| 这个作业属于哪个课程 | 2020春|S班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 1.学习使用git和github 2.代码规范制定 3.对程序进行单元测试和覆盖率测试 4.对程序进行性能分析和优化 5.学习《构建之法》 |
| 作业正文 | Github仓库地址 |
| 其他参考文献 | 阿里巴巴Java开发手册 github fork 与pull request .gitignore配置语法完全版 单元测试 |
2、PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 1030 | 1105 |
| Analysis | 需求分析 (包括学习新技术) | 100 | 120 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 50 |
| Design | 具体设计 | 40 | 40 |
| Coding | 具体编码 | 580 | 600 |
| Code Review | 代码复审 | 100 | 100 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 190 | 160 |
| Test Repor | 测试报告 | 100 | 90 |
| Size Measurement | 计算工作量 | 30 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 50 |
| 合计 | 1250 | 1305 |
3、解题思路
3.1日志文件的处理
日志文件的结构如图所示
福建 新增 感染患者 23人
福建 新增 疑似患者 2人
浙江 感染患者 流入 福建 12人
湖北 疑似患者 流入 福建 2人
安徽 死亡 2人
新疆 治愈 3人
福建 疑似患者 确诊感染 2人
新疆 排除 疑似患者 5人
// 该文档并非真实数据,仅供测试使用
该日志中出现以下几种情况:
1、<省> 新增 感染患者 n人
2、<省> 新增 疑似患者 n人
3、<省1> 感染患者 流入 <省2> n人
4、<省1> 疑似患者 流入 <省2> n人
5、<省> 死亡 n人
6、<省> 治愈 n人
7、<省> 疑似患者 确诊感染 n人
8、<省> 排除 疑似患者 n人
在读取日志文件的时候,一次读取日志文件的一行,因为每行的字段都用空格隔开,可以调用split函数将这些字段分开,然后按照这些字段来判断是哪个省份,需要对数据进行何种操作。遇到注释行则跳过。
3.2对指令的处理
list命令 支持以下命令行参数:
-
-log指定日志目录的位置,该项必会附带,请直接使用传入的路径,而不是自己设置路径 -
-out指定输出文件路径和文件名,该项必会附带,请直接使用传入的路径,而不是自己设置路径 -
-date指定日期,不设置则默认为所提供日志最新的一天。你需要确保你处理了指定日期以及之前的所有log文件 -
-type可选择[ip: infection patients 感染患者,sp: suspected patients 疑似患者,cure:治愈 ,dead:死亡患者],使用缩写选择,如-type ip表示只列出感染患者的情况,-type sp cure则会按顺序【sp, cure】列出疑似患者和治愈患者的情况,不指定该项默认会列出所有情况。 -
-province指定列出的省,如-province 福建,则只列出福建,-province 全国 浙江则只会列出全国、浙江
-log指令和-out是必须的,-type和-province可以有多个命令参数
需要读取-log的命令参数,然后判断是否存在该目录,若不存在则应该报错。读取-out的命令参数,判断是否存在,若存在则重写该文件,若不存在则创建该文件,可用正则表达式判断-out的命令参数是否合法。-type参数后面跟一个日期,若有这个参数,则要计算该日期是否超过日志文件中最晚的一天,若超过则需要报错,因此需要引入日期类,这样方便比较所有日志文件的日期,求出最晚的一天。-type参数按照先后顺序存入list,等输出疫情的时候按照list里的先后顺序进行输出。
3.3设计地区类
基于面向对象的思想,在实现疫情统计的项目时,应该自定义一个地区类,包含四个int类型数据记录该地区感染患者、疑似患者、治愈、死亡的数量,除此之外还要设置一个boolean类型的变量,来记录是否要输出该地区的疫情信息,此外,为该类写各种方法,例如增加感染患者、排除疑似患者等。
3.4设计算法
因为最后需要按照字母顺序输出省份的情况。先按照指定顺序写好String [] areas

然后按照这些字符串作为key,Area实例作为value写入一个hashMap,最后输出疫情信息的时候,用一个for循环,按照areas的顺序作为键值访问每个value,按实例中的boolean变量判断该省份是否输出,这样就能做到输出的省份一定是按字母顺序
3.5文件读写
用BufferedReader来读日志文件,一次读一行,用OutputStreamWriter来写文件,都必须用UTF-8编码
4、设计实现过程

5、代码说明
用简单的求最大值方法求日志文件中最晚的一天
public static Date getLatestDate(File directory)//获取日志文件中最晚的一天日期
{
File[] logs = directory.listFiles();
Date latestDate = getLogDate(logs[0].getName());
for (int i=1,length=logs.length;i<length;i++)//求出日志中最晚的一天
{
Date temp = getLogDate(logs[i].getName());
if (temp.compareTo(latestDate)>0)
{
latestDate = temp;
}
}
return latestDate;
}
指令分析,用if语句分析判断各种参数类型
for (int i=0,length=args.length;i<length;i++)
{
if (args[i].equals("-log"))//-log参数
{
logPath = args[i+1];
directory = new File(logPath);
if (!directory.isDirectory())
{
System.out.println("日志文件错误或不存在日志文件");
System.exit(1);
}
i++;
}
else if (args[i].equals("-out"))//-out参数
{
outputPath = args[i+1];
output = new File(outputPath);
if (!output.exists())//如果输出文件不存在则创建它
{
try
{
output.createNewFile();
}
catch (IOException e)
{
// TODO Auto-generated catch block
System.out.println("输出文件路径错误");
System.exit(1);
}
}
i++;
}
else if (args[i].equals("-date"))//-date参数
{
dateString = args[i+1];
try
{
int year = Integer.parseInt(dateString.substring(0, 4));
int month = Integer.parseInt(dateString.substring(5, 7));
int day = Integer.parseInt(dateString.substring(8,10));
date = new Date(year-YEAR_GAP, month-MONTH_GAP, day);
}
catch(StringIndexOutOfBoundsException e)
{
System.out.println("-date参数错误");
System.exit(1);
}
i++;
}
else if (args[i].equals("-type"))//-type参数
{
setType = true;
}
else if (Arrays.asList(types).contains(args[i]))
{
if (setType == true)
{
type.add(args[i]);
}
else
{
System.out.println("请使用-type参数");
System.exit(1);
}
}
else if (args[i].equals("-province"))//-province参数
{
setProvince = true;
}
else if (Arrays.asList(areas).contains(args[i]))
{
if (setProvince == true)
{
map.get(args[i]).setIsRelate();
}
else
{
System.out.println("请使用-province参数");
System.exit(1);
}
}
else if (args[i].equals("全国"))
{
if (setProvince == true)
{
setCountry = true;
}
else
{
System.out.println("请使用-province参数");
System.exit(1);
}
}
else
{
if (!args[i].equals("list"))
{
System.out.println("无法识别参数:"+args[i]);
System.exit(1);
}
}
}
输出各省的疫情,只要areas数组中的顺序是正确的,则输出的省份一定是按照字母顺序
static String [] areas = {"安徽","北京","重庆","福建","甘肃","广东","广西","贵州",
"海南","河北","河南","黑龙江","湖北","湖南","吉林","江苏","江西","辽宁",
"内蒙古","宁夏","青海","山东","山西","陕西","上海","四川","天津","西藏",
"新疆","云南","浙江",};
for (int i=0,length=areas.length;i<length;i++)
{
if (map.get(areas[i]).getIsRelate()==true)
{
bufferedWriter.write(areas[i]);
for (String item : type)
{
bufferedWriter.write(map.get(areas[i]).outputType(item));
}
bufferedWriter.write("
");
}
}
6、单元测试
6.1感染患者流动函数
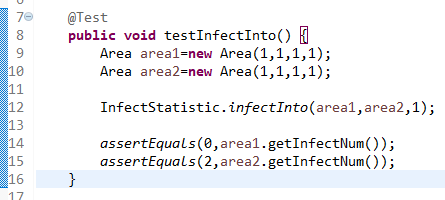
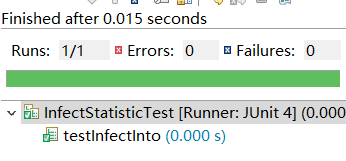
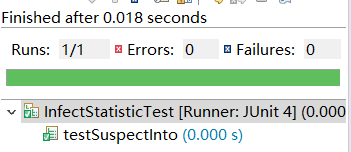
6.2疑似患者流动函数

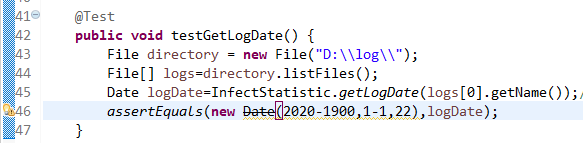
6.3获取日期函数
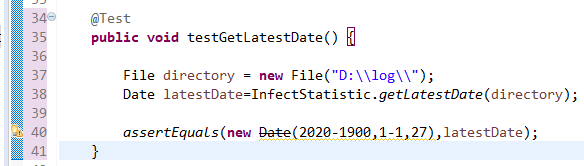
6.4获取日志文件日期最晚一天
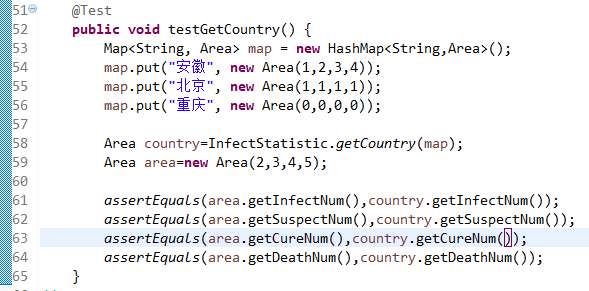
6.5统计全国疫情
6.6 10个测试用例
6.6.1 list -log D:log -out D:output1.txt
统计全部日志中所涉及的省份的所有疫情


6.6.2 list -log D:log -out D:output2.txt -date 2020-01-22
统计到2020年1月22日所涉及的省份的所有疫情


6.6.3 list -log D:log -out D:output3.txt -date 2020-01-25
统计到2020年1月25日所涉及的省份的所有疫情


6.6.4 list -log D:log -out D:output2.txt -date 2020-01-27
统计到2020年1月27日所涉及的省份的所有疫情


6.6.5 list -log D:log -out D:output5.txt -type cure ip
统计所有日志文件中所涉及的省份的治愈人数和感染人数


6.6.6 list -log D:log -out D:output6.txt -province 福建
统计所有日志文件中福建的所有疫情


6.6.7 list -log D:log -out D:output7.txt -province 福建 云南
统计所有日志文件中福建和云南的所有疫情



6.6.8 list -log D:log -out D:output8.txt -province 全国 浙江
统计所有日志文件中全国和浙江的所有疫情


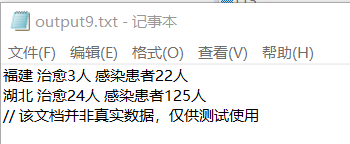
6.6.9 list -log D:log -out D:output9.txt -type cure ip -province 福建 湖北
统计所有日志文件中福建和湖北的治愈人数和感染人数

6.6.10 list -log D:log -out D:output10.txt -date 2020-01-27 -type cure ip -province 全国 福建 湖北
统计到1月27日为止中全国、福建、湖北的治愈人数和感染人数



7、覆盖率优化,性能优化
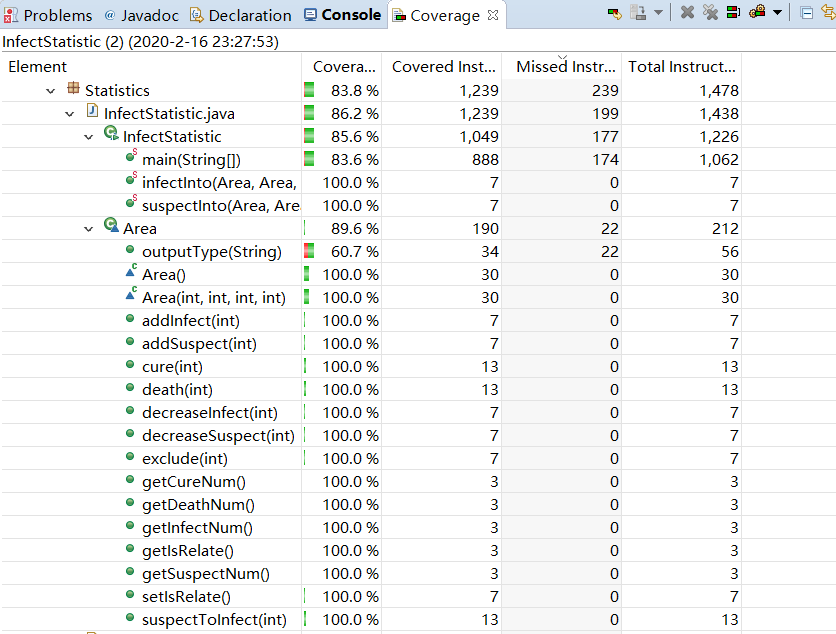
7.1优化前
先来看看现在的程序执行情况
覆盖率:
内存:
其他性能:

7.2 优化过程
循环中可以重复用对象应移到循环外
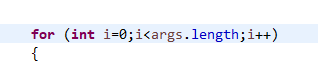
改成

map应当利用areas用循环添加key和value

改成

7.3优化后
覆盖率提高:
内存占用优化:


8、代码规范(codestyle.md)
9、心路历程与收获
本次的项目开发让我受益匪浅,在这个过程中,我阅读了《构建之法》前三章的内容,结合本次项目开发,从中我明白了自己还有许多不足,让我体会到一个项目开发的整个过程是如何进行的。用PSP的各个阶段来看,项目开发主要分三个过程:计划、开发、报告。在计划的时候要先明确需求和其他因素,估计各个任务需要多少时间,开发过程包括需求分析(包括学习新技术、新公会局的时间)、生成设计文档、设计复审 (和同事审核设计文档)、代码规范 (为目前的开发制定合适的规范)、具体设计、 具体编码、 代码复审、测试(自我测试,修改代码,提交修改),报告包括测试报告、计算工作量、 事后总结, 并提出过程改进计划。项目开发的过程不是一个单纯的敲代码的过程,如果不提前做好准备,比如需求分析、设计就直接敲代码,很可能导致代码混乱,逻辑不清晰,漏洞百出。因此要系统的学习软件工程,才能在将来的工作中做好本职工作,发挥作用。除此之外,还要懂得如何对项目进行覆盖率测试、性能优化。
在今后的工作中,我们进行项目开发,总会遇到这种高中低层次的问题。一些程序员非常想做高层次的“科研”,觉得“工程”是基础,没意思。从科研或者理论的高度上说,所有的“技能”都能总结成简单的“已经知道怎么做了”。但是往往就是因为忽略了低层次的问题,才会导致高层次的崩溃,所以,我们要通过不断地练习,把哪些低层次的问题都解决了,变成不用经过大脑的自动操作,然后才有时间和脑力来解决较高层次的问题。

10、技术路线图相关仓库
Java的学习之路,学习JavaEE以及框架时候的一些项目,结合博客和源码,适合Java初学者和刚入门开始学框架者
javaweb学习资料,包含html/css/javascript/xml/servlet/jsp/mysql/jdbc/mvc等内容。当然里面包含所有内容的源代码以及总结的知识点。里面也有大量的工具类,纯粹是为了以后复习以及工作中直接搬代码使用的。也有一些示例demo。
本项目基于 MyBatis Plus 进行定制,利用其提供的代码生成器快速生成模板代码。基本上只要从开始生成到启动运行访问/user/list, /user/get/1等接口。
JSP入门实战项目,这个简单网站使用了javabean+JSP+servlet+mysql(MVC)开发,包含了(1)用户管理:用户注册,登录,头像上传,用户信息显示,注册信息修改,密码修改,退出登录;(2)文章管理:文章列表分页显示,新文章,修改和删除文章。