提前导包:
1 import torch 2 from torch import nn, optim 3 from torch.utils.data import DataLoader 4 from torchvision import transforms, datasets 5 6 import visdom
1.自编码器(Auto-Encoder)
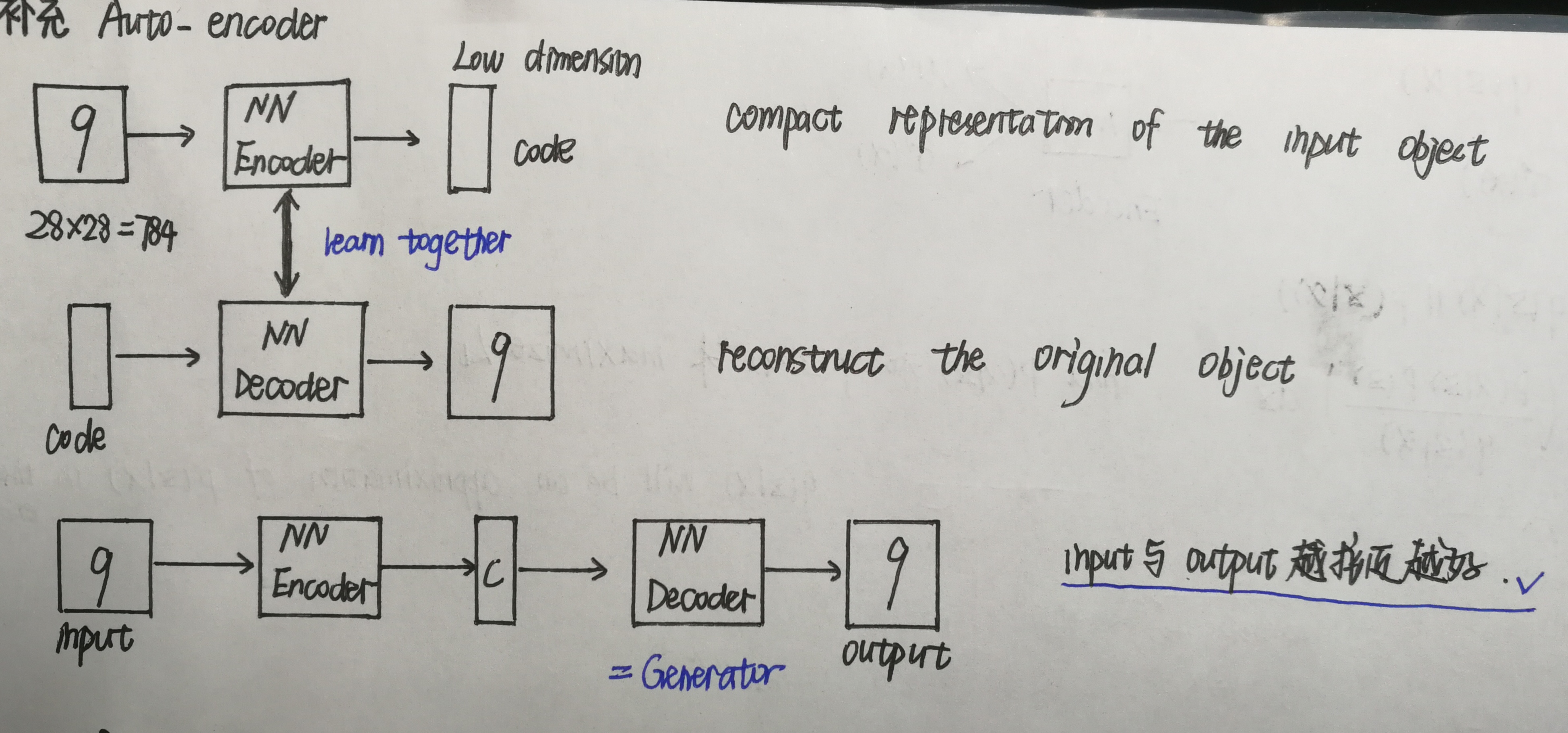
1 class AE(nn.Module): 2 3 def __init__(self): 4 super(AE, self).__init__() 5 6 # [b, 784] => [b, 20] 7 self.encoder = nn.Sequential( 8 nn.Linear(784, 256), 9 nn.ReLU(), 10 nn.Linear(256, 64), 11 nn.ReLU(), 12 nn.Linear(64, 20), 13 nn.ReLU() 14 ) 15 # [b, 20] => [b, 784] 16 self.decoder = nn.Sequential( 17 nn.Linear(20, 64), 18 nn.ReLU(), 19 nn.Linear(64, 256), 20 nn.ReLU(), 21 nn.Linear(256, 784), 22 nn.Sigmoid() 23 ) 24 25 def forward(self, x): #x.shape=[b, 1, 28, 28] 26 27 batchsz = x.size(0) 28 x = x.view(batchsz, 784) #flatten 29 x = self.encoder(x) #encoder [b, 20] 30 x = self.decoder(x) #decoder [b, 784] 31 x = x.view(batchsz, 1, 28, 28) #reshape [b, 1, 28, 28] 32 33 return x, None
2.变分自动编码器(Variational Auto-Encoder)
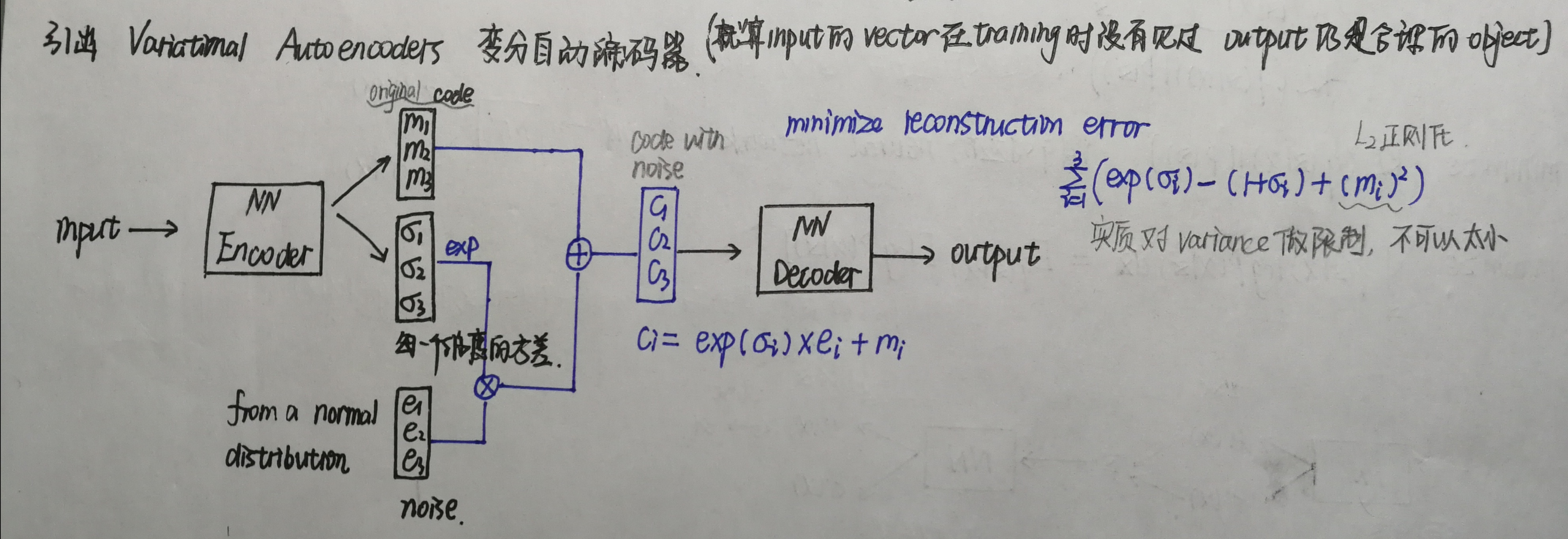
代码中的h和图中的ci,计算方法略有不同,代码中没有用指数。
KL散度计算公式(代码中与sigma相乘的torch.randn_like(sigma)符合正态分布):

1 class VAE(nn.Module): 2 3 def __init__(self): 4 super(VAE, self).__init__() 5 6 # [b, 784] => [b, 20] 7 self.encoder = nn.Sequential( 8 nn.Linear(784, 256), 9 nn.ReLU(), 10 nn.Linear(256, 64), 11 nn.ReLU(), 12 nn.Linear(64, 20), 13 nn.ReLU() 14 ) 15 # [b, 20] => [b, 784] 16 self.decoder = nn.Sequential( 17 nn.Linear(10, 64), 18 nn.ReLU(), 19 nn.Linear(64, 256), 20 nn.ReLU(), 21 nn.Linear(256, 784), 22 nn.Sigmoid() 23 ) 24 25 self.criteon = nn.MSELoss() 26 27 def forward(self, x): #x.shape=[b, 1, 28, 28] 28 29 batchsz = x.size(0) 30 x = x.view(batchsz, 784) #flatten 31 32 h_ = self.encoder(x) #encoder [b, 20], including mean and sigma 33 mu, sigma = h_.chunk(2, dim=1) #[b, 20] => mu[b, 10] and sigma[b, 10] 34 h = mu + sigma * torch.randn_like(sigma) #reparametrize trick, epison~N(0, 1) 35 x_hat = self.decoder(h) #decoder [b, 784] 36 x_hat = x_hat.view(batchsz, 1, 28, 28) #reshape [b, 1, 28, 28] 37 38 kld = 0.5 * torch.sum(mu**2 + sigma**2 - torch.log(1e-8 + sigma**2) - 1) / (batchsz*28*28) #KL散度计算 39 40 return x_hat, kld
3.MINIST数据集上分别调用上面的编码器
1 def main(): 2 mnist_train = datasets.MNIST('mnist', train=True, transform=transforms.Compose([transforms.ToTensor()]), download=True) 3 mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True) 4 5 mnist_test = datasets.MNIST('mnist', train=False, transform=transforms.Compose([transforms.ToTensor()]), download=True) 6 mnist_test = DataLoader(mnist_test, batch_size=32, shuffle=True) 7 8 x, _ = iter(mnist_train).next() #x: torch.Size([32, 1, 28, 28]) _: torch.Size([32]) 9 10 model = AE() 11 # model = VAE() 12 13 criteon = nn.MSELoss() #均方损失 14 optimizer = optim.Adam(model.parameters(), lr=1e-3) 15 print(model) 16 17 viz = visdom.Visdom() 18 19 for epoch in range(20): 20 21 for batchidx, (x, _) in enumerate(mnist_train): 22 23 x_hat, kld = model(x) 24 loss = criteon(x_hat, x) #x_hat和x的shape=[b, 1, 28, 28] 25 26 if kld is not None: 27 elbo = - loss - 1.0 * kld #elbo为证据下界 28 loss = - elbo 29 30 optimizer.zero_grad() 31 loss.backward() 32 optimizer.step() 33 34 print(epoch, 'loss:', loss.item()) 35 # print(epoch, 'loss:', loss.item(), 'kld:', kld.item()) 36 37 x, _ = iter(mnist_test).next() 38 39 with torch.no_grad(): 40 x_hat, kld = model(x) 41 viz.images(x, nrow=8, win='x', opts=dict(title='x')) 42 viz.images(x_hat, nrow=8, win='x_hat', opts=dict(title='x_hat')) 43 44 45 if __name__ == '__main__': 46 main()
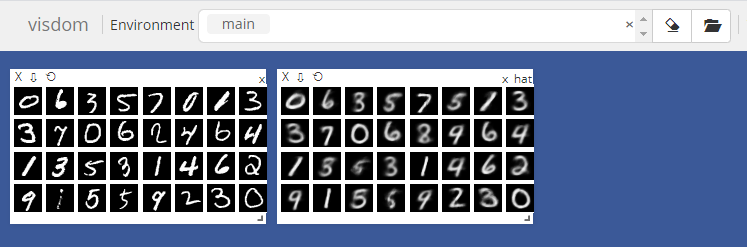
当调用AE时,
0 loss: 0.02397083304822445 1 loss: 0.024659520015120506 2 loss: 0.020393237471580505 3 loss: 0.01954815723001957 4 loss: 0.01639191433787346 5 loss: 0.01630600169301033 6 loss: 0.017990168184041977 7 loss: 0.01680954359471798 8 loss: 0.015895305201411247 9 loss: 0.01704774796962738 10 loss: 0.013867242261767387 11 loss: 0.015675727277994156 12 loss: 0.015580415725708008 13 loss: 0.015662500634789467 14 loss: 0.014532235451042652 15 loss: 0.01624385453760624 16 loss: 0.014668326824903488 17 loss: 0.015973586589097977 18 loss: 0.0157624501734972 19 loss: 0.01488522719591856

当调用VAE时,
0 loss: 0.06747999787330627 kld: 0.017223423346877098 1 loss: 0.06267592310905457 kld: 0.01792667806148529 2 loss: 0.06116900593042374 kld: 0.01845495030283928 3 loss: 0.05097544193267822 kld: 0.0076100630685687065 4 loss: 0.05512534826993942 kld: 0.008729029446840286 5 loss: 0.04558167979121208 kld: 0.008567653596401215 6 loss: 0.04628278315067291 kld: 0.008163649588823318 7 loss: 0.05536432936787605 kld: 0.008285009302198887 8 loss: 0.048810530453920364 kld: 0.009821291081607342 9 loss: 0.046619318425655365 kld: 0.009058271534740925 10 loss: 0.04698382318019867 kld: 0.009476056322455406 11 loss: 0.048784226179122925 kld: 0.008850691840052605 12 loss: 0.05204786732792854 kld: 0.008851360529661179 13 loss: 0.04309754818677902 kld: 0.008809098042547703 14 loss: 0.05094045773148537 kld: 0.008593044243752956 15 loss: 0.04640775918960571 kld: 0.00919229444116354 16 loss: 0.04617678374052048 kld: 0.009322990663349628 17 loss: 0.044559232890605927 kld: 0.00912649929523468 18 loss: 0.04573676362633705 kld: 0.009612892754375935 19 loss: 0.040917910635471344 kld: 0.008869696408510208