apache.spark.sql.functions._ val data = Seq( ("Thin", "Cell phone", 6000), ("Normal", "Tablet", 1500), ("Mini", "Tablet", 5500), ("Ultra thin", "Cell phone", 5500), ("Very thin", "Cell phone", 6000), ("Big", "Tablet", 2500), ("Bendable", "Cell phone", 3000), ("Foldable", "Cell phone", 3000), ("Pro", "Tablet", 4500), ("Pro2", "Tablet", 6500) ) val source = data.toDF("product", "category", "revenue") // 1. 定义窗口, 按照分类进行倒叙排列 val window = Window.partitionBy('category) .orderBy('revenue.desc) // 2. 找到最贵的的商品价格 val maxPrice: sql.Column = max('revenue) over window // 3. 得到结果 source.select('product, 'category, 'revenue, (maxPrice - 'revenue) as "revenue_difference") .show() } }