1.神经网络怎么降维?
问题引入:
降维的算法有很多,那么在神经网络中适如何降维的呢?
问题回答:
神经网络中可以通过autoencoder来实现降维,NN(神经网络)来对数据进行大量的降维是从2006开始的,这起源于science上的一篇文章:reducing the dimensionality of data with neural networks,作者就是鼎鼎有名的Hinton。autoencod一个e的基本结构如下所示,主要包含以及编码器(encoder)和一个解码器(decoder)。这种方法被认为是对PCA的一个非线性泛化方法。
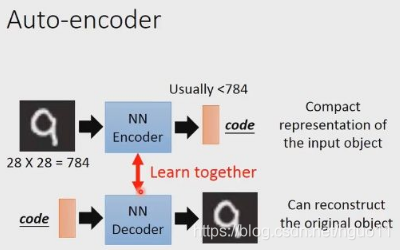
encode和decode两个过程可以理解成互为反函数,在encode过程不断降维,在decode过程提高维度。

2.标准化和归一化有什么区别?
2.1先说是什么,再说为什么:
归一化:就是将训练集中某一列数值特征(假设是第i列)的值缩放到0和1之间。方法如下所示:

标准化
就是将训练集中某一列数值特征(假设是第i列)的值缩放成均值为0,方差为1的状态。如下所示:

归一化和标准化的相同点都是对某个特征(column)进行缩放(scaling)而不是对某个样本的特征向量(row)进行缩放。
在线性代数中,将一个向量除以向量的长度,也被称为标准化,不过这里的标准化是将向量变为长度为1的单位向量,它和我们这里的标准化不是一回事儿,不要搞混(暗坑2)
2.2 标准化和归一化的对比分析
首先明确,在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的。我总结原因有两点:
- 1、标准化更好保持了样本间距。当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。如果不幸的是1和2的分类标签还是相反的,那么,当我们用梯度下降来做分类模型训练时,模型会需要更长的时间收敛,因为将样本分开需要更大的努力!而标准化在这方面就做得很好,至少它不会将样本“挤到一起”。
- 2、标准化更符合统计学假设
对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是略施小技,将这个正态分布调整为均值为0,方差为1的标准正态分布而已。
2.3逻辑回归必须要进行标准化吗?
我觉得,回答完上面的问题,就可以很好地掌握标准化在机器学习中的运用。首先,请尝试自己来回答一下,在评论中告诉我你的答案。
(暂停5秒)
无论你回答必须或者不必须,你都是错的!!!哈哈。
真正的答案是,这取决于我们的逻辑回归是不是用正则。
如果你不用正则,那么,标准化并不是必须的,如果你用正则,那么标准化是必须的。(暗坑3)
为什么呢?
因为不用正则时,我们的损失函数只是仅仅在度量预测与真实的差距,加上正则后,我们的损失函数除了要度量上面的差距外,还要度量参数值是否足够小。
而参数值的大小程度或者说大小的级别是与特征的数值范围相关的。举例来说,我们用体重预测身高,体重用kg衡量时,训练出的模型是:
身高 = 体重*x ,其中x就是我们训练出来的参数。
当我们的体重用吨来衡量时,x的值就会扩大为原来的1000倍。
在上面两种情况下,都用L1正则的话,显然对模型的训练影响是不同的。
假如不同的特征的数值范围不一样,有的是0到0.1,有的是100到10000,那么,每个特征对应的参数大小级别也会不一样,在L1正则时,我们是简单将参数的绝对值相加,因为它们的大小级别不一样,就会导致L1最后只会对那些级别比较大的参数有作用,那些小的参数都被忽略了。
如果你回答到这里,面试官应该基本满意了,但是他可能会进一步考察你,如果不用正则,那么标准化对逻辑回归有什么好处吗?
答案是有好处,进行标准化后,我们得出的参数值的大小可以反应出不同特征对样本label的贡献度,方便我们进行特征筛选。如果不做标准化,是不能这样来筛选特征的。
答到这里,有些厉害的面试官可能会继续问,做标准化有什么注意事项吗?
最大的注意事项就是先拆分出test集,不要在整个数据集上做标准化,因为那样会将test集的信息引入到训练集中,这是一个非常容易犯的错误!
2.5归一化的应用场景
有时候,我们必须要特征在0到1之间,此时就只能用归一化。有种svm可用来做单分类,里面就需要用到归一化,由于没有深入研究,所以我把链接放上,感兴趣的可以自己看。
归一化应用
3.为什么归一化能加快梯度下降法求优化速度?
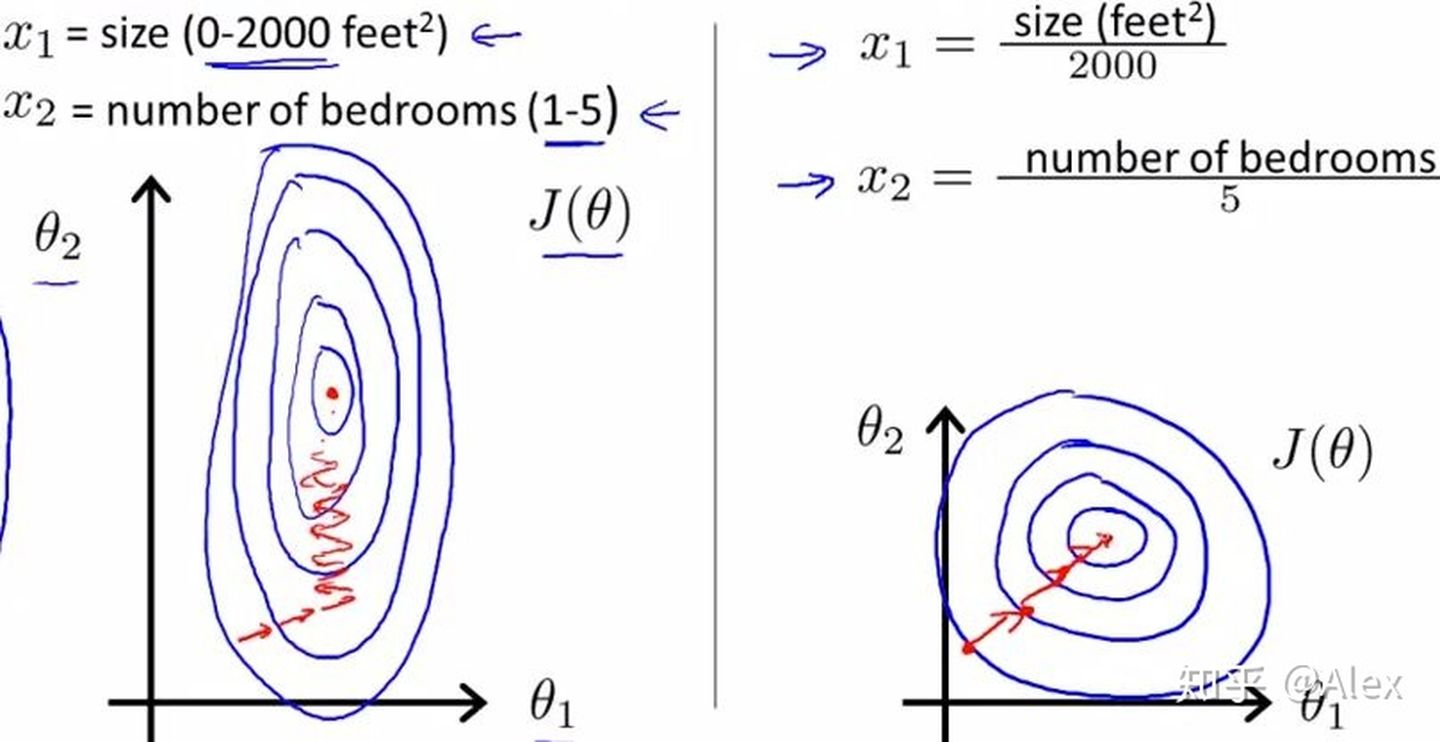
简单的答案是:归一化后的数据有助于在求解是缓解求解过程中的参数寻优的动荡,以加快收敛。对于不归一化的收敛,可以发现其参数更新、收敛如左图,归一化后的收敛如右图。
可以看到在左边是呈现出之字形的寻优路线,在右边则是呈现较快的梯度下降。
4.简单说下 Adaboost?
Adaboost是一种基于Boosting算法,Boosting算法是将“弱学习算法“提升为“强学习算法”的过程。一般来说,找到弱学习算法要相对容易一些,然后通过反复学习得到一系列弱分类器,组合这些弱分类器得到一个强分类器.
简单来说,就是加法模型(组合基分类器)+前向分布算法(一个接一个训练基分类器)。
在Adaboost中的体现主要如下:
1. 设计基分类器。你可以根据所处理数据的特点选择弱分类器,决策树、KNN、Logistic回归方法等等都可以作为弱分类器。一般来说,作为弱分类器,简单的分类器效果会更好一些。
2. 训练基分类器。一开始,训练数据集中的样本权重初始化为相等值。训练过程中,某个样本分类如果被分错了,则它在下一个训练数据集中的权重增加;
反之,分对了,它的权值就降低。权值更新后,样本集用于下一个基分类器的训练,如此迭代,直至达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
(注意:训练数据集的样本值在每一轮中都是不变的,变的是这些样本的权重)
3. 组合基分类器。训练结束后,将各个弱分类器组合成强分类器。组合的方法是,根据每个弱分类器的误差率,加权相加。即误差率小的弱分类器分配个较大权重,误差率大的弱分类器分配个较小的权重。
5.SVM 和 LR 区别和联系?
5.1LR和SVM的相同点
(1)LR和SVM都是分类算法
(2)如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的。
这里要先说明一点,那就是LR也是可以用核函数的,至于为什么通常在SVM中运用核函数而不在LR中运用 。
总之,原始的LR和SVM都是线性分类器,这也是为什么通常没人问你决策树和LR什么区别,决策树和SVM什么区别,你说一个非线性分类器和一个线性分类器有什么区别?
(3)LR和SVM都是监督学习算法
(4)LR和SVM都是判别模型
5.2LR和SVM的不同点
(1)本质上是Loss Function不同。
- LR的损失函数是cross entropy(交叉熵损失函数):
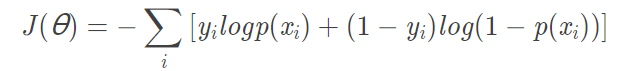
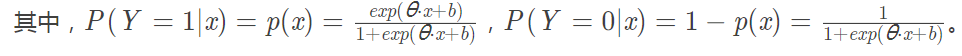
- SVM的损失函数是最大化间隔距离:

不同的Loss Function代表了不同的假设前提,也就代表了不同的分类原理。LR方法基于概率理论,假设样本类别为0或者为1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值。SVM基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面。所以,SVM只考虑分离超平面附近的点,而LR考虑所有点(这也是区别之一),SVM中,在支持向量之外添加减少任何点都对结果没有影响,而LR则是每一个点都会影响决策。
同时可以得出,SVM不直接依赖于数据分布,分离超平面不受一类点影响,而LR则是受所有数据的影响(这也是区别之一),所以受数据本身分别影响。
(2)SVM不能产生概率,LR可以产生概率。
LR本身就是基于概率的,所以它产生的结果代表了分成某一类的概率,而SVM则因为优化的目标不含有概率因素,所以其不能直接产生概率。
(3)SVM依赖于数据的测度,而LR则不受影响。
因为SVM是基于距离的,而LR是基于概率的,所以LR是不受数据不同维度测度不同的影响,而SVM因为要最小化![]()
所以它依赖于不同维度测度的不同,如果差别较大需要做normalization。当然,如果LR要加上正则化,也需要normalization一下。
(4)SVM的损失函数自带正则项,LR则没有。
因为SVM本身就是最小化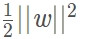 ,所以其优化的目标函数本身就含有正则项,即,结构风险最小化,所以不需要加正则项。而LR不加正则化的时候,其优化的目标是经验风险最小化,所以为了增强模型的泛化能力,通常会在LR损失函数中加入正则化。
,所以其优化的目标函数本身就含有正则项,即,结构风险最小化,所以不需要加正则项。而LR不加正则化的时候,其优化的目标是经验风险最小化,所以为了增强模型的泛化能力,通常会在LR损失函数中加入正则化。
(5)在解决非线性问题时,SVM采用核函数机制,而LR通常不采用核函数的方法。
分类模型的结果就是计算决策面,模型训练的过程就是决策面的计算过程。在计算决策面是,SVM只有少数几个代表支持向量的样本参与了核计算,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
而在LR中,每个样本点都必须参与决策面的计算过程,也就是说,若我们在LR中运用核函数的原理,那么每个样本点都必须参与核计算,这带来的计算复杂度是相当高的。所以,在具体应用时,LR很少运用核函数机制。
(6)SVM适用于小规模数据集,LR适合于大规模数据集。
因为在大规模数据集中,SVM的计算复杂度受到限制,而LR因为训练简单,可以在线训练,所以经常会被大量采用。
6.机器学习中的距离和相似度度量方式有哪些?
在做分类时常常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间的“距离”(Distance)。采用什么样的方法计算距离是很讲究,甚至关系到分类的正确与否。有如下几种:
1. 欧氏距离
2. 曼哈顿距离
3. 切比雪夫距离
4. 闵可夫斯基距离
5. 标准化欧氏距离
6. 马氏距离
7. 夹角余弦
8. 汉明距离
这里无法给出具体的公式,定义是两个等长字符串s1与s2之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。例如字符串“1111”与“1001”之间的汉明距离为2
9. 杰卡德距离 & 杰卡德相似系数
10. 相关系数 & 相关距离