
论文源址:https://arxiv.org/abs/1705.06820
tensorflow(github): https://github.com/HongyangGao/PixelDCN
基于PixelDCL分割实验:https://github.com/fourmi1995/IronsegExperiment-PixelDCL
摘要
反卷积被广泛用于深度学习的上采样过程中,包括语义分割的编码-解码网络与无监督学习的深度生成网络。反卷积的一个缺点是生成的特征图类似于棋盘状,相邻元素之间的关系无法较好的确定。为解决此问题,该文提出PixelDCL层,用于建立上采样输出的feature map中相邻像素之间的联系。该文对常规的反卷积进行重新解释。该网络可以应用于其他网络中,同时,并不会增加网络学习的参数量,其分割性能在准确率上会有所损失,但可以通过一些调参技巧进行克服。实验发现PixelDCL层相比常规的反卷积层,可以获得更多的形状及边等空间信息,进而得到更好的分割效果。
说明
通过反卷积实现上采样得到的feature map可以看作是通过独立的卷积核对多个隐藏层的feature map阶段性混合运算的结果。因此,feature map中相邻像素之间没有直接联系,从而产生“棋盘”问题。针对此问题,该文提出Pixel DCL层神经网络层,在这一层网络中的feature map是连续生成的,因此,后面生成的feature map依赖于先前生成的feature map,通过这种方式,建立起相邻像素之间直接联系.PixelDCL与基于概率密度评估的自恢复方法(PixelRNNs,PixelCNNs)相比,训练速度要快很多。虽然在PixelDCL中会有部分计算性能上的降低,但可以通过调参等技巧进行改善。

方法
反卷积:1D,2D卷积图如下,标准的反卷积操作可以分解为几个依赖于上采样因子的卷积操作。本文默认上采样因子为2。
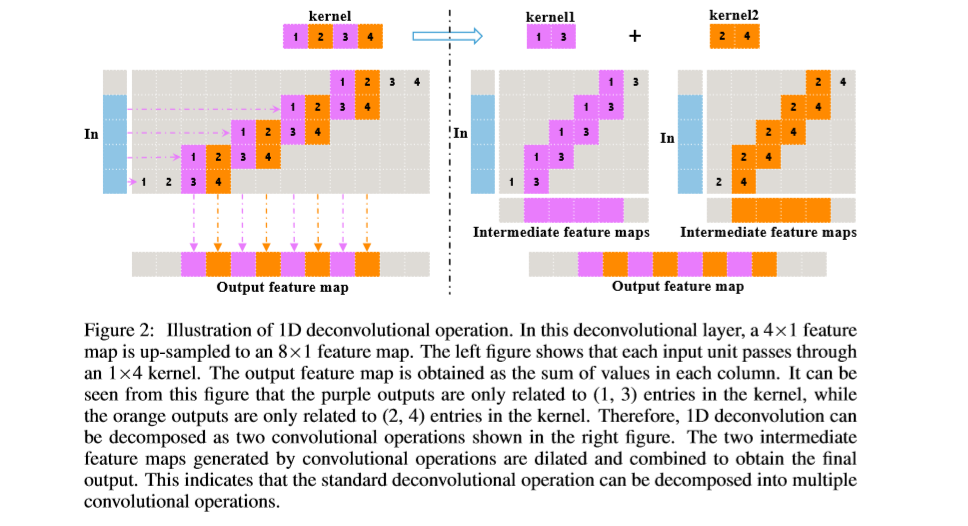

通过如下操作可以计算得到上采样的输出,
![]()
 代表卷积操作,
代表卷积操作,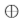 代表阶段性的混搭操作,在常规的反卷积中,由于中间的feature map是由独立的卷积核得到的,因此中间过程的feature map像素中没有直接关联的信息。由于,相邻两个像素可能来自不同的卷积核的结果,因此,像素值会有所不同,进而会产生“棋盘”现象。如下图,通过后处理的方法进行平滑操作会造成额外的计算资源的消耗,增加网络的复杂度,同时无法进行end-to-end的训练。该文通过添加PixelDCL层给中间隐层feature map添加依赖信息。
代表阶段性的混搭操作,在常规的反卷积中,由于中间的feature map是由独立的卷积核得到的,因此中间过程的feature map像素中没有直接关联的信息。由于,相邻两个像素可能来自不同的卷积核的结果,因此,像素值会有所不同,进而会产生“棋盘”现象。如下图,通过后处理的方法进行平滑操作会造成额外的计算资源的消耗,增加网络的复杂度,同时无法进行end-to-end的训练。该文通过添加PixelDCL层给中间隐层feature map添加依赖信息。
 像素级反卷积层:
像素级反卷积层:
由于常规反卷积操作得到的feature map中相邻像素来自不同卷积核得到的feature map,之间并无关联,该文提出PixelDCL,用于建立不同中间隐层特征的关联。中间隐层特征图是按序列生成,而不是同时生成。后一个feature map的生成依赖与上一个feature map的生成。PixelDCL的操作过程如下
后期生成的feature map可以依赖于前面部分或者全部的feature maps。
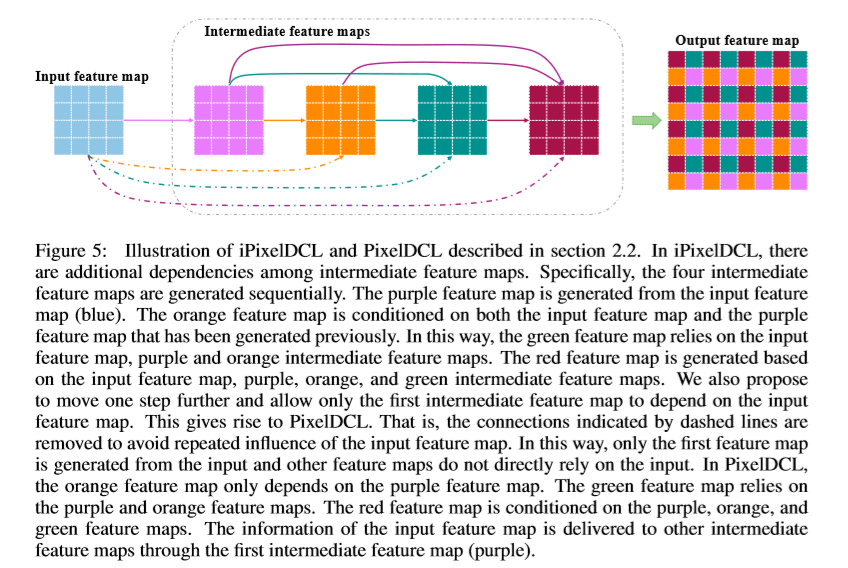
由于输入的feature map被重复利用,降低了计算的性能。因此,进行改进,使输入的feature map只与第一个feature map相关。操作过程如下:

像素级反卷积网络:

实验
图像分割


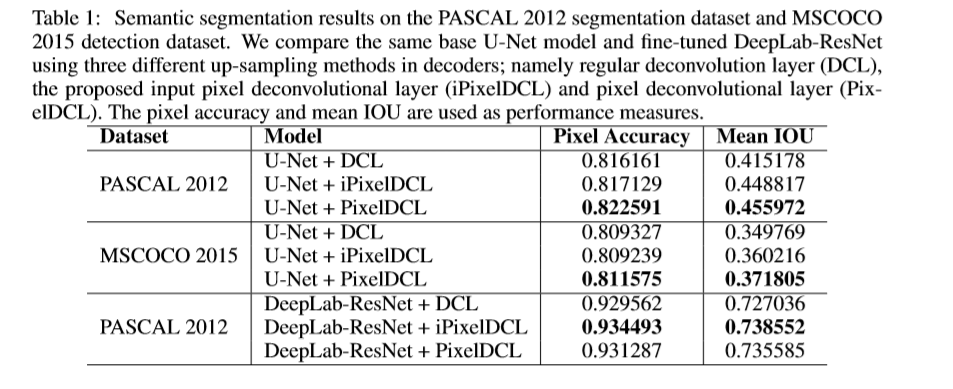
图像生成

时间比较

Reference
[1] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv:1606.00915, 2016.
[2] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2): 303–338, 2010.
[3] Mathieu Germain, Karol Gregor, Iain Murray, and Hugo Larochelle. Made: Masked autoencoder for distribution estimation. In Proceedings of The 32nd International Conference on Machine Learning, pp. 881–889, 2015.